大数据处理平台为我们更好地综合利用结构化、半结构化、非结构化数据、流数据以及海量数据进行分析提供了坚实的基础。目前,大数据处理技术在互联网企业已经得到了广泛的应用,银行、电信及政府等行业用户也开始逐渐采用大数据处理技术。在大数据技术推广、使用过程中,一个很大的挑战就是如何使用目前企业用户广泛使用的标准 SQL 来访问基于 Hadoop 平台的大数据,使用企业原有应用来访问大数据。
现在,使用大数据技术,通常使用 Hive、Pig 及 Java 程序来访问大数据,只能支持标准 SQL 的子集,需要用户学习新的编程语言,改写企业原有的应用,为了解决上述问题,IBM 推出了 Big SQL,它使用标准的 SQL 来访问基于 Hadoop 平台的 InfoSphere BigInsights,并提供标准的 JDBC、ODBC 接口,可以使广大熟悉 SQL 的用户直接访问大数据,而且,从性能优化角度,Big SQL 提供本地查询及 Map Reduce 两种运行模式,对于小数据集,采用本地查询方式减少 Map Reduce 的运行开销,提高执行效率,对大规模数据,自动采用 Map Reduce 方式高效运行。本文具体介绍了 Big SQL 的体系结构,如何使用 Big SQL 创建、装载及查询 Hive、Hbase 表,以及查询优化的各种方法,希望可以使读者对如何使用 Big SQL 访问大数据有一个比较全面的了解。
我们知道,随着数据规模爆炸式的增长、数据种类不断翻新以及数据处理速度不断加快,大数据处理技术及平台应运而生。大数据处理平台为我们更好地综合利用结构化、半结构化、非结构化数据、流数据以及海量数据进行分析提供了坚实的基础。大数据处理平台主要包括用于静态大数据分析的 Hadoop 平台以及用于流数据处理的流处理平台。Hadoop 大数据处理平台以 Apache Hadoop 为基础,并存在不同的发行版本。IBM InfoSphere BigInsights 是 IBM 的 Hadoop 大数据处理平台,它以 Apache Hadoop 为基础,并增加了大数据处理平台的企业特性,包括集成的安装、管理、开发工具,NameNode、Job Tracker 等组件的高可用,安全性增强,性能的增强,Map/Reduce 处理框架的增强,使用标准的 SQL 访问大数据以及与现有基础设施和大数据流计算技术无缝的集成等,另外,IBM InfoSphere BigInsights 还提供了文本分析、机器学习、数据挖掘、可视化分析等大数据分析能力。目前,Hadoop 大数据处理技术在互联网企业已经得到了广泛的应用,银行、电信及政府等行业用户也开始逐渐采用大数据处理技术。从大数据应用场景角度来看,数据仓库增强是 Hadoop 大数据应用处理的一个非常重要的使用场景。我们知道,数据仓库系统通常会采用高端服务器、高端存储来提供海量数据存储及高效数据处理能力,随着大数据时代到来,数据规模呈爆炸式增长,数据仓库存储及处理成本也会极具增长,为了降低成本,我们可以将数据仓库中的海量历史数据卸载到 Hadoop 平台,利用 Hadoop 平台低廉的成本及 Map/Reduce 并行处理能力提供历史数据的查询、分析能力,并利用传统的数据仓库系统高效处理在线数据。
在大数据技术推广、使用过程中,一个很大的挑战就是如何使用目前企业用户广泛使用的标准 SQL 来访问基于 Hadoop 平台的大数据,使用企业原有应用来访问大数据,特别是数据仓库增强使用场景,我们处理的数据还主要是海量的结构化数据,我们仍然需要使用标准的 SQL 并使用企业原有的程序来访问大数据。目前,使用大数据技术,通常使用 Hive、Pig 及 Java 程序来访问 Hadoop 大数据,需要用户学习新的编程语言,改写企业原有的应用,尽管 Hive QL 提供了 SQL 接口,但它只支持标准 SQL 的子集,不能完全满足应用的需求,为了解决上述问题,IBM 推出了 Big SQL,它使用标准的 SQL 来访问基于 Hadoop 平台的 InfoSphere BigInsights,并提供标准的 JDBC、ODBC 接口,可以使广大熟悉 SQL 的用户直接访问大数据,而且,从性能优化角度,Big SQL 提供本地查询及 Map Reduce 两种运行模式,对小规模数据,采用本地查询方式减少 Map Reduce 的运行开销,提高执行效率,对大规模数据,自动采用 Map Reduce 方式高效运行。
Big SQL 概述
Big SQL 是 IBM 基于 Hadoop 平台 InfoSphere BigInsights 的 SQL 接口,它提供标准的 ANSI SQL 92 标准,允许 SQL 开发人员能够轻松地掌握对 Hadoop 管理的数据的查询。它使数据管理员能够为 Hive、HBase 或他们的 BigInsights 分布式文件系统中存储的数据创建新表。此外,LOAD 命令使管理员能够在 Big SQL 表中填入来自各种来源的数据。此外,Big SQL 提供标准的 JDBC 和 ODBC 驱动程序,可以使许多现有的工具使用 Big SQL 查询分布式数据。这些都解决了 Hive 存在的一些局限,目前,Hive 仅支持 ANSI SQL 的子集,它不支持子查询、窗口函数,仅支持 ANSI JOIN 语法,对数据类型的支持也有局限,目前不支持 varchar、Decimal 数据类型,另外,它对标准的 JDBC 及 ODBC 驱动程序的支持也有局限性。通过使用 Big SQL,可以使广大熟悉 SQL 的用户直接访问大数据。
从性能优化角度,Big SQL 提供 Big SQL 服务器本地查询及 Map Reduce 两种运行模式,对于小数据集或获取与一个特定 HBase 行键关联的数据的查询,通常会在单个节点上顺序执行,减少 Map Reduce 的运行开销,提高执行效率,对大规模数据,自动采用 Map Reduce 方式高效运行。
除此之外,Big SQL 还针对 HBase 处理提供了增强。通过使用 Big SQL,用户不需要使用像 Hive 那样复杂的语句来创建 HBase 表,可以支持创建组合行健、组合字段,可以为 HBase 表创建辅助索引,可以使用 LOAD、insert 语句为 HBase 表装载数据,可以指定压缩方法等。
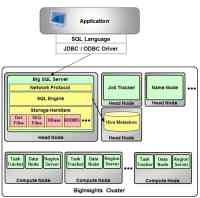
如下图所示,Big SQL 同 Hive 共享元数据定义信息,它通过 Hcatalog 访问 Hive metastore,在 InfoSphere BigInsights 中,Hive metastore 默认采用 Derby 数据库。因此,Big SQL 中的定义的表可以和 Hive 中定义的表互相访问,默认情况下,Big SQL 中创建的表即使 Hive 表。
外部应用通过标准的 JDBC/ODBC 驱动程序访问 Big SQL,Big SQL 的 SQL 查询引擎负责对输入的 SQL 语句进行编译,生成执行计划。它可以通过改写相关的 SQL 语句来提高查询性能,如将子查询改写成表连接操作,并可以通过 SQL 优化提示及配置选项,改变数据访问策略。根据查询的性质、数据量和其他因素,Big SQL 可以使用 Hadoop 的 MapReduce 框架并行处理各种查询任务,或者在单个节点上的 Big SQL 服务器上本地执行您的查询, 也可以部分查询工作在 Hadoop 的 MapReduce 框架上完成,部分查询工作在 Big SQL 服务器上完成。
Big SQL 通过 Hive 存储引擎来读写数据。SQL 查询引擎可以根据不同的数据类型,选择不同的存储管理程序装载不同的数据处理类来读取数据。Big SQL 支持 Delimited files、Sequence files、RC files、Custom、Partitioned tables 等多种数据格式,同时支持 Hive SerDe 提供的各种编码方式,包括 Text、Binary、Avro、Thrift、JSON、Custom。Big SQL 还提供了自己专有的 HBase 存储管理程序,针对 HBase 处理提供了很多增强功能,包括支持字符或二进制不同的编码方式、支持组合行健及组合字段、可以为 HBase 表创建辅助索引等。
图 1. Big SQL 架构
使用 Big SQL
启动 Big SQL 服务
我们需要启动 Big SQL 服务来访问 Big SQL。如下所示,我们以管理员身份 (biadmin) 登录系统,并使用如下命令启动、停止及查询 Big SQL 服务:
清单 1. 启动 Big SQL 服务
|
1
2
3
4
5
6
7
8
9
10
|
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGSQL_HOME/bin/bigsql stop
BigSQL pid 2850313 stopped.
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGSQL_HOME/bin/bigsql start
BigSQL running, pid 2893219.
