中存储网消息,将计算靠近数据,目标是避免跨网络把大量数据迁移到主服务器来降低存储数据访问延迟。将计算靠近磁盘驱动器正面临着严峻的挑战,但访问速度更快的闪存驱动器可以轻松做到这一点。
有一种相反的方法——通过NVMe over Fabric让数据更快地靠近计算——可能会给带有板载计算的闪存驱动器造成阻碍。有两家初创公司就涉足把计算融入闪存驱动器的领域,:ScaleFlux和NGD Systems。
ScaleFlux
ScaleFlux在其CSS 1000闪存驱动器板上安装了Xilinx FPGA,将其称为Computational Storage,并让主服务器负责Flash Translation Layer(FTL)。
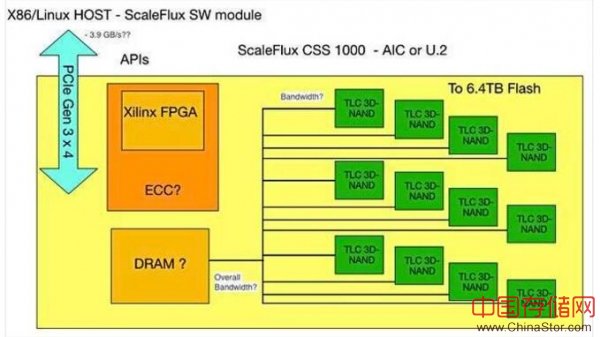
我们对ScaleFlux计算+闪存驱动器的理解
CSS 1000驱动器采用HHHL AIC格式或U.2 2.5英寸格式,使用TLC(3位/单元)3D NAND,提供高达6.4TB的容量。ScaleFlux说,每个服务器最多可以有8个CSS 1000驱动器,最大容量为51TB。

x86主服务器运行一个ScaleFlux软件模块,这种模块提供对驱动器的API访问。ScaleFlux公司向中存储网记者表示,通过一体化的、易于安装的软件包,可轻松实现低延迟存储IO和计算硬件加速,无需开发工作或重新编译应用。
ScaleFlux在美国圣何塞、中国北京和日本横滨都设有办事处。
中国公共云提供商UCloud是ScaleFlux的客户之一,ScaleFlux与服务器制造商浪潮合作将其驱动器与浪潮服务器进行集成。ScaleFlux已经测试了使用这个卡加速Aerospike、PostgrSQL和MySQL等软件的效果:
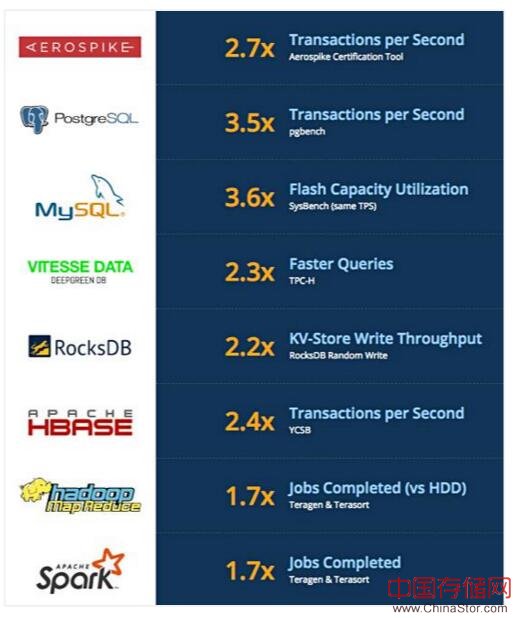
ScaleFlux的网站已单独列出关于此类产品加速的详细信息。例如,这就是它对NoSQL数据库Aerospike性能评价:
与NVMe SSD相比,ScaleFlux CSS 1000系列每秒处理速度明显更高。该测试进行24小时,读取率为67%,写入率为33%,对象大小为1.5 KB。
这意味着已经编写了代码运行在该卡的FPGA上,针对这些应用。ScaleFlux向中存储网记者表示,它已经开始销售其CSS 10000驱动器,并将该驱动器出货到多个企业的最终用户生产环境中。
ScaleFlux公司联合创始人兼首席执行官Hao Zhong向中存储网记者表示:“从高交易吞吐量和电子商务支付环境到需要对查询进行实时响应的旅游网站,我们的客户从使用CSS的大容量闪存存储部署中获得更高价值。”
ScaleFlux公司正在将驱动器应用扩展到内容交付、搜索、高性能计算、人工智能和机器学习环境。
下一个厂商采取了不同的方法,使用具有更高容量的卡和ARM处理器,使其更容易编程。
NGD Systems
