中国存储网消息,近日,NVIDIA 推出了 Helix Parallelism,这是一种为其 Blackwell GPU 架构开发的新方法,旨在提高超大型数据集的实时 AI 性能。该技术解决了 LLM 处理数百万个令牌上下文日益增长的需求。NVIDIA 证明,与传统方法相比,这种方法可以将处理速度提高多达 32 倍,从而实现更复杂、响应更迅速的 AI 应用程序。
百万代币挑战:为什么 AI 需要一种新方法
AI 的前沿已经从简单的查询转向复杂的长期推理。高级应用程序非常需要大量的上下文才能有效。记住数月对话的 AI 助手,一次性分析 GB 判例法的法律工具,或理解整个存储库的编码合作伙伴。这些任务需要处理数百万个令牌。
但是,扩展到此级别会暴露出两个基本瓶颈。
- KV 缓存瓶颈:在自回归令牌生成期间,模型会计算对先前生成的令牌的关注,以避免二次缩放因子。为了实现这一点,将缓存以前生成的令牌,这一过程称为 KV 缓存。对于数百万个令牌的上下文,此缓存变得巨大,使 GPU 的内存带宽饱和并显着减慢响应时间。
- FFN 权重瓶颈:对于模型生成的每个新令牌,它必须从内存中加载大量前馈网络 (FFN) 权重。在交互式、低延迟应用程序中,这种持续加载过程成为延迟的主要来源。
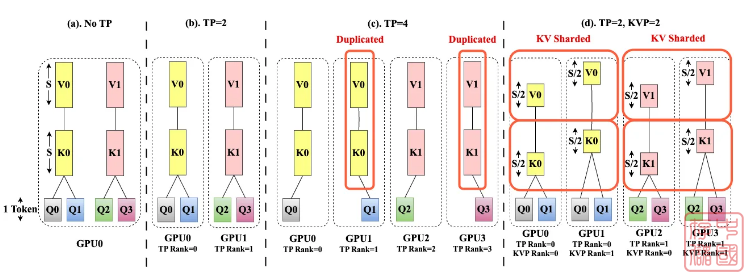
目前,我们依赖于 Tensor Parallelism 等方法,该方法可以拆分模型的张量,从而在多个 GPU 之间拆分所需的内存和计算工作。虽然对某些任务有效,但随着新的注意力机制的出现,它的好处会减少。在 GQA (Grouped Query Attention) 或 MLA (Multi-Latent Attention) 等注意力机制中,为了减少内存使用,多个查询头共享一组较小的 KV 头。但是,当 Tensor Parallelism 大小超过 KV 头的数量时,由于跨 GPU 通信在每一步都会引入显着延迟,因此需要 KV 头复制。这种重复抵消了 Tensor Parallelism 的一些好处。
螺旋平行度
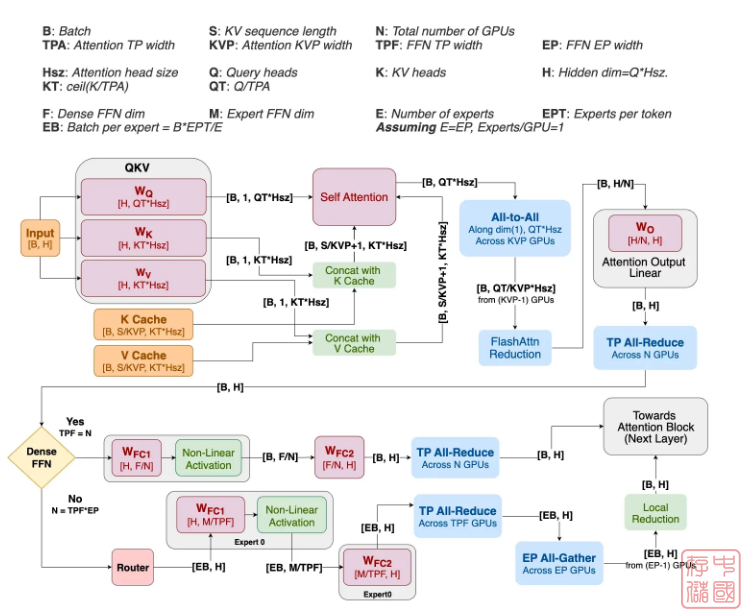
为了解决这个难题,NVIDIA 的 Helix Parallelism 引入了一种混合策略,将两个瓶颈视为单独的问题,需要在无缝的临时管道中解决。Helix 不是对整个过程使用单一并行方法,而是动态重新配置相同的 GPU 池,以便在每个计算阶段使用最佳策略。
对于模型的每一层,该过程可以分为两个主要阶段。
阶段 1:注意力阶段(处理 KV 缓存)