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGSQL_HOME/bin/bigsql status
BigSQL server is running (pid 2893219)
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGSQL_HOME/bin/bigsql level
IBM BigInsights Big SQL Server Version number is "V2.1.0.1
and level identifier is "20130821".
|
我们也可以使用 BigInsights 本身的集成管理命令来启动、停止及查询 Big SQL 服务,如下所示:
清单 2. 使用集成管理命令启动 Big SQL 服务
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGINSIGHTS_HOME/bin/stop.sh bigsql biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGINSIGHTS_HOME/bin/start.sh bigsql biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGINSIGHTS_HOME/bin/status.sh bigsql
我们还可以使用 BigInsights 本身的集成管理命令来启动 BigInsights 的所有服务,包括 Big SQL 服务,如下所示:
清单 3. 启动 BigInsights 的所有服务
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGINSIGHTS_HOME/bin/stop-all.sh biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGINSIGHTS_HOME/bin/start-all.sh
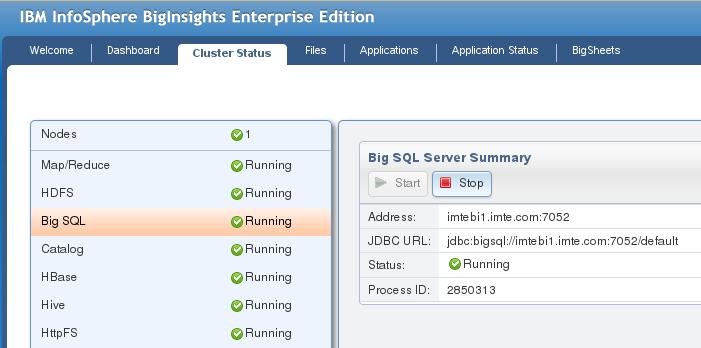
另外,我们还可以通过 BigInsights 提供的 Web Console 管理工具来启动、停止及查询 Big SQL 服务,如下所示:我们通过执行 http://172.16.42.202:8080/ 来启动 BigInsights Console,并选择 Cluster Status 菜单。
图 2. 使用 Web Console 管理 Big SQL 服务
访问 Big SQL
BigInsights 提供多种工具访问 Big SQL,包括:
- JSqsh 命令行方式
- BigInsights console 管理工具
- Big SQL Eclipse plugin
- 通用的 JDBC/ODBC 管理工具
- JDBC/ODBC 应用程序
使用命令行访问 Big SQL
BigInsights 提供一个开源 JDBC 命令行工具 JSqsh 来访问 Big SQL,我们可以执行如下命令来启动 jsqsh 并执行 SQL 查询 ,如下所示:
清单 4. 启动 jsqsh 并执行 SQL 查询
biadmin@imtebi1:/opt/ibm/biginsights/bigsql>$BIGSQL_HOME/bin/jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray Type help for available help topics. Using JLine. [localhost][biadmin] 1> select * from hbase_staff;
我们也可以使用如下命令来运行 Big SQL 脚本,如下所示:
清单 5. 运行 Big SQL 脚本
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> $BIGSQL_HOME/bin/jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql -i GOSALESDW_starSchemaJoin.sql
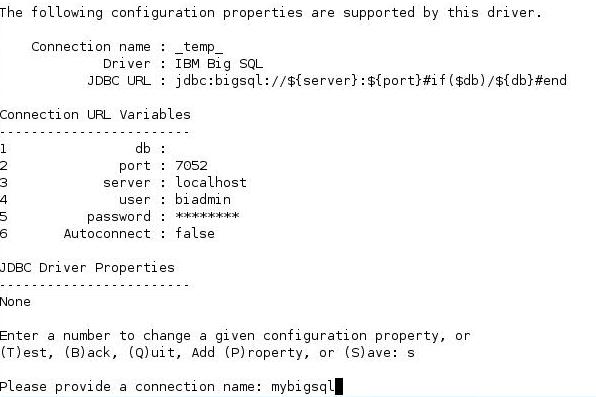
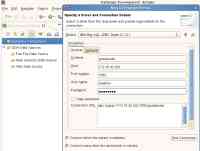
另外,我们还可以使用 jsqsh – setup 命令定义自己的连接环境,如下所示:
清单 6. 定义自己的连接环境
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/bin> ./jsqsh --setup
图 3. 使用 jsqsh – setup 命令定义连接环境
 这样,我们可以使用定义的连接串进入自己的连接环境,如下所示:
这样,我们可以使用定义的连接串进入自己的连接环境,如下所示:
清单 7. 连接自己的环境
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/bin> ./jsqsh mybigsql
使用 Web Console 访问 Big SQL
我们可以通过 BigInsights 提供的 Web Console 管理工具来访问 Big SQL,如下所示:我们通过执行 http://172.16.42.202:8080/ 来启动 BigInsights Console,并选择 Quick Links 中的 Run Big SQL Queries 菜单来运行 Big SQL 查询语句。
图 4. 使用 Web Console 运行 Big SQL 查询

使用 Eclipse 工具访问 Big SQL
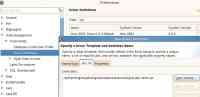
首先,通过执行 http://172.16.42.202:8080/ 来启动 BigInsights Console,并选择 Quick Links 中的 Download the Big SQL Client drivers 来下载 Big SQL client drivers,然后通过执行 /usr/local/eclipse/eclipse/eclipse 命令打开 BigInsights Eclipse 开发工具,选择 Windows 菜单下的 Preferences 菜单,通过选择 Data Management 选项下的 Connectivity->Driver Definitions 来设置 Big SQL Driver,如下所示:
图 5. 为 Eclipse 工具设置 Big SQL Driver
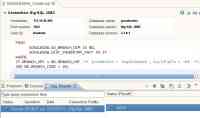
 之后,在 BigInsights Eclipse 开发工具中,打开 Database Development Perspective,在 Data Source Explorer 视图中,选择 Database Connections 选项,点击右键创建 Big SQL JDBC 数据库连接概要,如下图所示:
之后,在 BigInsights Eclipse 开发工具中,打开 Database Development Perspective,在 Data Source Explorer 视图中,选择 Database Connections 选项,点击右键创建 Big SQL JDBC 数据库连接概要,如下图所示:
图 6. 为 Eclipse 工具创建 Big SQL JDBC 数据库连接概要
 之后,我们可以通过创建 BigInsights Project 以及创建 SQL Script 来创建并运行 GOSALESDW_Counts.sql 语句,如下所示:
之后,我们可以通过创建 BigInsights Project 以及创建 SQL Script 来创建并运行 GOSALESDW_Counts.sql 语句,如下所示:
图 7. 使用 Eclipse 工具运行 Big SQL 查询
使用 Db Visualizer 等 JDBC/ODBC 工具访问 Big SQL
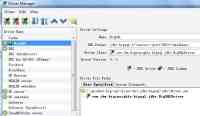
Big SQL 提供标准的 JDBC/ODBC 驱动程序,允许所有支持标准 JDBC/ODBC 的工具访问 BigInsights Hadoop 大数据,这也是 Big SQL 相比 Hive 等大数据查询语言的优势之一。我们以常见的 Db Visualizer 工具为例,首先,我们通过选择 Tools 菜单下的 Driver Manager 菜单来定义 Big SQL Driver,如下所示:
图 8. 为 Db Visualizer 定义 Big SQL Driver
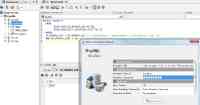
 之后,在 Database 标签下,选择 Connections 选项,点击右键创建 BigSQL 数据库连接,如下所示,连接数据库,并选择 File 菜单下的 New SQL Commander 菜单创建并运行 Big SQL 查询。
之后,在 Database 标签下,选择 Connections 选项,点击右键创建 BigSQL 数据库连接,如下所示,连接数据库,并选择 File 菜单下的 New SQL Commander 菜单创建并运行 Big SQL 查询。
图 9. 使用 Db Visualizer 运行 Big SQL 查询
 点击查看大图
点击查看大图
使用 JDBC/ODBC 程序访问 Big SQL
我们可以使用 JDBC/ODBC 程序来访问 Big SQL,我们以 JDBC 程序为例,详细介绍了使用 JDBC 访问 Big SQL 的具体方法。
首先,我们需要在 CLASSPATH 环境变量中增加 bigsql-jdbc-driver.jar 文件,如下所示:
清单 8. 增加 CLASSPATH 环境变量
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> export CLASSPATH=$CLASSPATH:/opt/ibm/biginsights/bigsql/samples/queries/bigsql-jdbc-driver.jar
并创建 countbrand.java 程序,如下所示:
清单 9. countbrand.java 程序
countbrand.java
import java.io.*;
import java.sql.*;
import java.util.*;
class countbrand {
public static void main(String args[]) throws SQLException,Exception {
try {
//load the driver class
Class.forName("com.ibm.biginsights.bigsql.jdbc.BigSQLDriver");
} catch (ClassNotFoundException e) {
System.out.print(e); }
try {
//set connection properties
String user="biadmin";
String password="password";
Connection con = DriverManager.getConnection("jdbc:bigsql://172.16.42.202:7052/gosalesdw",
user,password);
Statement st = con.createStatement();
//query execution
ResultSet rs = st.executeQuery("SELECT count(*) FROM GOSALESDW.GO_BRANCH_DIM AS BD,
