
译注:本项目平台为美国伊利诺伊大学的OCEAN,由176台服务器+16台Pica8公司OpenFlow交换机组成,提供从底层物理网络到应用的完整环境,支撑的项目包括获得HotSDN 2012最佳论文奖的VeriFlow,Jellyfish数据中心架构以及LIME虚拟网络迁移系统。项目2011年启动时OpenStack的网络仍为Quantum,方案设计可应用于后续版本Neutron。
摘要:SDN(软件定义网络)通过逻辑上集中的主控制器实现对底层交换机报文处理的管理,在业界也因此出现了多种SDN/OpenFlow的控制器比如RYU,OpenDaylight、Floodlight等;随着云计算技术的发展在IaaS领域涌现很多开源的云平台管理工具,但是这两个领域目前还没有很好的融合。本项目通过为OpenStack的网络实现一个可扩展的OpenFlow控制器Plugin,试图解决早期OpenFlow控制器在扩展性方面的缺陷。
一、简介
云计算越来越普及,云提供的弹性和服务的动态提供日益受人瞩目。随着OpenStack项目的出现,云平台的创新也越来越容易。最初OpenStack项目由instance管理项目(Nova),object存储项目(Swift)和image repository项目(Glance)组成,网路部分由Nova提供flat network配置和VLAN隔离,并没有受到太多关注。这种简单的网络能力使得租户很难设立多级网络(flat networking模式),同时没有扩展性可言。
从Quantum项目开始,OpenStack在接口设备(比如vNIC)间提供“网络连接即服务”。Quantum使得租户可以轻松建立虚拟网络,模块化的架构和标准的API可方便实现防火墙和ACL的Plugin。在大量涌现的Plugin中,和网络最相关的就是OpenFlow控制器RYU的plugin,但是RYU开源的Plugin缺乏云计算最基本的特性:扩展性。本项目将为Quantum设计一个更具扩展性的openflow plugin,同时利用SDN的集中控制,我们还会演示基于控制器的虚机迁移应用。
二、实现方法
Floodlight是基于Java的OpenFlow控制器,来源于Stanford大学最早开发的Beacon控制器(另一个最早的控制器是NOX),本项目选择Floodlight是因为它是一款相对简单又具有较高性能的控制器,不过本项目采用的方法可同样适用于其它控制器。
OpenFlow开源控制器RYU提供和本项目类似的Plugin,实现了逻辑上的集中控制和API,便于创建新的网络管理和控制应用。RYU进行租户的2层网络隔离不是通过VLAN,而是为VM内部通信建立单独的流,有实验表明这种方法在数据中心网络不具有扩展性,因为它会很快耗尽交换机的内存资源。
我们基于Floodlight为Quantum开发一款扩展性更好的OpenFlow Plugin。最初选择Floodlight是因为它是一款高性能的企业级控制器(译注:非常遗憾Floodlight已经停止更新)。不过本项目的方法可以很容易应用于其他标准的OpenFlow控制器。
我们的Plugin将来自Quantum API的建立/更新/删除网络资源的请求传递给底层网络。除了Plugin,每一个Nova VM会加载一个Agent用来处理该VM的虚拟接口的创建,并将它们与Quantum网络对接。我们的方案利用支持OpenFlow的OpenvSwitch(OVS)来提供Quantum所需的底层网络,并通过Floodlight控制器对OVS进行配置。
1 挑战
为Quantum提供OpenFlow控制器Plugin的最大挑战就是扩展性。RYU开源的Plugin为所有的VM间流量创建流,当流的数目超过OpenFlow交换机TCAM支持的最大条目后扩展性就会成为问题。