Next Generation Data (NGD) Systems成立于2013年,使用大量的美光TLC 3D NAND闪存开发了一款Catalina 2闪存驱动器,容量高达24TB。目前NGD Systems已经进行了两轮融资,2016年融资630万美元,2017年为1000万美元。
NGD Systems公司的三位创始人——首席执行官Nader Salessi、首席技术官Vladimir Alves和执行副总裁理Richard Mateya——都是SSD行业的资深人士,曾在STEC、西部数据和Memtech。 NGD Systems以前名称是NxGnData,在将片上计算推广到多核ARM系统之前,这家公司致力于将FPGA添加到闪存卡中。

Catalina 2卡
NGD Systems向中存储网记者表示,已经实现了业内每TB最低的每瓦功耗,每TB功耗低于0.65瓦特。
主服务器有一个C / C ++库和一个代理程序,用于使用NVMe协议处理跨PCIe 3.0 x4链接与驱动器进行通信所需的通道。这个驱动器SoC配有运行Linux的A53 ARM CPU,以及用于12个M.2闪存模块的ECC和FTL功能的逻辑。
我们对Catalina 2主要组件的理解,显示了连接到板载ARM SoC的闪存模块。
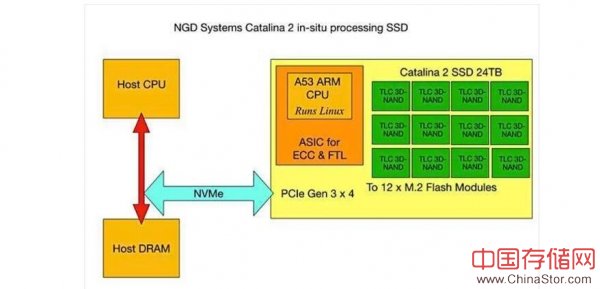
Salessi谈到Catalina 2卡时说道:“嵌入式人工智能和机器学习等高级应用本质上是IO密集型的,可以运行在存储设备中。”
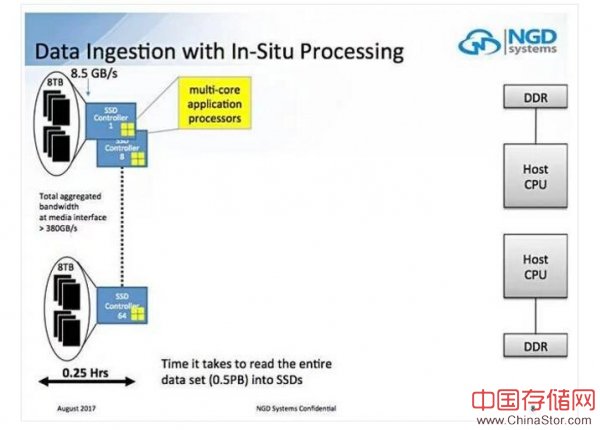
Vladimir Alves的闪存峰会演讲中谈到了一个场景,在这个场景中需要4.5个小时才能将0.5PB数据集读入装有8TB SSD的2-CPU服务器系统中:
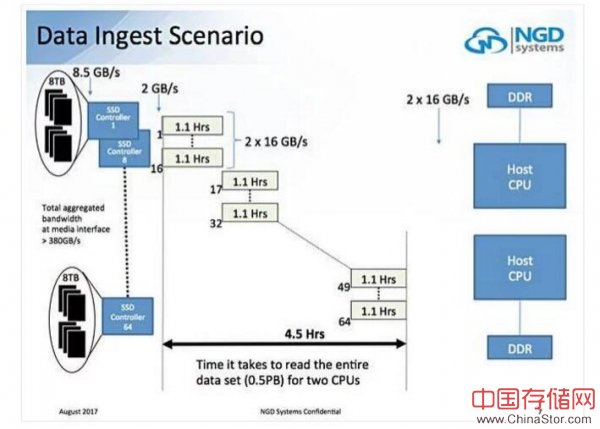
如果这些8TB SSDS替换为8TB Catalina驱动器,则接收时间会减少15分钟——速度提高8倍,总带宽超过380GB /秒。
NGD Systems仍处于隐身状态。我们可能预计这家公司很快会走出隐身模式。
NVMeStorage
NVMeStorage通过将计算移到数据所在的位置承诺实现范例上的转变,它使用的就是Catalina卡。
NVMeStorage公司联合创始人Jos Keulers在博客中写道:“原位处理(In Situ Processing)意味着驱动器本身具有计算能力,数据首先保存在驱动器上,数据不会离开最初保存在的驱动器。”
“存储之后,可以在存储数据的位置上进行分析,而无需将数据从驱动器传输出去。可以对哪些数据需要发送回云进行大数据分析、做协议转换进行本地判断,还可以在数据不再有用或有价值的时候清理磁盘、删除保存的物联网数据。”
他向中存储网记者表示,这种驱动器/设备可以用于雾计算:“分析物联网数据的理想位置,是靠近产生和处理数据的设备,这就是所谓的雾计算。”