GOSALESDW.DIST_INVENTORY_FACT AS IF WHERE IF.BRANCH_KEY = BD.BRANCH_KEY /*+ joinMethod = 'mapSideHash',
buildTable = 'bd' +*/ AND BD.BRANCH_CODE > 20");
while(rs.next()) {
System.out.println(rs.getString(1));
}
} catch(SQLException sqle)
{ System.out.print(sqle); }
}
}
我们可以使用如下命令编译并运行 countbrand.java 程序,如下所示:
清单 10. 编译并运行 countbrand.java 程序
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> javac countbrand.java biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> java countbrand 33318
创建、加载表
同关系数据库一样,Big SQL 也存在模式。模式是指一组对象的集合,我们可以通过创建不同的模式来组织 Big SQL 中的数据对象。如下所示,我们创建 gosalesdw 模式来组织我们需要创建的 Hive 及 HBase 表。
清单 11. 创建 gosalesdw 模式
biadmin@imtebi1:/opt/> $BIGSQL_HOME/bin/jsqsh -U biadmin -P password JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray Type help for available help topics. Using JLine. [localhost][biadmin] 1> create schema if not exists gosalesdw; 0 rows affected (total: 1m4.56s) [localhost][biadmin] 1> quit; biadmin@imtebi1:/opt/$HADOOP_HOME/bin/hadoop fs -ls /biginsights/hive/warehouse drwxr-xr-x - biadmin biadmgrp 0 2013-12-21 21:20 /biginsights/hive/warehouse/gosalesdw.db
在 Big SQL 中,我们创建的模式会在 DFS 分布式文件系统中创建一个相应的目录,该目录可以在创建模式时指定,如果没有指定目录,会在 Hive 的默认目录 /biginsights/hive/warehouse/ 下创建。我们可以通过修改 $HIVE_HOME/conf/hive-site.xml 文件中的 hive.metastore.warehouse.dir 属性值来修改 Hive 的默认存储路径,如下所示:
清单 12. 修改 hive-site.xml
biadmin@imtebi1:/opt/> $BIGSQL_HOME/bin/jsqsh -U biadmin -P password JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray Type help for available help topics. Using JLine. [localhost][biadmin] 1> create schema if not exists gosalesdw1 location '/usr/biadmin/gosalesdw1.db'; 0 rows affected (total: 0.87s) [localhost][biadmin] 1> quit biadmin@imtebi1:/opt/> $HADOOP_HOME/bin/hadoop fs -ls /usr/biadmin Found 1 items drwxr-xr-x - biadmin supergroup 0 2013-12-21 21:26 /usr/biadmin/gosalesdw1.db more $HIVE_HOME/conf/hive-site.xml hive.metastore.warehouse.dir /biginsights/hive/warehouse
同样,我们创建的每一张表,也会在 DFS 分布式文件系统对应的模式目录下创建一个子目录,向表中装载数据,则会在该子目录下创建一个或多个数据文件,如下所示:
清单 13. DFS 文件系统目录
Big SQL 支持 tinyint、smallint、integer、bigint 整数类型,也支持 float、double、real 浮点类型及 decimal 类型,string、varchar()、char()、binary、varbinary() 字符类型、timestamp 时间类型以及 boolean 布尔类型,其中 tinyint 和 smallint 是等价的,real 和 float 是等价的。另外,Big SQL 也支持 array 数组及 struct 结构复杂数据类型。目前,Big SQL 不支持大对象和 VARGRAPHIC 类型。
Big SQL 不直接指定各个数据类型的具体存储格式,而是由 SerDe 来决定。如果没有特别指定,Big SQL 使用 Hive 默认的 LazySimpleSerDe 及 LazyBinarySerDeSerDe SerDe 定义。由此可见,Big SQL 同 Hive 共享数据。
在 Big SQL 中,创建表主要涉及创建 Hive 表及 HBase 表两种形式,下边我们将具体介绍一下两种创建表及装载表的具体方法。
创建、加载 Hive 表
创建 Hive 表
在 Big SQL 中,没有特别指定,所创建的表默认都是 Hive 表,如下所示,我们创建了 SLS_SALES_FACT、SLS_SALES_ORDER_DIM、SLS_ORDER_METHOD_DIM 三张 Hive 表:
清单 14. 创建 Hive 表
USE GOSALESDW; CREATE TABLE SLS_SALES_FACT ( ORDER_DAY_KEY int, ORGANIZATION_KEY int, EMPLOYEE_KEY int, RETAILER_KEY int, RETAILER_SITE_KEY int, PRODUCT_KEY int, PROMOTION_KEY int, ORDER_METHOD_KEY int, SALES_ORDER_KEY int, SHIP_DAY_KEY int, CLOSE_DAY_KEY int, QUANTITY int, UNIT_COST decimal(19,2), UNIT_PRICE decimal(19,2), UNIT_SALE_PRICE decimal(19,2), GROSS_MARGIN double, SALE_TOTAL decimal(19,2), GROSS_PROFIT decimal(19,2) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't'; CREATE TABLE SLS_SALES_ORDER_DIM ( SALES_ORDER_KEY int, ORDER_DETAIL_CODE int, ORDER_NUMBER int, WAREHOUSE_BRANCH_CODE int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't'; --GOSALESDW.SLS_ORDER_METHOD_DIM CREATE TABLE SLS_ORDER_METHOD_DIM ( ORDER_METHOD_KEY int, ORDER_METHOD_CODE int, ORDER_METHOD_EN varchar(180), ORDER_METHOD_DE varchar(180), ORDER_METHOD_FR varchar(180), ORDER_METHOD_JA varchar(180), ORDER_METHOD_CS varchar(180), ORDER_METHOD_DA varchar(180), ORDER_METHOD_EL varchar(180), ORDER_METHOD_ES varchar(180), ORDER_METHOD_FI varchar(180), ORDER_METHOD_HU varchar(180), ORDER_METHOD_ID varchar(180), ORDER_METHOD_IT varchar(180), ORDER_METHOD_KO varchar(180), ORDER_METHOD_MS varchar(180), ORDER_METHOD_NL varchar(180), ORDER_METHOD_NO varchar(180), ORDER_METHOD_PL varchar(180), ORDER_METHOD_PT varchar(180), ORDER_METHOD_RU varchar(180), ORDER_METHOD_SC varchar(180), ORDER_METHOD_SV varchar(180), ORDER_METHOD_TC varchar(180), ORDER_METHOD_TH varchar(180) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't';
上述命令将在 /biginsights/hive/warehouse/gosalesdw.db 目录下创建 sls_sales_fact、sls_sales_order_dim、sls_order_method_dim 三个目录。
我们还可以利用 DFS 文件系统上已经存在的数据文件来创建外部 Hive 表,它将利用已经存在的数据,而仅是在 Hive MetaStore 中增加相应的元数据定义信息,当删除该表后,也仅是将该表的元数据定义信息删除,数据文件保持不变,如下所示:
清单 15. 创建外部 Hive 表
use gosalesdw; CREATE EXTERNAL TABLE SLS_PRODUCT_DIM_EXT ( PRODUCT_KEY int, PRODUCT_LINE_CODE int, PRODUCT_TYPE_KEY int, PRODUCT_TYPE_CODE int, PRODUCT_NUMBER int, BASE_PRODUCT_KEY int, BASE_PRODUCT_NUMBER int, PRODUCT_COLOR_CODE int, PRODUCT_SIZE_CODE int, PRODUCT_BRAND_KEY int, PRODUCT_BRAND_CODE int, PRODUCT_IMAGE varchar(120), INTRODUCTION_DATE timestamp, DISCONTINUED_DATE timestamp ) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't' stored as textfile location '/biginsights/hive/warehouse/gosalesdw.db/sls_product_dim';
在创建表时,我们还可以定义优化提示信息,如下所示,我们创建了 SLS_PRODUCT_DIM_1 表,并指定该表的优化提示为 tablesize=’small’,提示该表是一张小表,这样,对该表的操作可能就会在本地运行,避免 Map Reduce 运行的开销;当和其他表连接操作时,可能会采用 mapSideHash 访问方式。
清单 16. 定义优化提示信息
