2022 年 4 月 8 日 — 著名的开放工程联盟 MLCommons 发布了领先的 AI 基准套件 MLPerf Inference v2.0 的结果。浪潮AI服务器在数据中心封闭分部的16项任务中均创下纪录,在现实世界的AI应用场景中展现了最佳性能。
MLPerf 由图灵奖获得者大卫帕特森和顶级学术机构共同创立。它是全球领先的人工智能性能基准,每年组织两次人工智能推理和人工智能训练测试,以跟踪和评估快速增长的人工智能发展。MLPerf 有两个部门:Closed 和 Open。封闭部门提供了供应商之间的苹果对苹果的比较,因为它需要使用相同的模型和优化器,使其成为一个极好的参考基准。
MLPerf 2022 年首个 AI 推理基准测试旨在检验不同厂商的计算系统在各种 AI 任务中的推理速度和能力。数据中心类别的封闭部门是最具竞争力的部门。总共提交了 926 个结果,是之前基准的两倍。
浪潮人工智能服务器刷新推理性能记录
MLPerf AI 推理基准涵盖六种广泛使用的 AI 任务:图像分类 (ResNet50)、自然语言处理 (BERT)、语音识别 (RNN-T)、对象检测 (SSD-ResNet34)、医学图像分割 (3D-Unet) 和推荐(DLRM)。MLPerf 基准测试需要超过原始模型 99% 的准确度。在自然语言处理、医学图像分割和推荐方面,设定了 99% 和 99.9% 两个准确率目标来考察提高 AI 推理质量目标时对计算性能的影响。
为了更紧密地匹配实际使用情况,MLPerf 推理测试对数据中心类别有两个必需的场景:离线和服务器。离线场景意味着任务所需的所有数据都在本地可用。服务器场景在请求时以突发形式在线交付数据。
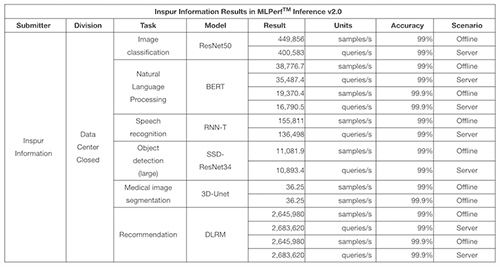
浪潮AI服务器在ResNet50模型任务中创下了每秒处理449856张图像的性能记录,相当于仅用2.8秒就完成了ImageNet数据集中128万张图像的分类。在3D-UNet模型任务中,浪潮创下了每秒处理36.25张医学图像的新纪录,相当于在6秒内完成了KiTS19数据集中207张3D医学图像的分割。在SSD-ResNet34模型任务中,浪潮创下了每秒完成目标物体识别识别11081.9张图像的新纪录。在 BERT 模型任务中,浪潮创下了平均每秒完成 38,776.7 个问答的性能记录。在RNNT模型任务中,浪潮创下了平均每秒完成155811次语音识别转换的记录,
在边缘推理类别中,浪潮针对边缘场景设计的人工智能服务器也表现出色。NE5260M5、NF5488A5和NF5688M6在封闭赛区17个任务中获得11个冠军。
随着人工智能应用的不断发展,更快的推理处理将带来更高的人工智能应用效率和能力,加速向智能产业的转型。与MLPerf AI inference v1.1相比,浪潮AI服务器在图像分类、语音识别和自然语言处理任务上分别提升了31.5%、28.5%和21.3%。这些成果意味着浪潮AI服务器可以在自动驾驶、语音会议、智能问答、智慧医疗等场景中更高效、更快速地完成各种AI任务。
全栈优化助力AI性能持续提升
浪潮AI服务器在MLPerf基准测试中的出色表现,得益于浪潮信息在AI计算系统方面出色的系统设计能力和全栈优化能力。
浪潮AI服务器NF5468M6J可支持12x NVIDIA A100 Tensor Core GPU,采用分层可扩展的计算架构,创下12个MLPerf记录。Inspur Information 还提供支持 8x 500W NVIDIA A100 GPU 的服务器,采用液冷和风冷。在本次基准测试中采用 8x NVIDIA GPU 和 NVLink 的高端主流机型中,浪潮 AI 服务器在数据中心类别的 16 项任务中的 14 项中取得了最佳成绩。其中,NF5488A5在4U空间内支持8x第三代NVlink A100 GPU和2x AMD Milan CPU。NF5688M6 是一款人工智能服务器,具有为超大规模用户优化的极端可扩展性。它支持 8 个 NVIDIA A100 GPU 和 2 个 Intel Icelake CPU,并支持多达 13 个 PCIe Gen4 IO 扩展卡。
在边缘推理类别中,NE5260M5 配备优化的信号和电源系统,并广泛兼容高性能 CPU 和各种 AI 加速卡。采用减震降噪设计,并经过严格的可靠性测试。机箱深度为 430 毫米,几乎是传统服务器深度的一半,即使在空间受限的边缘计算场景中也可部署。
浪潮AI服务器通过CPU和GPU硬件的精细校准和综合优化,优化了CPU和GPU之间的数据通路。在软件层面,通过基于 GPU 拓扑增强多 GPU 的循环调度,可以使单 GPU 或多 GPU 的性能接近线性提升。在深度学习方面,基于英伟达 GPU Tensor Core 单元的计算特性,通过浪潮自研的通道压缩算法实现模型的性能优化。
要查看 MLPerf Inference v2.0 的完整结果,请访问
https://mlcommons.org/en/inference-datacenter-20
https://mlcommons.org/en/inference-edge-20