本方法采用更具有扩展性的VLAN方案对租户网络进行隔离。我们知道VLAN同样有扩展性的限制,因此,后续方案开发可以考虑新的封装协议比如VXLAN。
2 架构
Quantum的Plugin用来处理网络建立请求,它将来自Quantum的网络ID转换为VLAN并将这个转换关系维护在数据库中。Plugin负责OVS Bridge的创建,记录逻辑网路模型。Agent和Plugin同时纪录进入网络的端口,通知Floodlight有新的流量进入网络。基于网络端口的分配情况和端口的源MAC地址,流量被控制器加上VLAN ID标签。一旦加上标签后,网络流量就基于传统的learning switch进行转发。因此,通过VLAN标签和OpenFlow的控制我们就可以基于租户进行VM流量的隔离。
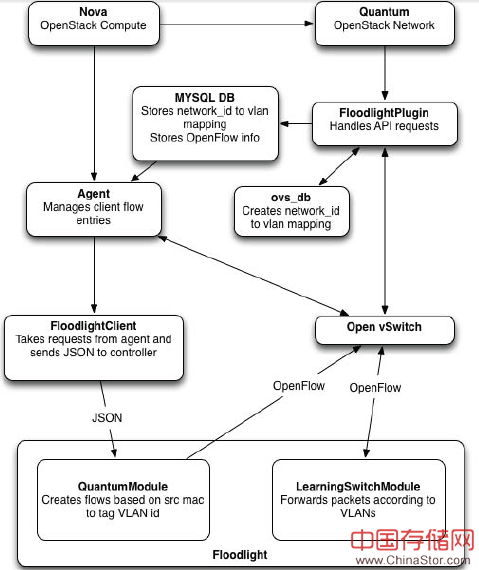
上图所示为Plugin的架构。租户通过nova-client将指令传递给Quantum管理单元,管理单元再将这些Call传递给真正执行创建/读取/更新/删除(CRUD)功能的控制器Plugin。Plugin通过在每个租户的网络ID和VLAN ID间建立映射关系实现上述功能。每当有新的端口加载于Quantum网络,Plugin就会相应地添加端口到OVS-bridge,保存端口和VLAN ID间的映射关系。最后,以Daemon形式运行于每个Hypervisor之上的Quantum agent不断轮询数据库和OVS Bridge,当有变化发生时就通知Floodlight Client,Client采用RESTful API告知Floodlight控制器模块。这样控制器就获取了端口、网络ID和VLAN ID的映射关系。当到达OVS的新报文没有任何entry时,报文会送到控制器做决策。然后控制器会推送一条规则到OVS告知其采用哪个VLAN ID来标记报文以及封装报文所用的物理主机地址。另外,控制器还会为物理交换机增加一条规则,动作为按照普通报文处理流程处理报文,所以报文的转发将会按照基本的Leaning Switch方式。通过这个方法每个物理交换机所需的TCAM条目数与通过交换机的VLAN数目成正比。
3 分析对比

本节分析对比上述方法与RYU方法在流表数目上对交换机的需求。假定每个服务器有20个VM,每个VM有10条并发流(出入各5条)。在这样的设定下,如果采用RYU的方法VM-VM间的流不具有扩展性。上图所示为两种方法的对比图。假定RYU的匹配规则基于VM的源和目的地址,因此ToR交换机需要在TCAM中存储20 servers/rack x 20 VMs/server x 10并发流/VM = 4000条流表。然而在我们的方案中基于每个报文的VLAN标签可对流表进行聚合,即使在物理交换机上每个VM都有一条匹配规则(这里假定最坏情况即服务器上的每个VM都属于不同的租户),需要存储在交换机TCAM中的流表条目数也只有400条,可以下降十倍以上。
4 管理应用示例:VM迁移
OpenFlow和我们的OpenStack Plugin实现网络的全局视角以及对转发行为的直接控制,因而可以简化操作管理。接下来我们提供一个应用案例:VM迁移。
高速无缝的VM迁移是数据中心实现负载均衡、配置管理、能耗节约等提升资源利用率的重要手段。但是VM迁移需要更新网络状态,可能导致冲突、业务中断、环路以及SLA不达标等一系列问题,因此VM迁移对服务提供商来讲始终是一个挑战。SDN为解决这些棘手问题提供一个强有力的手段:在逻辑上集中的控制器位置运行算法和可精确控制交换机转发层面的能力有助于在两个状态间切换网络。