Keulers补充道:“由于物联网数据无需传输,因此原位处理是至关重要的,借助NGD Systems的Catalina In-Situ处理NMVe技术支持NVMestorage.com,确保雾中的安全旅程。”
绕过NVMeoF的问题
NVMe over Fabrics基本上是通过让主服务器使用远程直接内存访问(RDMA)访问存储数据来消除存储网络问题,因此,我们可以说,以两位数微秒的速度操作数据IO。
这有效地让数据更快速地靠近计算,而计算是我们的老朋友,x86服务器,意味着将代码放置在闪存驱动器FPGA或ARM处理器上不存在编程问题,也无需协调其活动。
借助NVMeoF,无需开发专用硬件即可将计算添加到存储驱动器,这意味着可以使用标准的商用驱动器。
我们从哪里开始?
我们询问了ScaleFlux营销负责人Tian Jason Tian,NVMe over Fabrics会给原位处理带来怎样的影响?因为它通过RDMA式连接使存储阵列更接近服务器,这是否意味着你不再需要像CSS 1000这样的产品?
他向中存储网记者表示:“今天的大多数应用都受益于横向扩展/超融合部署模型中的Computational Storage,在这种模型中,Computational Storage可以在计算服务器中直接链接。这提供了最低延迟和最革新的部署模式。随着客户考虑解耦的存储,Computational Storage将提供更高的价值,因为本地计算功能不仅可以在计算服务器中减少CPU/内存之间的数据迁移,现在,还可减少Fabrics之间的数据迁移。”
像SCM(存储级内存)和NVMeoF这样的技术会给原位处理带来怎样的影响?
他认为:“SCM和NVMeoF都承诺要么增强要么扩展Computational Storage的使用模型,如上所述。随着SCM的成熟,我们看到它与Computational Storage一起工作来扩展应用集。从NVMeoF的角度来看,在存储上进行处理,可以减少数据中心内的数据移动,从而降低功耗、降低成本并提高数据驱动应用的响应速度。”
NGD Systems公司的营销主管Scott Shadley也不认为NVMeoF会淘汰掉具有计算能力的闪存驱动器:“NVMeoF仍然只是让每个驱动器获得更多CPU访问。它能起到一定的帮助作用,但不能完全解决瓶颈问题。它只是对存储位置的整合,而不是变得更智能或更高效。”
但它解决了存储网络瓶颈问题吗?
他说:“下一步需要全闪存阵列和服务器销售人员卖出更多、更大的驱动器,但由于数量或内核数量还没有增加,因此实际上并没有实现高效扩展。在驱动器上的CPU仍然没有实现扩展。”
将计算靠近数据,具有主服务器CPU卸载的元素,类似于TOE网卡,即TCP/IP卸载引擎。这些都有一个明确的事情要做,那就是TCP / IP处理,但是除了压缩或擦除编码之类的低级操作之外,没有存储层面上类似的操作。
如果具备计算能力的闪存卡发挥一定作用,那么就需要了解主存储处理和驱动器存储处理之间的界限。这可能是一个可移动的界限,随着一般应用类型的变化而变化,但厂商必须能够在特定的市场领域展示其产品技术的持久价值。