use gosalesdw; CREATE TABLE SLS_PRODUCT_DIM_1( PRODUCT_KEY int, PRODUCT_LINE_CODE int, PRODUCT_TYPE_KEY int, PRODUCT_TYPE_CODE int, PRODUCT_NUMBER int, BASE_PRODUCT_KEY int, BASE_PRODUCT_NUMBER int, PRODUCT_COLOR_CODE int, PRODUCT_SIZE_CODE int, PRODUCT_BRAND_KEY int, PRODUCT_BRAND_CODE int, PRODUCT_IMAGE varchar(120), INTRODUCTION_DATE timestamp, DISCONTINUED_DATE timestamp ) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't' stored as textfile with hints (tablesize='small') ;
为了进一步提高查询的效率,我们还可以创建分区表。采用分区表,一方面,我们可以通过采用 partition elimination 技术忽略掉不需要的分区来减少数据的处理量、提高查询效率,另一方面,可以对每一个分区进行管理,如删除旧的分区,提高管理的灵活性。同时,采用表分区的方式,也会导致生成过多的文件,HCatalog 要管理大量的分区信息。如下所示,我们创建了 SLS_PRODUCT_DIM_PART 分区表:
清单 17. 创建分区表
use gosalesdw; CREATE TABLE SLS_PRODUCT_DIM_PART( PRODUCT_KEY int, PRODUCT_TYPE_KEY int, PRODUCT_TYPE_CODE int, PRODUCT_NUMBER int, BASE_PRODUCT_KEY int, BASE_PRODUCT_NUMBER int, PRODUCT_COLOR_CODE int, PRODUCT_SIZE_CODE int, PRODUCT_BRAND_KEY int, PRODUCT_BRAND_CODE int, PRODUCT_IMAGE varchar(120), INTRODUCTION_DATE timestamp, DISCONTINUED_DATE timestamp )PARTITIONED BY (PRODUCT_LINE_CODE int) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't'; biadmin@imtebi1:/opt/ibm/biginsights/bin> hadoop fs -ls /biginsights/hive/warehouse/gosalesdw.db Found 70 items drwxr-xr-x - biadmin biadmgrp 0 2013-12-15 07:47 /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim_part
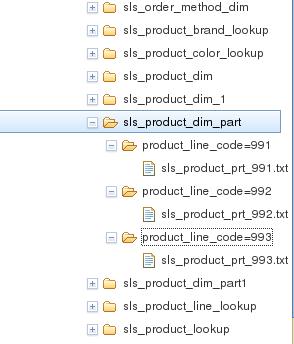
针对分区表,我们要为每一个分区分别装载数据,如下所示:我们为 sls_product_dim_part 分区表装载了 product_line_code 为 991,992,993 三个分区的数据,Big SQL 会在 sls_product_dim_part 目录下为每一个分区创建一个目录:
清单 18. 装载分区表
sls_product_dim_load_991.sql load hive data local inpath '../samples/data/sls_product_prt_991.txt' overwrite into table gosalesdw. sls_product_dim_part partition (product_line_code=991); sls_product_dim_load_992.sql load hive data local inpath '../samples/data/sls_product_prt_992.txt' into table gosalesdw.sls_product_dim_part partition (product_line_code=992); ~ sls_product_dim_load_993.sql load hive data local inpath '../samples/data/sls_product_prt_993.txt' into table gosaleSDW.sls_product_dim_part partition (product_line_code=993); biadmin@imtebi1:/opt/ibm/biginsights/bin> hadoop fs -ls /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim_part Found 3 items drwxr-xr-x - biadmin supergroup 0 2013-12-15 07:52 /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim_part/product_line_code=991 drwxr-xr-x - biadmin biadmgrp 0 2013-12-15 07:52 /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim_part/product_line_code=992 drwxr-xr-x - biadmin biadmgrp 0 2013-12-15 07:53 /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim_part/product_line_code=993
我们也可以通过执行 http://172.16.42.202:8080/ 来启动 BigInsights Console 来查看分区表创建的目录结构,如下所示:
图 10. 使用 BigInsights Console 查看分区表目录结构
 目前,Big SQL 暂不支持 Hive 的 Bucketed table。
目前,Big SQL 暂不支持 Hive 的 Bucketed table。
Big SQL 不仅支持基本的数据类型,它还支持 Array 数组及 Struct 结构复杂数据类型。数组类型是由一组相同的数据类型组成,我们可以使用下标来访问数据中的元素,其下标从 1 开始,如 phone[1];结构是由一系列不同类型数据组成,我们可以使用”.”来访问结构中的元素,如 address.city,目前,不支持结构的嵌套。如下所示,我们创建了 customer 表,它包含数组及结构数据类型:
清单 19. 创建复杂数据类型表
db25.sql CREATE TABLE customer ( id int, name VARCHAR(100), phones ARRAY (20)>, address STRUCT(100), city:VARCHAR(100), state:VARCHAR(10), Country:VARCHAR(10),zip:VARCHAR(5)> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' COLLECTION ITEMS TERMINATED BY ':'; biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql -i db25.sql 0 rows affected (total: 0.73s) Data.txt 1|David Li|63618888-12345:63618888|PGP25F:Beijing:Beijing:China:100101 2|David Wang|63618888-12346:63618888|PGP25F:Beijing:Beijing:China:100101 3|Jason Zhang|63618888-12347:63618888|PGP25F:Beijing:Beijing:China:100101 4|David Yang|63618888-12348:63618888|PGP25F:Beijing:Beijing:China:100101 5|Jason Wang|63618888-12349:63618888|PGP25F:Beijing:Beijing:China:100101 loadcomp.sql load hive data local inpath '../samples/data/data.txt' overwrite into table customer; biadmin@imtebi1:/opt/> $BIGSQL_HOME/bin/jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql -i loadcomp.sql ok. (total: 15.17s) biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray Type help for available help topics. Using JLine. [localhost][biadmin] 1> select name,phones[1],address.country from customer; +-------------+----------------+---------+ | name | | Country | +-------------+----------------+---------+ | David Li | 63618888-12345 | China | | David Wang | 63618888-12346 | China | | Jason Zhang | 63618888-12347 | China | | David Yang | 63618888-12348 | China | | Jason Wang | 63618888-12349 | China | +-------------+----------------+---------+ 5 rows in results(first row: 0.28s; total: 0.40s)
加载 Hive 表
Big SQL LOAD 命令可直接从存储在本地或 BigInsights 分布式文件系统中的文件或从多种关系数据库系统(受 Netezza 技术支持的 IBM PureData Systems for Analytics、DB2 和 Teradata)中读取数据装载到 Hive 表中。
如下所示,我们使用 Big SQL LOAD 命令从本地文件装载数据到 Hive 表中:
清单 20. 从文件装载数据到 Hive 表
--GOSALESDW.SLS_SALES_FACT load hive data local inpath '../samples/data/GOSALESDW.SLS_ORDER_METHOD_DIM.txt' overwrite into table SLS_ORDER_METHOD_DIM; load hive data local inpath '../samples/data/GOSALESDW.SLS_SALES_FACT.txt' overwrite into table SLS_SALES_FACT; load hive data local inpath '../samples/data/GOSALESDW.SLS_ORDER_METHOD_DIM.txt' overwrite into table SLS_SALES_ORDER_DIM;
