小小的Mac Mini计算性能可以超过由1636个节点组成的Hadoop集群,即使是在某些用例下听起来也更像天方夜谭,然而近日GraphChi却声称做到了这一点。长话短说,在看这个壮举之前,我们有必要先了解一下GraphLab的GraphChi。
GraphChi专注小电脑的分布式框架
GraphChi由卡耐基梅隆大学计算机科学家设计,可以在个人计算机上高效进行大规模计算的框架,多用于社交媒体或网络搜索分析类任务,比如推荐引擎。我们都知道推荐引擎专注的是图谱计算(graph computation),分析社交媒体用户之间的关系;但是这类计算通常需要海量的内存,通常出现在由大量计算机组成的集群上。
区别于将图谱储存在内存中,GraphChi利用了个人计算机上的海量硬盘,将图谱储存在硬盘上。通过实验室主任Carlos Guestrin了解到,为了弥补硬盘与内存之间的速度差距,他们设计了更快速的,减少随机读写的硬盘访问方法。同时,GraphChi还能处理“流图谱”(streaming graphs),流图谱能通过显示关系随时间的变化建立起精确的大型网络模型。
Mac Mini与1636节点Hadoop的战争
对同一个具有15亿边缘的Twitter图谱(2010年以后)进行处理(三角形计数),GraphChi通过1个小时完成了1636个Hadoop节点7个小时的工作。近日,通过Rangespan的数据科学家Christian Prokopp,我们了解了这项超越得以实现的原理——对算法的极致优化,以及单台机器对集群设置的优势。
运行环境
GraphChi的首个优势在于可以简化许多假设以及后续的算法,不需要进行分布式处理。有了这个优势,并理解单机器的性能进行总体上的评估(优势和劣势),整个处理过程将非常容易设计。单机器通常具备两个特征:1,大的图谱问题不会被塞进RAM(Random Access Memory);2,拥有很大的磁盘,可以处理所有数据。
传统的磁盘通常不会有随机读取优化,他们只针对连续性读取。新时代计算机可能都会具备更快随机读写的SSD,虽然它们还是会比RAM慢许多。因此,任何在单商用机器磁盘上运行的算法仍然需要尽可能避免随机访问数据。
分而治之
卡耐基梅隆大学的博士生Aapo Kyrola使用这个原理来改善GraphLab,一个分布式图谱计算框架。他的想法是将图谱划分成不同的分片,每一个都可以通过这台机器的内存处理。随后这些分片可以并行的在内存中处理,其它分片需要做的更新则通过随后的连续写入完成。这样将最小化磁盘上的随机操作,合理的使用机器的内存做一些并行操作。

Aapo发明了 PSW(Parallel Sliding Window)算法来解决关键的性能提升问题,针对磁盘的连续读写。PSW通过source shards对1个分片中所有的顶点进行排序,这意味着每个分片本质上都被分割成由顶点组成的块,同时这些顶点又会与其它分片关联。
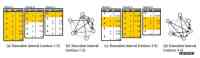
举个例子,在interval 1中(上图)shard 1正在内存中进行处理,它是顶点到目的顶点边长一个子集。这些目标顶点是余下分片中排序源值的连续块,因此可以连续的读取。所有的更新都会被计算,并在内存中为shard 1进行存储,随后则被连续的写入其它分片,修改会在读取之前进行。最终,内存中更新后的版本会被连续的写入磁盘。在interval 2中,shard 2被加载;当然,同样的方法会被应用于其它分片。
这个方法充分利用了新型商用计算机的架构特征,正如原始论文中的一些特性说明。比如,对不同磁盘中数据的拆分;同时,使用SSD代替传统磁盘对性能将不再有双倍的提升,因为算法已经大幅度的提升高永久存储性能。即使是增加分片的数量,对CraphChi的吞吐量影响也不大,这样将保证更大图的可靠性能。值得注意的是,另一个算法高效性证明是——将计算彻底的移到内存,对比SSD计算时间只有1.1到2.5(因素)的提升。

GraphChi的性能对比( 源出处)
GraphChi公布了模式转变后的性能获益,其中包括与类似Hadoop、Spark等通用解决方案,升值还包括了高优化的图计算框架GraphLab、PowerGraph。后者属于高优化的分布式并行解决方案,同样做Twitter三角计数的处理只需1.5分钟。然而,它使用了64个节点,每个8核心,总计512个核心。粗略的算,性能提升了40倍,但是却耗费了256倍的计算资源(核心)。