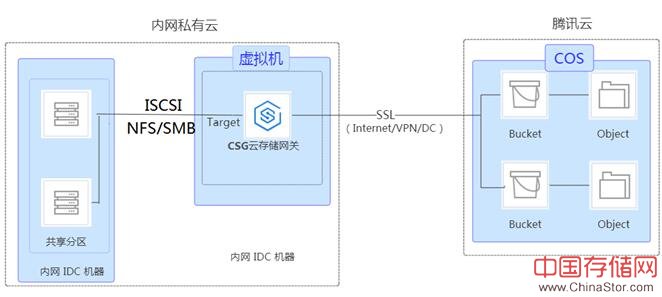
中存储网消息,CSG存储网关是基于腾讯云高性能、高可靠性的对象存储系统COS对外提供iSCSI、NFS和CIFS/SMB访问协议。作为一种混合云方案, 帮助用户不用修改本地应用就可以把数据上传到COS。网关可以部署在用户IDC也可以部署在腾讯云上,产品形态如下所示。
1.缓存命中率和延时是技术上两大挑战,
网关和COS之间需要走外网来通讯,外网网络存在延时高、抖动和丢包等问题,而且还会占用客户大量带宽。
实际场景下,我们发现用户经常访问的数据只是一小部分热点数据,存在局部性特点,因此如果能在网关上加一层缓存且缓存命中率足够高的话,理论上网关就可以达到接近本地磁盘的读性能,也可以减少对带宽占用。
缓存的大小受容量的限制只能保存一部分热点数据, 需要根据场景选择合适的缓存算法。评价缓存系统好坏一般通过命中率和延时两个指标,缓存算法一般都是在两者间权衡。影响命中率的关键就是缓存替换算法,而延时主要跟并发锁设计关于。一般缓存系统采用一把大的全局锁,对于CSG采用本地磁盘作为存储介质的系统,普通的SATA盘延时差不多10ms左右,如果采用全局锁最多只有100qps/s, 因此需要对锁进行优化。
2. 业界现有技术实现过程及弊端解析
业界普遍的做法是采用缓存替换算法是LRU,例如Linux内核page cache、 memcached等。典型的实现方式是hashtable + 双链 + 全局锁的方式,但是这种实现存在两大问题:
所有的操作都需要加全局锁造成并发低,延时高
对于数据访问局部性差的场景命缓存失效中率低,比如顺序扫描
针对这两个问题常见的实现改进思路是:
牺牲LRU特性,即减少节点移动到head的次数, 从而降低全局锁的竞争,但是可能会造成热点数据被淘汰
LRU链表分两段或多段,基于一定的访问策略解决局部性差的场景
memecached 和page cache也是基于这两种改进思路优化的,下面分析下memecached 和page cache的具体实现细节。
memcached 的LRU算法实现:
每个节点一把锁保护节点数据和索引
LRU链表分为hot、warm和cold三个子链表,大小比例为 32:32:34
每个子链表一把全局锁,maintainer 线程根上述比例维持链表长度时要加全局锁
节点访问时只需要加节点锁同时标记为active 并不移动解决了锁冲突问题,而且分三个子链表配合制定的访问策略解决了局部性差的场景。但是只是由maintainer 线程根据 active 向中存储网记者表示来判断是否移动到 head, 过度的牺牲LRU特性会造成热点数据被淘汰导致命中率低。
page cache 的LRU实现:
全局锁(zone锁)
