近日,一项发布于GitHub的研究引发业界热议,该研究的作者认为,华为推出的盘古大模型(Pangu Pro MoE)与阿里巴巴发布的通义千问Qwen-2.5 14B模型在参数结构上存在“惊人一致”。
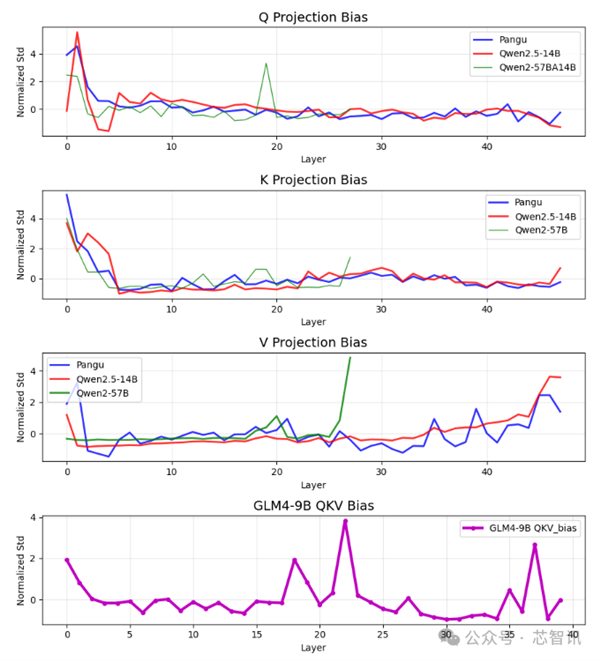
该作者通过实证比较,发现Pangu Pro MoE模型与Qwen-2.5 14B模型在注意力参数分布上的平均相关性高达0.927,远超其他模型对比的正常范围。网友们认为,这可能意味着Pangu Pro MoE存在抄袭。
据悉,盘古大模型团队在GitHub中进行了回应,否认抄袭指控,并且认为该作者的评估方法不科学。
7月5日,诺亚方舟实验室发布声明称,盘古Pro MoE开源模型是基于昇腾硬件平台开发、训练的基础大模型,并非基于其他厂商模型增量训练而来。
一项发布于GitHub的研究认为,盘古团队推出的盘古Pro MoE开源模型与阿里巴巴发布的通义千问Qwen-2.5 14B模型在参数结构上呈现出很高的相似性,两个模型在注意力参数分布上的平均相关性高达0.927,远超其他模型对比的正常范围。
对此,诺亚方舟实验室回应称,盘古Pro MoE开源模型部分基础组件的代码实现参考了业界开源实践,涉及其他开源大模型的部分开源代码。
“我们严格遵循开源许可证的要求,在开源代码文件中清晰标注开源代码的版权声明。这不仅是开源社区的通行做法,也符合业界倡导的开源协作精神。”诺亚方舟实验室表示。
在此次讨论中,有业内分析人士表示,盘古Pro MoE开源模型大概率没有直接使用通义千问Qwen-2.5 14B模型的预训练权重作为初始化参数。两者在偏置的绝对数值分布上存在本质差异,难以通过常规的微调或持续预训练从一个模型状态演变到另一个模型状态。
“这并不排除盘古Pro MoE开源模型与通义千问Qwen-2.5 14B模型在架构设计上具有高度一致性。这种架构和设计理念上的相似性,可能导致了发布于GitHub的研究提到的‘归一化标准差’模式的接近,不过结构上的一致性在大模型上来说并不是什么问题,因为好的结构是大家共同的选择,大模型整体架构都在趋同。”上述分析人士指出。
诺亚方舟实验室提到,盘古Pro MoE开源模型在架构设计、技术特性等方面做了关键创新,是全球首个面向昇腾硬件平台设计的同规格混合专家模型,创新性地提出了分组混合专家模型(MoGE)架构,有效解决了大规模分布式训练的负载均衡难题,提升训练效率。
“我们始终坚持开放创新,尊重第三方知识产权,同时提倡包容、公平、开放、团结和可持续的开源理念。”诺亚方舟实验室表示。
诺亚方舟实验室表示,感谢全球开发者与合作伙伴对盘古大模型的关注和支持,盘古团队高度重视开源社区的建设性意见。希望通过盘古大模型开源,与志同道合的伙伴一起,探索并不断优化模型能力,加速技术突破与产业落地。