我们也可以将 DB2 数据库 staff 表中的数据装载到我们创建的 staff_sales 分区表中,如下所示,在使用关系数据库装载数据到 Hive 表时,我们需要将相关的 JAR 包复制到 /opt/ibm/biginsights/sqoop/lib 目录下,并重启 Big SQL 服务。本次命令中,我们将 DB2 的 db2jcc.jar, db2jcc_license_cu.jar 文件复制到 /opt/ibm/biginsights/sqoop/lib,并重启 Big SQL 服务。
清单 21. 从数据库装载数据到 Hive 表
db21.sql create table staff_sales ( id smallint, name varchar(100), years smallint, salary decimal, comm decimal) partitioned by (dept smallint, job char(5)) ; LOAD USING JDBC CONNECTION URL 'jdbc:db2://imtebi1:50001/SAMPLE' WITH PARAMETERS (user = 'db2inst1',password='password') FROM TABLE STAFF WHERE "dept=66 and job='Sales'" INTO TABLE staff_sales PARTITION ( dept=66 , job='Sales') APPEND WITH LOAD PROPERTIES (bigsql.load.num.map.tasks = 1) ; biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql -i db21.sql 0 rows affected (total: 0.65s) 3 rows affected (total: 1m28.84s) biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray Type help for available help topics. Using JLine. [localhost][biadmin] 1> select * from staff_sales; +-----+----------+-------+--------+------+------+-------+ | id | name | years | salary | comm | dept | job | +-----+----------+-------+--------+------+------+-------+ | 280 | Wilson | 9 | 78674 | 811 | 66 | Sales | | 310 | Graham | 13 | 71000 | 200 | 66 | Sales | | 320 | Gonzales | 4 | 76858 | 844 | 66 | Sales | +-----+----------+-------+--------+------+------+-------+ 3 rows in results(first row: 0.36s; total: 0.37s)
创建、加载 Hbase 表
创建 Hbase 表
我们可以通过执行 CREATE HBASE TABLE 命令来创建 HBase 表,Big SQL 将使用自己专属的 HBase 存储管理程序来管理 HBase 数据的存储管理,该存储管理程序提供了增强的 HBase 管理功能,包括可以创建组合行健及组合字段,创建辅助索引,为不同列指定不同的压缩算法,提供简明的 HBase 表创建语法等。如下所示,我们创建了 SLS_HBASE_SALES_FACT 表:
清单 22. 创建 HBase 表
use gosalesdw; CREATE HBASE TABLE SLS_HBASE_SALES_FACT ( ORDER_DAY_KEY int, ORGANIZATION_KEY int, EMPLOYEE_KEY int, RETAILER_KEY int, RETAILER_SITE_KEY int, PRODUCT_KEY int, PROMOTION_KEY int, ORDER_METHOD_KEY int, SALES_ORDER_KEY int, SHIP_DAY_KEY int, CLOSE_DAY_KEY int, QUANTITY int, UNIT_COST decimal(19,2), UNIT_PRICE decimal(19,2), UNIT_SALE_PRICE decimal(19,2), GROSS_MARGIN double, SALE_TOTAL decimal(19,2), GROSS_PROFIT decimal(19,2) ) column mapping (key mapped by (ORDER_DAY_KEY,ORGANIZATION_KEY, EMPLOYEE_KEY, RETAILER_KEY, RETAILER_SITE_KEY, PRODUCT_KEY, PROMOTION_KEY, ORDER_METHOD_KEY) encoding binary, cf1:sales_order mapped by (SALES_ORDER_KEY, SHIP_DAY_KEY,CLOSE_DAY_KEY) separator '|' encoding string, cf2:sales_data mapped by (QUANTITY, UNIT_COST, UNIT_PRICE, UNIT_SALE_PRICE, GROSS_MARGIN, SALE_TOTAL, GROSS_PROFIT) separator '|' encoding string ) column family options (cf1 compression(gz) bloom filter( none) in memory, cf2 compression(gz) bloom filter( none) in memory) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't';
我们可以为 gosalesdw.SLS_HBASE_SALES_FACT 表创建辅助索引,如下所示:
清单 23. 创建 HBase 辅助索引
CREATE INDEX index1 ON TABLE gosalesdw.SLS_HBASE_SALES_FACT(SALES_ORDER_KEY) AS 'HBASE';
我们也可以使用 Hive 本身提供的 HBase 存储管理程序来创建 HBase 表,但是,Big SQL 不能直接读取这些表,我们需要在 Big SQL 中创建外部表来访问它。在 Big SQL 中,使用外部表的限制是不能在外部表上创建辅助索引。我们可以为已经存在的 HBase 表创建多个外部表,相当于创建多个视图。如下所示,我们创建了 EXTERNAL_SALES_FACT HBase 外部表:
清单 24. 创建 HBase 外部表
CREATE external HBASE TABLE EXTERNAL_SALES_FACT ( ORDER_DAY_KEY int, ORGANIZATION_KEY int, EMPLOYEE_KEY int, RETAILER_KEY int, RETAILER_SITE_KEY int, PRODUCT_KEY int, PROMOTION_KEY int, ORDER_METHOD_KEY int, QUANTITY int, UNIT_COST decimal(19,2), UNIT_PRICE decimal(19,2), UNIT_SALE_PRICE decimal(19,2), GROSS_MARGIN double, SALE_TOTAL decimal(19,2), GROSS_PROFIT decimal(19,2) ) column mapping (key mapped by (ORDER_DAY_KEY,ORGANIZATION_KEY, EMPLOYEE_KEY, RETAILER_KEY, RETAILER_SITE_KEY, PRODUCT_KEY, PROMOTION_KEY, ORDER_METHOD_KEY) encoding binary, cf1:sales_data mapped by (QUANTITY, UNIT_COST, UNIT_PRICE, UNIT_SALE_PRICE, GROSS_MARGIN, SALE_TOTAL, GROSS_PROFIT) separator '|' encoding string ) hbase table name 'gosalesdw.sls_hbase_sales_fact';
加载 HBase 表
我们可以使用 insert 语句为 HBase 表插入数据,如下所示:
清单 25. 使用 insert 语句为 HBase 表插入数据
create hbase table hbase_staff ( id smallint, name varchar(100)) COLUMN MAPPING ( key mapped by (id), cf:name mapped by (name) ); insert into hbase_staff(id,name) values(202,'David Li');
同样,Big SQL LOAD 命令可直接从存储在本地或 BigInsights 分布式文件系统中的文件或从多种关系数据库系统(受 Netezza 技术支持的 IBM PureData Systems for Analytics、DB2 和 Teradata)中读取数据装载到 HBase 表中。
如下所示,我们使用 Big SQL LOAD 命令从 BigInsights 分布式文件系统中的文件装载数据到 HBase 表中:
清单 26. 从文件装载数据到 HBase 表
load hbase data inpath 'hdfs://imtebi1.imte.com:9000/biginsights/GOSALESDW.SLS_SALES_FACT.txt' DELIMITED FIELDS TERMINATED BY 't' into table gosalesdw.SLS_HBASE_SALES_FACT;
我们也可以将 DB2 数据库 staff 表中的数据装载到我们创建的 hbase_staff HBase 表中,如下所示,在使用关系数据库装载数据到 HBase 表时,我们需要将相关的 JAR 包复制到 /opt/ibm/biginsights/sqoop/lib 目录下,并重启 Big SQL 服务。本次命令中,我们将 DB2 的 db2jcc.jar, db2jcc_license_cu.jar 文件复制到 /opt/ibm/biginsights/sqoop/lib,并重启 Big SQL 服务。
清单 27. 从数据库装载数据到 HBase 表