本方法特别解决以下问题:对于分别由带有特定转发规则的交换机组成的起始网络和目标网络,我们是否可以设计出一套OpenFlow指令将起始网络状态转换到目标网络,同时保持某些状态比如路径无环以及保证带宽。这个问题可以分解为两个小问题:确定VM迁移的顺序或者规划排序;对于每一个要迁移的VM,确定要执行或者丢弃的OpenFlow指令的顺序。
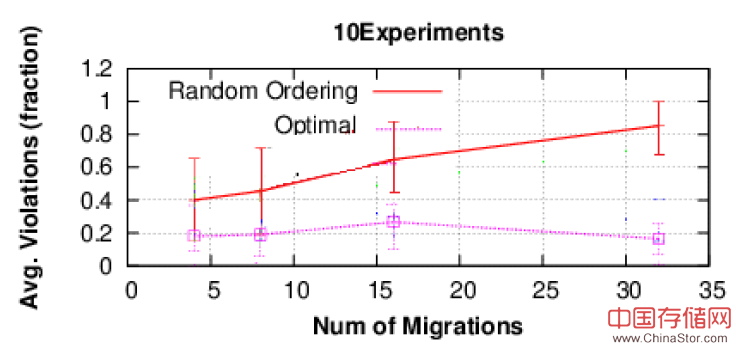
为了在有正确性保证的情况下进行迁移,我们测试了最佳算法(用来从所有可能的迁移顺序组合中确定导致最少冲突的排序)的性能。算法可以计算出VM迁移的排序以及一系列的转发状态改变。 算法运行在SDN控制器之上所以可以编排整个网络的改变。为了评估设计的性能,我们在真实的数据中心用虚拟的网络拓扑仿真性能。对于各种负载情况,算法可以大幅提高迁移的随机排序性能(80%以上)。
在共享的物理数据中心分配虚拟网络已经有很多研究,本项目借用这些工作中物理底层网络和VN的拓扑和设置。另外,对于底层拓扑,我们测试了用于随机图、树、胖树、D-Cell和B-Cube的算法。对于VN,我们采用Web服务应用常见的星形、树和3-tier图。在迁移前最初分配VN时,我们使用了SecondNet的算法。
我们随机选择虚拟节点来进行迁移,从有空余资源的底层节点任意选择目的网络。在其他场景下当需要不同的节点或目标选取策略时或许会影响算法的性能,基于本算法可以继续进行研究。
迁移平台基于Intel的Core i7-2600K,16GB内存。图3实验为200个节点的树,链接带宽为500MB,VN为9节点树,链路带宽为10MB。如图所示,采用最佳算法后冲突比例保持在30%以下,而某些随机排序下则接近100%。
三、扩展工作:VXLAN
随着VXLAN等新的协议出现,扩展多租户云网络的其他方法也可以被应用于Plugin的通信底层机制。
VLAN(IEEE802.1q)传统上常被用于为云中的不同租户和组织提供隔离机制。虽然VLAN通过将网络分隔为独立的广播域解决了2层网络的问题,但是它无法提供敏捷的服务,可支持的host数目有限。因此,服务需要扩展时不得不适配不同的VLAN,导致服务的分隔。另外,在手工配置的情况下,VLAN配置很容易出错,难于管理。虽然可以借助于VLAN管理策略服务器(VMPS)和VLAN trunking协议(VTP)自动化地配置access端口和trunk端口,但是网络管理员很少采用VTP,因为在这种情况下,管理员必须将交换机分为不同VTP域,域中的每一个交换机必须加入域中所有的VLAN,造成不必要的负担。再加上VLAN头只提供12位的VLAN ID,网络中最多有4096个VLAN。考虑到VLAN广泛的用途,这个数目难堪重任。数据中心虚拟化后进一步增大对VLAN的需求。虚拟可扩展VLAN(VXLAN)是IETF推出的标准,试图通过引入24位的VLAN网络标识符(VNI)来消除VLAN的限制,也就是说VXLAN可在网络中创建16M个VLAN。VXLAN主要利用hypervisor中软交换(或者硬件接入交换机)的虚拟隧道端点(VTEP)并将与VM相关的VNI和报文进行封装。VTEP基于IGMP协议加入多播组,这有助于消除未知的单播flood。
限制:VXLAN中16M个VLAN将超过多播组的最大数目,所以属于不同VNI的多个VLAN可能共享同一多播组。这可能导致安全和性能的问题。
四、总结
基于OpenFlow交换机部署OpenStack可充分体现SDN的优势。本项目实现了可扩展的Quantum/Neutron网络Plugin,同时为后续进一步基于VXLAN等新封装协议优化改善Plugin提供了设计方向。
译自:Pica8公司杨勇涛编译