众所周知,全球数据正以一种爆炸式的方式急速增长,高昂的设备扩容和快速上升的设备能源消耗导致数据中心的部署和运营成本直线上升。低成本、低功耗、高密度已成为计算和存储的共性需求,业界有越来越多的企业开始设计和部署 ARM 架构的服务器。
有别于相对高成本的 ARM 服务器芯片(如 Qualcomm, Cavium 等)用于 Cloud computing 的部署,WDLabs 在 2016 年上半年搭建了 504 个 Ceph OSD 节点的 ARM
测试储存池, 该方案采用了 504 片低成本的 ARM 芯片作为微服务器(Microserver)节点。4 年前,集成 ARM 芯片于硬盘, Seagate 首推了以太网硬盘,并开放了以Kinetic 命名的存储 API,作为其软件定义存储的解决方案。
目前 Ceph 是软件定义存储中最有影响力的开源项目之一,也是唯一一种可以同时提供块,文件和对象存储的开源解决方案。本文将重点介绍在 Celluster 公司提供的1U12 上部署 Ceph 集群,并初步探讨在 ARM 分布式架构上的 Ceph 性能分析。
方案介绍
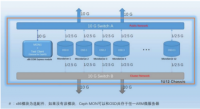
1U12 标准机框集成了 12 个 ARM 微服务器(主芯片采用最新量产的低成本低功耗
Marvell Armada3700/3720 芯片, 主频 1.0Ghz 的双核 A53,功耗低至 1.8W ),每个微
服务器搭载一块硬盘,其两个 1G/2.5G 网口分别连接至两个以太网交换机。框内同时留
有 Com Express 接口,可选配一块 TDP 不高于 45w 的 x86 模块。
该方案主要面向 throughput 和 capacity 成本优化的存储应用场景。
1U12 实景图

1U12 系统配置

1U12 CEPH 软件配置
Ceph Version: Jewel 10.2.3
(因 Jewel 10.2.3 之后的版本 ARM Cluster 与 x86 Client 之间交互有如下已知问题
http://tracker.ceph.com/issues/19705#change-99497,最新的 Luminous 12.2.0 正在解决,所以本文选用 Jewel 10.2.3 搭建测试集群。 )
Deploy tool: ceph-deploy 1.5.35(缺省配置)
ceph.conf
cephadmin@1U12B:~$ cat /etc/ceph/ceph.conf
cephadmin@node1:~$ ceph -v
ceph version 10.2.3 (ecc23778eb545d8dd55e2e4735b53cc93f92e65b)
[global]
fsid = 7631be6c-d6ed-453c-87b2-c622304bd313
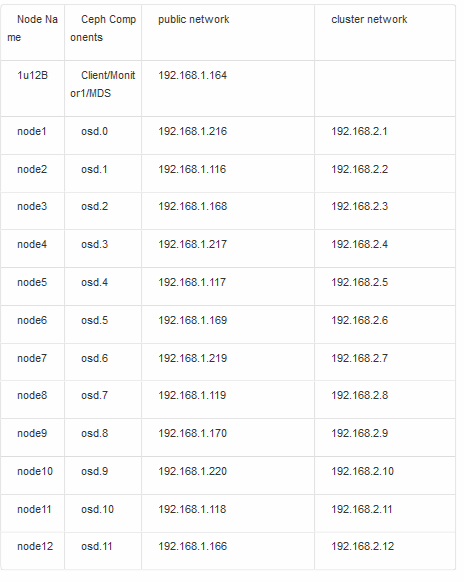
mon_initial_members = 1U12B
mon_host = 192.168.1.164
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd_pool_default_size = 3
osd_pool_default_min_size = 1
public_network = 192.168.1.0/24
cluster_network = 192.168.2.0/24
Network configuration:
CEPH 集群状态
cephadmin@1U12B:~$ ceph -s
cluster 0e2f70df-d1f6-419c-9686-22a8bef53370
health HEALTH_OK
monmap e1: 1 mons at {1U12B=192.168.1.164:6789/0}
election epoch 3, quorum 0 1U12B
fsmap e4: 1/1/1 up {0=1U12B=up:active}
osdmap e84: 12 osds: 12 up, 12 in
flags sortbitwise
pgmap v4243: 768 pgs, 3 pools, 17328 MB data, 10356 objects
52540 MB used, 22233 GB / 22285 GB avail
768 active+clean
测试一
按照上文配置从 3 节点依次增加到 12 节点,测试 CEPH 集群 RBD 块存储 4M 顺序读写
性能, 并分析测试数据。
存储接口: 使用 CEPH Block Device 接口测试
测试工具: 使用 FIO- 2.1.10(ioengine=rbd, direct=1,bs=4M)测试 CEPH 集群的块
存储的读写带宽

测试二
测试 12 个节点 CEPH 集群的 File System 接口性能,并与 RBD 接口性能进行比较
测试工具: 使用 FIO- 2.1.10(ioengine=libaio, direct=1,bs=4K/4M)测试

小结
当前测试环境下,从 3 节点到 12 节点,随着节点数增加,集群的 IO 性能几乎成线性增长,每增加一个节点 4M 读性能增加 40MB/s,4M 写性能增加 10MB/s
除了这组测试数据,我们还搭建了另一个 3 节点的集群,微服务器选用 2GB DDR3的配置,观察到 4M 的写性能达到 67MB/s,所以估测若选用 2GB DDR 的微服务器搭建集群,随着节点数的增加,写性能会有明显提升
观察 Block Device 接口与 File System 接口的测试结果,两种接口的读写性能几乎一致
今后优化思路
如对写性能的 throughput 有更高要求,可以升级 12 片微服务器模块上现有的 1GBDDR 至 2GB,Ceph 实测每个模块 buffer/cache 将从 0.4G 增长到 1.4G,每增加节点4M 写性能会提高到 20MB/s,预估整机写性能会有 30%~40%的提升
目前测试时使用 Ceph Jewel 10.2.3 缺省配置,每个 OSD 的微服务器 CPU 在最高峰值压力测试情况下尚有 30%的空闲,留给软件进一步优化的可行性