db22.sql create hbase table hbase_staff ( id smallint, name varchar(100)) COLUMN MAPPING ( key mapped by (id), cf:name mapped by (name) ); LOAD USING JDBC CONNECTION URL 'jdbc:db2://imtebi1:50001/SAMPLE' WITH PARAMETERS (user = 'dbinst1',password = 'password' ) FROM TABLE STAFF COLUMNS (ID, NAME) WHERE " ID > 100 and NAME like 'S%' " INTO hbase TABLE hbase_staff APPEND WITH LOAD PROPERTIES (bigsql.load.num.map.tasks = 1); biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql -i db22.sql 0 rows affected (total: 5.58s) 3 rows affected (total: 1m34.47s) biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray Type help for available help topics. Using JLine. [localhost][biadmin] 1> select * from hbase_staff1; +-----+----------+ | id | name | +-----+----------+ | 190 | Sneider | | 200 | Scoutten | | 220 | Smith | +-----+----------+ 3 rows in results(first row: 1.70s; total: 1.70s)
我们还可以通过 select 语句将 DB2 数据库 staff 表中的数据装载到我们创建的 hbase_staff1 HBase 表中,如下所示:
清单 28. 通过 select 语句装载数据到 HBase 表
create hbase table hbase_staff1 ( id smallint, name varchar(100), dept smallint, job string, years smallint, salary string, comm string) COLUMN MAPPING ( key mapped by (ID), cf:name mapped by (name), cf:dept mapped by (dept), cf:job mapped by (job), cf:years mapped by (years), cf:salary mapped by (salary), cf:comm mapped by(comm) ); LOAD USING JDBC CONNECTION URL 'jdbc:db2://imtebi1:50001/SAMPLE' WITH PARAMETERS (user = 'db2inst1',password = 'password' ) FROM SQL QUERY 'select * from staff where $CONDITIONS' INTO hbase TABLE hbase_staff1 APPEND WITH LOAD PROPERTIES (bigsql.load.num.map.tasks = 1);
Big SQL 提供符合 ANSI SQL 92 标准的 SQL 接口,支持预测、限制、连接、联合、排序和分组数据的 SELECT 语句。子查询和常见的表表达式(以 WITH 子句开头的查询)也受到支持。Big SQL 提供了数十个内置的函数,包括一些专用于实现 Hive 兼容性的函数。它还支持窗口函数。如果需要,SQL 程序员还可以限制某个给定查询返回的行数。Big SQL 支持标准的 SQL 数据类型,包括 tinyint, smallint, bigint, varchar(), binary(), decimal(), timestamp, struct, array 等。熟悉 SQL 的用户,可以通过 Big SQL 直接访问基于 Hadoop 的 BigInsights 大数据,而不需要修改已有的应用程序,为 SQL 用户访问 Hadoop 大数据提供了一个简便、熟悉的方法。
另外,Big SQL 提供了标准的 JDBC/ODBC 驱动程序,用户已有的 SQL 管理工具也可以直接访问 BigInsights 大数据。
Big SQL 支持查询操作,但不支持 SQL UPDATE 或 DELETE 语句。INSERT 语句仅支持用于 HBase 表。
此版本不支持视图和用户定义的约束,这二者在关系数据库中很常见。参照完整性约束和特定于域的约束应在应用程序级别上执行。无需使用 GRANT 和 REVOKE 语句来限制数据访问,管理员可使用标准的 Hadoop 命令指定 Hive 数据的文件系统访问特权。因此,应在表级别上考虑特权,而不是在行或列级别上。
传统事务管理不是 Hadoop 生态系统的一部分,所以 Big SQL 的运行未涉及到事务或锁管理,这表明提交和回滚操作不受支持。
如下所示,我们可以使用 Big SQL 执行复杂的多表连接查询操作:
清单 29. 多表连接查询
GOSALESDW_Counts_With_Joins.sql
SELECT count(*)
FROM
GOSALESDW.SLS_ORDER_METHOD_DIM AS MD,
GOSALESDW.SLS_PRODUCT_DIM AS PD,
GOSALESDW.EMP_EMPLOYEE_DIM AS ED,
GOSALESDW.SLS_SALES_FACT AS SF
WHERE
PD.PRODUCT_KEY = SF.PRODUCT_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'pd' +*/
AND PD.PRODUCT_NUMBER > 10000
AND PD.BASE_PRODUCT_KEY > 30
AND MD.ORDER_METHOD_KEY = SF.ORDER_METHOD_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'md' +*/
AND ED.EMPLOYEE_KEY = SF.EMPLOYEE_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'ed' +*/
AND ED.MANAGER_CODE1 > 20
AND MD.ORDER_METHOD_CODE > 5 ;
我们可以使用 with 语句重用 SQL 查询或 SQL 查询片段来执行更复杂的查询操作,并使用 limit 来限制输出结果集,如下所示:
清单 30. with 语句
GOSALESDW_starSchemaJoin.sql
WITH
SALES AS
(SELECT SF.*
FROM GOSALESDW.SLS_ORDER_METHOD_DIM AS MD,
GOSALESDW.SLS_PRODUCT_DIM AS PD, GOSALESDW.EMP_EMPLOYEE_DIM AS ED,
GOSALESDW.SLS_SALES_FACT AS SF
WHERE PD.PRODUCT_KEY = SF.PRODUCT_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'pd' +*/
AND PD.PRODUCT_NUMBER > 10000
AND PD.BASE_PRODUCT_KEY > 30
AND MD.ORDER_METHOD_KEY = SF.ORDER_METHOD_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'md' +*/
AND MD.ORDER_METHOD_CODE > 5
AND ED.EMPLOYEE_KEY = SF.EMPLOYEE_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'ed' +*/
AND ED.MANAGER_CODE1 > 20),
INVENTORY AS
(SELECT IF.*
FROM GOSALESDW.GO_BRANCH_DIM AS BD, GOSALESDW.DIST_INVENTORY_FACT AS IF
WHERE IF.BRANCH_KEY = BD.BRANCH_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'bd' +*/
AND BD.BRANCH_CODE > 20)
SELECT SALES.PRODUCT_KEY AS PROD_KEY, SUM(CAST (INVENTORY.QUANTITY_SHIPPED AS BIGINT)) AS INV_SHIPPED,
SUM(CAST (SALES.QUANTITY AS BIGINT)) AS PROD_QUANTITY, RANK() OVER
( ORDER BY SUM(CAST (SALES.QUANTITY AS BIGINT)) DESC) AS PROD_RANK
FROM SALES, INVENTORY
WHERE SALES.PRODUCT_KEY = INVENTORY.PRODUCT_KEY
GROUP BY SALES.PRODUCT_KEY
Limit 20;
我们还可以使用窗口函数执行复杂的统计查询,如下所示:
清单 31. 使用窗口函数
GOSALESDW_rank.sql SELECT EXTRACT(YEAR FROM CAST(CAST (order_day_key AS varchar(100)) AS timestamp)) AS year, SUM (sale_total) AS total_sales, RANK () OVER (ORDER BY SUM (sale_total) DESC) AS ranked_sales FROM gosalesdw.sls_sales_fact GROUP BY EXTRACT(YEAR FROM CAST(CAST (order_day_key AS varchar(100)) AS timestamp));
另外,Big SQL 还提供了一组元数据表,包括 syscat.tables、syscat.columns、syscat.schemas、syscat.indexcolumns。 如下所示,我们可以通过查询这些元数据表来了解 Big SQL 中定义的表、列信息:
清单 32. Big SQL 元数据表
[localhost][biadmin] 1> select * from syscat.tables where tablename='sls_sales_order_dim'; +------------+---------------------+ | schemaname | tablename | +------------+---------------------+ | gosalesdw | sls_sales_order_dim | +------------+---------------------+ 1 row in results(first row: 0.17s; total: 0.17s) [localhost][biadmin] 1> select * from syscat.columns where tablename='sls_sales_order_dim'; +------------+------------+-------------+------+-----------+-------+----------+ | schemaname | tablename | name | type | precision | scale | fulltype | +------------+------------+-------------+------+-----------+-------+----------+ | gosalesdw | sls_sales_ | sales_order | INT | 10 | 0 | int | | | order_dim | _key | | | | | | gosalesdw | sls_sales_ | order_detai | INT | 10 | 0 | int | | | order_dim | l_code | | | | | | gosalesdw | sls_sales_ | order_numbe | INT | 10 | 0 | int | | | order_dim | r | | | | | | gosalesdw | sls_sales_ | warehouse_b | INT | 10 | 0 | int | | | order_dim | ranch_code | | | | | +------------+------------+-------------+------+-----------+-------+----------+ 4 rows in results(first row: 2.8s; total: 2.10s)
