上周,Nvidia 宣布 DGX B200 中的 8 个 Blackwell GPU 可以在 Meta 的 Llama 4 Maverick 上展示每个用户每秒 1,000 个代币 (TPS)。今天,同一家独立基准测试公司 Artificial Analysis 测得的 Cerebras 速度超过 2,500 TPS/用户,是 Nvidia 旗舰解决方案性能的两倍多。
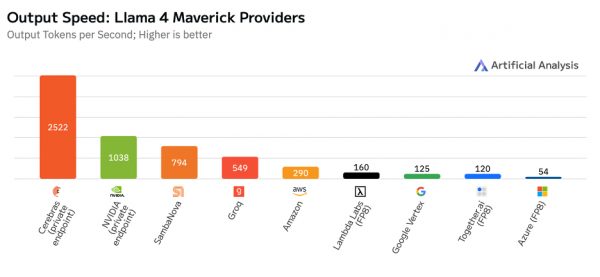
“Cerebras 打破了 NVIDIA 上周创下的 Llama 4 Maverick 推理速度记录,”Artificial Analysis 联合创始人兼首席执行官 Micah Hill-Smith 说。“人工分析以每秒 2522 个令牌的速度对 Cerebras 的 Llama 4 Maverick 终端节点进行了基准测试,而同一型号的 NVIDIA Blackwell 每秒 1038 个令牌。我们已经测试了数十家供应商,Cerebras 是唯一优于 Blackwell 的 Meta 旗舰模型的推理解决方案。
凭借今天的结果,Cerebras 在 400B 参数 Llama 4 Maverick 模型上创下了 LLM 推理速度的世界纪录,该模型是 Llama 4 系列中最大、功能最强大的模型。人工分析测试了其他多家供应商,结果如下:SambaNova 794 t/s、Amazon 290 t/s、Groq 549 t/s、Google 125 t/s 和 Microsoft Azure 54 t/s。
Cerebras Systems 首席执行官 Andrew Feldman 表示:“当今企业中部署的最重要的 AI 应用程序(代理、代码生成和复杂推理)都受到推理延迟的瓶颈。这些使用案例通常涉及多步骤思维链或大规模检索和规划,GPU 上的生成速度低至每秒 100 个令牌,导致等待时间长达几分钟,使生产部署不切实际。Cerebras 率先重新定义了 Llama、DeepSeek 和 Qwen 等模型的推理性能,经常提供超过 2500 TPS/用户。
凭借其创世界纪录的性能,Cerebras 是 Llama 4 在任何部署场景中的最佳解决方案。Cerebras Inference 不仅是第一个也是唯一一个在该模型上打破 2,500 TPS/用户里程碑的 API,而且与人工分析基准测试中使用的 Nvidia Blackwell 不同,Cerebras 硬件和 API 现已推出。Nvidia 使用了大多数用户无法使用的自定义软件优化。有趣的是,Nvidia 的推理提供商都没有提供 Nvidia 公布的性能的服务。这表明,为了实现 1000 TPS/用户,Nvidia 被迫通过批处理大小 1 或 2 来降低吞吐量,使 GPU 的利用率低于 1%。另一方面,Cerebras 在没有任何特殊内核优化的情况下实现了这一破纪录的性能,并且即将通过 Meta 即将推出的 API 服务提供给所有人。
对于推理、语音和代理工作流等尖端 AI 应用程序,速度至关重要。这些 AI 应用程序通过在推理过程中处理更多令牌来获得智能。这也会使他们变慢并迫使客户等待。当客户被迫等待时,他们会离开并转向提供更快答案的竞争对手——这是 Google 十多年前在搜索中展示的发现。
凭借创纪录的性能,Cerebras 硬件和由此产生的 API 服务是全球开发人员和企业 AI 用户的最佳选择。