LRU链表分为activate和inactivate两个子链表, 比例为1:1
也是采用分两个子链表解决了局部性差的场景, 但是依然采用的是全局锁没有对锁做优化。
memecached 和page cache的实现针对局部性差的场景都是采用拆分链表的方式。针对全局锁的问题memecached 中虽然采用了节点锁,但是过度的牺牲LRU特性会造成缓存命中率低。
3. 高性能腾讯云CSG技术背后细节
CSG在实现的参考了这两个方案的优缺点,希望能够在并发性能的和缓存的命中率之间到达平衡, 具体实现如下:
hashtable每个bucket一把锁保护节点和索引,一把全局锁保护LRU链表
链表由midpoint指针分为hot 和cold两个子链表,默认的节点数比例是 2:1
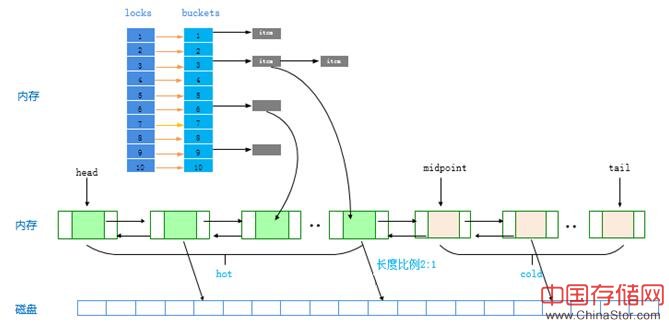
CSG也是通过midpoint把LRU链表划分为hot 和cold两个子链表来解决局部性差场景。锁的优化采用的是段锁+全局锁,对节点的访问是先加段锁访问数据,移动节点时才加全局锁,把全局锁的临界区控制到了最小范围。这样即保证了LRU特性提升了缓存命中率而且锁冲突也不严重, 实际测试4线程加全局锁修改链表可以达到50w+/s的并发满足了需求。
如上图所示我们实现的段锁hashtable是对每一个bucket一把锁,对hash到同一个bucekt的key加同一锁,多线程并发锁冲突小并发高。hash冲突时采用的链式冲突处理, 当load_factor > 1.0时会自动进行resize,保证key和 bucket锁得比例小于1:1。
下图是多线程情况下跟stl 中unordered_map 加全局锁性能对比数据,测试环境4 cpu + 8G mem。
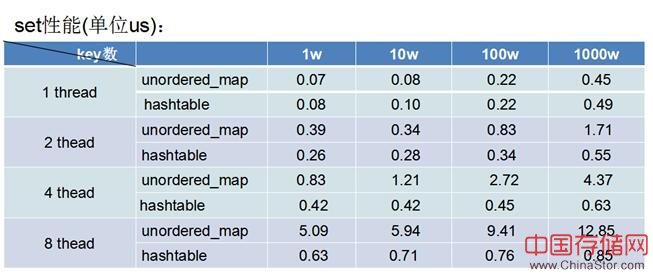
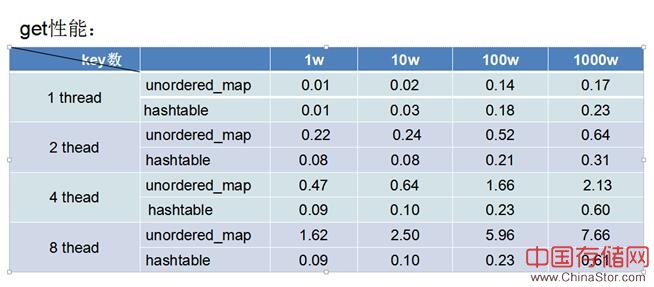
对比发现即使单线程性能也差不多10%的性能损耗,4线程下是unordered_map的两倍以上, key越多锁冲突越少并发性能也越好。
4. 与竞品读性能对比
测试环境:4cpu + 16Gmem + 1G网卡 平台: cvm + CBS(普通盘100G)+ 卷 500G
测试工具:fio -ioengine=libaio -iodepth=128 -direct=1 -rw=randread -bs=[32k|64k|512k]
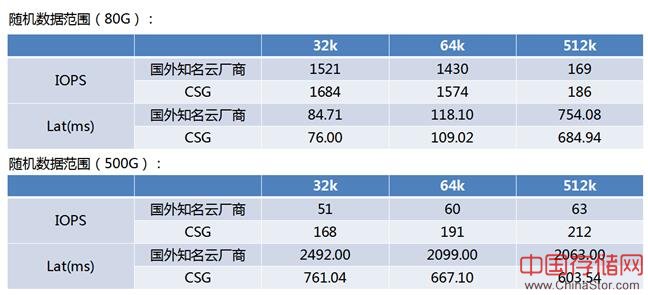
数据对比在局部性比较好的场景随机范围80G,CSG的延时比国外知名云商低10%左右。局部性比较差的场景随机范围500G, CSG 读随机IOPS是竞品3倍。