本地查询及 MapReduce 任务
我们知道,Hadoop 的 MapReduce 框架可以通过分配多个 Mapper、Reducer 任务并行处理大规模数据集来实现高效数据查询。但是,MapReduce 也会产生一些运行开销,每分配一个 mapper 或 reducer 任务时,都会涉及到 JVM 启动及停止操作;mapper 会将运行的中间结果写到磁盘,reducer 通过读取磁盘中间结果进行最终运算,这样可以重启部分失效操作;任务之间的调度也需要一定的开销,通常来讲,每个任务都需要高达 20-30 秒的开销,这对于一个较大数据集的操作,可以忽略不计,但对于一个小数据集的操作,或使用行健来查询特定行数据集的 HBase 操作来说,这些开销显然就不太合适,为解决上述问题,Big SQL 可以根据查询的性质、数据量和其他因素,选择使用 Hadoop 的 MapReduce 框架并行处理各种查询任务,或者在单个节点上的 Big SQL 服务器上本地执行您的查询, 也可以部分查询工作在 Hadoop 的 MapReduce 框架上完成,部分查询工作在 Big SQL 服务器上完成。
Big SQL 可以执行如下动态运行优化策略来提高查询性能:
- 针对简单的 SQL 查询语句,如 SELECT c1,c2 FROM T1,可以自动选择采用本地查询还是使用 Hadoop 的 MapReduce 框架运行
- 针对查询的每一步任务,如果它的输入数据集很小,它将在 Big SQL 服务器本地执行,我们可以通过设置 $BIGSQL_HOME/conf/bigsql-site.xml 文件中的 bigsql.localmode.size 属性来进行控制
- 如果一张表很小,会使用 map-side hash join 连接方式提高查询效率,我们可以通过设置 $BIGSQL_HOME/conf/bigsql-site.xml 文件中的 bigsql.memoryjoin.size 属性来进行控制
- 针对相对复杂 SQL 查询语句,我们可以通过使用 SQL 查询提示来优化查询效率,比如,我们可以设置 /*+ accessmode=’local’ +*/ 查询提示告诉 Big SQL,针对 t1 表采用本地查询模式。如下所示:
清单 33. 采用本地查询模式
SELECT c1 FROM t1 /*+ accessmode='local' +*/ WHERE c2 > 10
- 我们也可以设置 session 级别的优化提示来优化查询效率,如下所示:
清单 34. 设置 session 级别优化提示
set force local on; SELECT c1 FROM t1 WHERE c2 > 10;
创建 HBase 辅助索引
Big SQL 支持使用 CREATE INDEX 语句为 HBase 创建辅助索引。这些索引可改进在加入索引的列上进行过滤的查询的运行性能。针对索引字段的过滤查询会自动使用索引,我们也可以通过 SQL 查询提示强制使用 HBase 辅助索引,如下所示:
清单 35. HBase 辅助索引提示
CREATE INDEX index1 ON TABLE gosalesdw.SLS_HBASE_SALES_FACT(SALES_ORDER_KEY) AS 'HBASE'; select count(*) from gosalesdw.sls_hbase_sales_fact /*+ rowcachesize=2000,useindex='index1' +*/ where sales_order_key<195000;
我们可以基于单个键或复合键来创建 HBase 辅助索引。
在创建 HBase 辅助索引时,索引被保存在相应的 HBase 索引表中,Big SQL 使用 Map Reduce index builder 线程来创建并加载 HBase 索引表,通过 synchronous coprocessor 线程来同步索引信息,如下图所示:
图 11. HBase 辅助索引架构
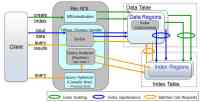 当使用 Big SQL 将数据插入 HBase 表中或将来自一个文件的数据加载到 HBase 表中时会自动更新它的索引。但是,在 BigInsights 2.1 中,将来自远程关系数据库的数据加载到 HBase 表中不会自动更新表的辅助索引。相反,管理员需要丢弃并重新创建必要的索引。
当使用 Big SQL 将数据插入 HBase 表中或将来自一个文件的数据加载到 HBase 表中时会自动更新它的索引。但是,在 BigInsights 2.1 中,将来自远程关系数据库的数据加载到 HBase 表中不会自动更新表的辅助索引。相反,管理员需要丢弃并重新创建必要的索引。
SQL 优化提示
Big SQL 的查询优化器会动态地参考某些统计信息来确定一种高效的数据访问策略。但是,在一些情况下,Big SQL 可能没有足够的统计信息可用。例如,它的基础数据源可能未提供这些信息。在这些情况下, Big SQL 程序员将优化提示嵌入其查询中可能有所帮助,因为这么做可使 Big SQL 生成更好的执行计划。提示可与查询执行模式(本地或并行)、连接方法、索引使用等相关。
表连接顺序
我们在 FROM 子句中提供的表的顺序会做为隐含提示来决定表连接的策略。在大多数情况下,Big SQL 会按照我们提供的顺序进行表连接操作。因此,我们所指定的表的顺序至关重要。当我们指定表的顺序时,需要考虑:尽可能早地限制结果集。我们需要将高选择性的表(判断谓词会过滤掉大量数据,或者表连接操作会去除大量数据)放到查询的前边,这样会减少输出到查询下一阶段的数据量。
表访问提示
表访问提示会影响如何读取表、如何确定数据源以及如何优化查询的策略。表访问提示会影响读表的行为,是使用 MapReduce 执行表连接操作还是使用 hash 连接操作。它还会影响如何读取特定数据源的策略。
accessmode 提示
accessmode 提示用来决定是使用 MapReduce 来处理数据,还是在 Big SQL 服务器本地处理数据。accessmode 提示支持下列选择:
- Local – 指定在 Big SQL 服务器本地处理数据,不采用 mapreduce 处理方式。
- mapreduce 或 mr – 指定使用 MapReduce 来处理数据。MapReduce 是 Big SQL 默认的处理方式,如果任何数据源的处理方式不支持 MapReduce,Big SQL 会自动选择 Big SQL 服务器本地处理方式。
下边的例子中,accessmode 提示强制 Big SQL 将整个 T1 表顺序读入 Big SQL 服务器本地内存并执行聚合操作。
清单 36. accessmode 提示
SELECT c1,count(*) from T1 /*+ accessmode='local' +*/ group by c1;
accessmode= ‘ local ’提示一般用于以下场景:
- 如果表足够小,创建 MapReduce 作业的开销远大于顺序读入 Big SQL 服务器本地内存进行处理的开销。
- 使用 TOP 或 LIMIT 子句大幅度减少数据返回结果集的大小。注意,如果使用了 GROUP BY 或 ORDER BY 子句,会涉及到全表操作,此时,会影响 TOP 或 LIMIT 子句的预期效果。
- Big SQL 服务器本地有足够的内存来运行查询。在上边的例子中,聚合操作会完全在 Big SQL 服务器本地内存中完成,同样,如果使用了 ORDER BY 子句,数据会在内存中排序之后返回,也需要 Big SQL 服务器本地有足够的内存。
注意,当使用 accessmode= ‘ local ’提示时,可能要使用大量的本地内存,特别是当多个用户并发执行多个查询时。
我们也可以采用如下 accessmode 提示强制采用 MapReduce 方式来处理数据,如下所示 :
清单 37. 采用 MapReduce 方式
select * from gosalesdw.sls_sales_order_dim /*+ accessmode = 'mr' +*/ where sales_order_key<100020;
此外,我们还可以设置 session 级别 accessmode 提示,它会在整个会话级别生效,如下所示:
清单 38. 会话级 accessmode 提示
set force local on; select * from gosalesdw.sls_sales_order_dim where sales_order_key<100020;
多表连接及本地访问提示
当有多个表进行连接操作时,本地访问模式(accessmode= ’ local ’)会强制后续参与连接的表采用本地访问模式。 如下所示,我们设置 t1 表为本地访问模式,导致整个 SQL 语句都会以本地方式运行,即使我们显式指定 t2 表以 mapreduce 模式运行:
清单 39. 多表连接本地访问提示
SELECT t1.c1, count(*) FROM t1 /*+ accessmode='local' +*/, t2 WHERE t1.c2 = t2.c2 GROUP BY t1.c1;
当查询操作涉及多于两个表的连接操作时,如果不能按照我们指定的顺序进行表连接操作会导致重新调整表的连接顺序,这时,可能会导致被标记为本地访问提示的表之后的表采用 MapReduce 方式运行,我们可以通过设置所有表为本地访问模式(accessmode= ’ local ’)来强制整个查询以本地方式运行。
tablesize 提示
当表连接操作中涉及到小表时,Big SQL 往往会使用一个 MapReduce 作业来处理可以在内存中进行连接操作的表从而提高查询效率。 如下所示,通常,这个查询需要两个 MapReduce 作业:一个用于表连接操作,一个用于分组操作:
清单 40. 表连接操
SELECT c1, count(*) from T1, T2 where T1.c2 = T2.c2 GROUP BY c1;
如果 T2 表很小,我们可以使用如下语句来提高查询效率:
清单 41. tablesize 提示
SELECT c1, count(*) FROM T1, T2 /*+ tablesize='small' +*/ where T1.c2 = T2.c2 GROUP BY c1;
该语句只使用一个 MapReduce 作业来扫描 T1 表,每一个 mapper 任务会在内存中执行和 T2 表连接操作,分组操作在同一个任务的 reduce 阶段完成。
tablesize 提示用来指定采用内存连接(hash join)方式还是采用 MapReduce 执行表连接操作。tablesize 提示支持以下选择:
- small – 指定该表足够小,可以装入内存并执行 hash 操作。
- large – 默认设置,它避免采用内存连接(hash join)方式。
下边例子,我们指定 GOSALESDW.GO_BRANCH_DIM 表是一个大表,因此,会避免采用内存连接(hash join)方式:
清单 42. 避免采用内存连接
SELECT count(*)
FROM
GOSALESDW.GO_BRANCH_DIM /*+ tablesize='large' +*/ AS BD ,
GOSALESDW.DIST_INVENTORY_FACT AS IF
WHERE
IF.BRANCH_KEY = BD.BRANCH_KEY
