ivotal努力整合并改进其母公司买来的大数据技术,以应对大数据企业级应用所面临的挑战。
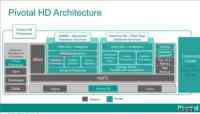
Pivotal是由VMware的Cloud Foundry和EMC的Greenplum等业务分拆并重组而成新公司,其目的是为企业带来重新构建、严格测试过的Hadoop,该公司已将Apache Hadoop 2.2技术融入其新的Pivotal HD 2.0版本中,同时还在该版本中集成了内存数据库GemFire XD。
GemFire通过云计算平台虚拟化技术,将若干X86服务器的内存集中起来,组成最高可达数十TB的内存资源池,将全部数据加载到内存中,进行内存计算。计算过程本身不需要读写磁盘,只是定期将数据同步或异步方式写到磁盘。GemFire在分布式集群中保存了多份数据,任何一台机器故障,其它机器上还有备份数据,不用担心数据丢失,而且有磁盘数据作为备份。
Pivotal希望利用稳定的技术为大公司提供一种数据解决方案,为大公司每分钟产生的数据建立周期性良性反馈机制,比如手机运营商可以利用Pivotal HD和GemFire HD的大数据和分析能力来确定最快的呼叫路由,如果呼叫降级或失败就将这些信息反馈回来进行处理,这样可以及时解决问题。在一个完美的大数据环境下,及时向用户道歉也能给客户留下很好的影响。
受益于Apache Hadoop 2.2的更新,Pivotal HD 2.0现在将支持NFS和快照处理,这意味着企业客户在出现问题时可以回滚。
Pivotal HD 2.0在数据库性能方面也有了较大的改进,加强了HAWQ SQL查询性能,其数据库引擎其实是基于Greenplum数据库并做了一些改进。HAWQ现在可以应用MADlib机器学习型库中的50多种数据库内算法,而且该数据库引擎现在支持基于R、Python以及Java语言查询和应用的自动翻译,所以HAWQ可以用SQL很好的处理业务逻辑并对过程进行很好的控制。
Pivotal也许不是第一个从Apache更新获益的商业公司,但它是第一个声称要对开源代码做最严格测试的公司。Pivotal产品营销部门的高级主管Michael Cucchi告诉我们:“我们采用Apache发行版并对其进行强化,为其进行我们自己的QA和回归测试,也尝试在1000个节点的集群上实现回滚操作,我们的测试是在大规模集群上完成的。”
Pivotal HD 2.0新版本为应对实时分析的需求集成了GemFire HD,而且还加入了GraphLab图分析技术,为应对巨大的工作负载,新版本中也添加了改进后的HAWQ SQL查询引擎。
这些都算不了什么——Pivotal只是将EMC和Vmware一系列收购中得到的技术整合到一起,使企业客户可以方便地大规模部署Hadoop并从中获得真正价值。比如HAWQ SQL查询工具来自于EMC 2010年对Green Plum的收购;Gemfire来自于同年Vmware对GemStone的收购。
Cucchi告诉我们:“最初Pivotal HD软件支持在裸机上运行,也可以在VMware环境中运行,还可以和硬件绑定在一起作为一种设备,但将来如果用户想要在AWS或其他公有云上运行Pivotal HD也同样可以。”
这的确是一个极好的机会,这使Pivotal甚至可以抗衡IBM这样的IT巨头以及Cloudera和HortonWorks这样的新生Hadoop力量,换句话说,未来这些企业也将面临Pivotal这样强劲的对手。
原文链接:Pivotal spiffs up Hadoop and GemFire to meet enterprise big data challenges