Helix 通过组合两种形式的并行性直接解决 KV 缓存瓶颈。首先,它应用 KV 并行性,沿序列维度在多个 GPU 上对 KV 缓存本身进行分片。这意味着每个 GPU 只保存总上下文的一部分,从而减少了内存负担。
同时,它使用 Tensor Parallelism 对注意力 head 进行切分,确保切分次数不超过 KV heads。这种组合避免了困扰传统 Tensor Parallelism 的缓存重复。结果是 GPU 的 2D 网格,可以在大型环境中有效地计算注意力,而不会让任何一个 GPU 不堪重负。这些 GPU 之间的通信由一个高效的多对多交换处理,其成本与上下文长度无关,因此具有高度可扩展性。
第 2 阶段:FFN 阶段(处理 FFN 权重)
注意力阶段结束时的 all-to-all 通信也会在 GPU 之间对输出数据进行分区。这意味着数据已经完美地安排好了,可以立即开始 FFN 计算。
相同的 GPU 池被重新配置到一个大型 Tensor Parallelism 组中。由于数据是预先分区的,因此每个 GPU 都可以使用其大规模 FFN 权重分片执行本地矩阵乘法。这种初始计算是并行进行的,没有跨 GPU 通信,从而最大限度地提高了速度。只有在这个本地计算步骤之后, GPU 才会参与高效的 all-reduce 通信,以将其部分结果合并到最终输出中。
最后一块拼图是 Helix 如何在增长时管理 KV 缓存。当模型生成新令牌时,必须将它们附加到缓存中。一种朴素的方法可以通过将所有新令牌写入单个 GPU 来创建内存热点。Helix 通过一个巧妙的循环更新系统来防止这种情况。例如,新令牌的第一个块可能转到 GPU 0,下一个块可能转到 GPU 1,依此类推。这种交错方法可确保 KV Parallelism 组中的所有 GPU 的内存使用量均匀增长,无论上下文大小如何,都能保持平衡的性能和一致的吞吐量。
Blackwell 的新表演前沿
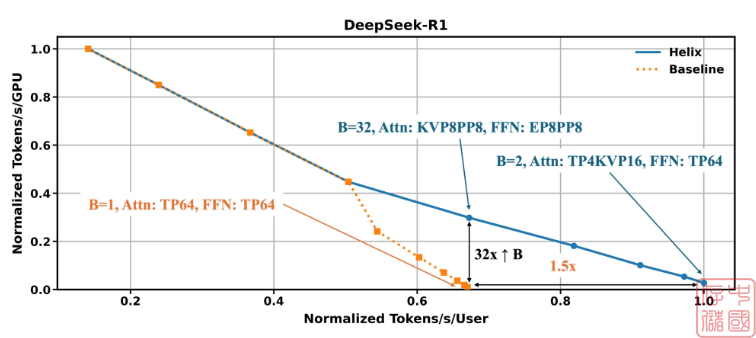
Helix 为长上下文 LLM 解码设定了新的性能基准。结果基于使用 DeepSeek R1 671B 参数模型 (FP4) 对 Blackwell NVL72 进行的详尽模拟,假设有 100 万个令牌上下文,系统地改变分区策略和批处理大小,以找到最佳的吞吐量-延迟权衡。对于需要大规模可扩展性的应用程序,例如同时为多个用户提供服务,Helix 可以在给定的延迟预算下将并发用户数量提高多达 32 倍。对于单用户响应能力至关重要的低并发设置,该技术可以通过减少可实现的最小令牌到令牌延迟,将用户交互性提高多达 1.5 倍。这些增益是通过在所有可用设备上对 KV 缓存和 FFN 权重进行分片来实现的,这大大降低了 DRAM 压力并提高了计算效率。