AND BD.BRANCH_CODE > 20;
下边例子,我们指定 GOSALESDW.GO_BRANCH_DIM 表是一个小表,因此,会尽量采用内存连接(hash join)方式:
清单 43. 采用内存连接
SELECT BD.BRANCH_KEY,count(*)
FROM
GOSALESDW.GO_BRANCH_DIM /*+ tablesize='small' +*/ AS BD ,
GOSALESDW.DIST_INVENTORY_FACT AS IF
WHERE
IF.BRANCH_KEY = BD.BRANCH_KEY
AND BD.BRANCH_CODE > 20
GROUP BY BD.BRANCH_KEY;
HBase 提示
针对 HBase,Big SQL 提供如下 SQL 优化提示:
- rowcachesize 提示
- colbatchsize 提示
- useindex 提示
rowcachesize 提示
rowcachesize 提示用来指定数据从 region servers 返回到 Big SQL ( 返回给 Big SQL 服务器本地运行或 mappers or reducers 并行处理 ) 记录集的大小。这个设置可以显著提高 HBase 数据库查询的性能。当然,如果该值设置过高,也会消耗更多的 region servers 及查询运行本地(Big SQL 服务器或 mappers or reducers)的内存。如果没有设置,rowcachesize 默认为 2000 行。
如下所示,我们设置 rowcachesize 大小为 4000 行:
清单 44. 设置 rowcachesize 大小
SELECT c1, c3 FROM hbase_tab /*+ rowcachesize=4000 +*/ WHERE c2 > 10;
注意,针对宽表,我们可能需要减小 rowcachesize 设置值来减少每次读取的传输数据量。
colbatchsize 提示
colbatchsize 提示主要用来避免因某一个或某几个特别大的字段而消耗太多的内存。colbatchsize 提示指定每一次读取操作从 region server 传输的字段个数,默认为 -1,表示读取所有的字段。
如下所示,我们设置 colbatchsize 大小为 5:
清单 45. 设置 colbatchsize 大小
SELECT c1, c3 FROM hbase_tab /*+ colbatchsize=5 +*/ WHERE c2 > 10;
useindex 提示
useindex 提示用来指定查询语句所使用的 HBase 辅助索引名称。特别是当有多个候选索引存在时,我们可以指定使用哪个特定索引。如下所示,我们为 gosalesdw.SLS_HBASE_SALES_FACT HBase 表创建了 index1 辅助索引,并指定下边查询语句使用我们创建的 index1 索引:
清单 46. 设置 HBase 辅助索引
CREATE INDEX index1 ON TABLE gosalesdw.SLS_HBASE_SALES_FACT(SALES_ORDER_KEY) AS 'HBASE'; select count(*) from gosalesdw.sls_hbase_sales_fact /*+ rowcachesize=2000,useindex='index1' +*/ where sales_order_key<195000;
如果 useindex 提示指定的索引不存在,Big SQL 将会报错。
使用索引会显著提高查询性能,但是,在 HBase 中,访问索引需要首先查找索引表,之后再查找数据表,当需要扫描大量数据时,系统开销也比较大,这种情况下,采用 MapReduce 作业扫描数据表可能效率更高。
Join 提示
我们可以使用 Join 提示来提高 MapReduce 作业的执行效率。
joinmethod 提示
joinmethod 提示用来指定使用表连接操作的方式。目前, joinmethod 提示只支持 mapsidehash 值。joinmethod 提示的” mapsidehash”设置比 tablesize 提示的”small”设置更具体,它可以控制使用哪些字段进行 Hash 连接操作。
当我们使用 joinmethod 提示的” mapsidehash”设置时,我们要同时使用 buildtable 提示来指定针对哪些表进行 hash 操作。如下所示,该语句用来指定针对 T2 表的 c2 字段进行 Hash 连接操作:
清单 47. 设置 joinmethod 提示
SELECT a.c1 FROM T1 as a, T2 as b WHERE a.c2 = b.c2 /*+ joinmethod='mapsidehash', buildtable='b' +*/ AND a.c3 = b.c3;
buildtable 提示
当我们使用 joinmethod 提示的” mapsidehash”设置时,我们要同时使用 buildtable 提示来指定针对哪些表进行 hash 操作。如果未同时指定该提示将报错。
Subquery 提示
Big SQL 的 SQL 查询引擎可以通过改写相关的 SQL 语句来提高查询性能,特别是针对 SQL 子查询,它往往会改写为表连接操作, 如下所示,针对下边的查询语句:
清单 48. 子查询语句
SELECT * FROM T1 WHERE c2 IN (SELECT c2 FROM T2 WHERE T2.c3 = T1.c3 AND t2.c4 = 'Fred');
Big SQL 会该写为:
清单 49. 该写子查询语句
SELECT T1.* FROM T1, (SELECT c2, c3 FROM T2 WHERE t2.c4 = 'Fred') as D0 WHERE T1.c3 = D0.c3;
在一些情况下,子查询的数据量很小,比如说,100 行记录,这时,不改写该语句往往效率更高,我们可以通过 rewrite 提示禁止子查询重写功能,如下所示:
清单 50. 禁止子查询重写
SELECT * FROM T1 WHERE c2 IN (/*+ rewrite=false +*/ SELECT c2 FROM T2 WHERE T2.c3 = T1.c3 AND t2.c4 = 'Fred');
Big SQL 服务器优化
内存优化
默认情况下,Big SQL 会尝试使用系统内存的 1/3,我们可以通过设置环境变量来改变内存使用量,优化系统性能。参数设置完成后,需要重新启动 Big SQL 服务器使其生效。
如下所示,我们可以使用 VERBOSE=true $BIGSQL_HOME/bin/bigsql status 命令查看当前 Big SQL 服务器内存使用情况:
清单 51. 查看内存使用情况
biadmin@imtebi1:/opt/ibm/biginsights> VERBOSE=true $BIGSQL_HOME/bin/bigsql status Total memory on the machine = 3958600 KB Max memory allocated to bigsql is: 1288m BigSQL server is running (pid 8243)
我们可以通过如下环境变量来设置 Big SQL 服务器使用内存的最大值及最小值,并重启 Big SQL 服务器生效新的设置,如下所示:
清单 52. 设置内存使用量
/opt/ibm/biginsights> export BIGSQL_CONF_INSTANCE_INITIAL_MEM=2g /opt/ibm/biginsights> export BIGSQL_CONF_INSTANCE_MAX_MEM=4g biadmin@imtebi1:/opt/ibm/biginsights> $BIGSQL_HOME/bin/bigsql stop BigSQL pid 12611 stopped. biadmin@imtebi1:/opt/ibm/biginsights> $BIGSQL_HOME/bin/bigsql start BigSQL running, pid 12811. /opt/ibm/biginsights> VERBOSE=true $BIGSQL_HOME/bin/bigsql status Max memory allocated to bigsql is: 4g BigSQL server is running (pid 12811)
采用 Big SQL 服务器本地运行模式,内存大小的设置至关重要,因为本地运算主要使用内存来完成。如果本地运算涉及的数据可以装入内存中,将极大地提高查询效率。同时,我们也要考虑到,针对多个并发请求,每一个请求都需要申请内存进行本地处理。
服务器设置
在 Hadoop 中,我们可以通过修改作业属性来调优运行时性能。尽管 Big SQL 会尝试选择最优的属性,如果需要的话,我们可以在服务器或查询级别上调整这些属性。在 $BIGSQL_HOME/conf/bigsql-site.xml 文件中包含了 Big SQL 服务器级别的默认作业属性设置,我们也可以使用 SET 命令动态调整作业属性的设置。下边,我们简要介绍几个常用的 Big SQL 作业属性设置,关于 Big SQL 作业属性值调整的具体内容,大家可以参考 Big SQL 信息中心。
清单 53. 调整 Big SQL 作业属性值
bigsql.reducers.autocalculate [true] 默认值为 True,Big SQL 会自动计算 MapReduce 作业使用 reducers 的数量。 bigsql.reducers.bytes.per.reducer [1GB] 默认值为 1GB,指定每一个 reducer 可以处理的数据量。 bigsql.memoryjoin.size [10MB] 默认值为 10MB,当表的大小低于该值时,Big SQL 将使用 map-side memory join 方式。 bigsql.localmode.size [200MB] 默认值为 200MB,当所有表的数据量小于该值,Big SQL 将自动在服务器本地运行。
我们也可以通过 SET 命令动态改变作业属性值的设置,如下所示:
清单 54. 动态改变作业属性值
biadmin@imtebi1:/opt/ibm/biginsights> $BIGSQL_HOME/bin/jsqsh -U biadmin -P password JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray Type help for available help topics. Using JLine. [localhost][biadmin] 1> set bigsql.reducers.byte.per.reducer = 209715200; 1 row affected (total: 0.8s) [localhost][biadmin] 1> SELECT * FROM T1 WHERE c2 IN (SELECT c2 FROM T2 WHERE T2.c3 = T1.c3 AND t2.c4 = 'Fred'); +----+----+----+ | c1 | c2 | c3 | +----+----+----+ | 2 | 2 | 2 | +----+----+----+ 1 row in results(first row: 14.69s; total: 14.69s)
结论
通过上述介绍,我们对 Big SQL 的体系结构、工作原理、技术特点有了一个基本的了解,对如何使用 Big SQL 创建、加载并访问 Hive、HBbase 表也有了一个比较全面的了解,另外,我们还介绍了 Big SQL 查询优化的各种方法。希望能够帮助大家快速掌握利用 Big SQL 查询 BigInsights Hadoop 大数据的基本方法。
转自developerworks 作者:张光业, 顾问工程师, IBM