VMware在今年4月份突然发布了业内第一个开源的PaaS——Cloud Foundry。发布至今的这几个月里,笔者一直关注它的演进,并从它的架构设计中获益良多,觉得有必要写出来与大家分享一下。
本文会分为两个部份:第一部份主要介绍Cloud Foundry的架构设计,从它所包含的模块介绍起,到各部份的消息流向,各模块如何协调合作;第二部份会在第一部份的基础上,以如何在你的数据中心里面用Cloud Foundry部署一个私有PaaS为目标,把第一部分介绍到的架构知识使用起来。
第一部份讲的很多内容,会引用Pat在10月12日的VMwareCloud Forum上面关于Cloud Foundry架构的演讲。Pat是Cloud Foundry Core的负责人,他的那次演讲很值得一听。如果你当时在场,并且理解他所说的内容,本部份可以选择直接跳过。我除了会把说的内容讲具体点外,不太可能可以讲得比他好。
一、架构及模块
从总体地看,Cloud Foundry的架构如下:
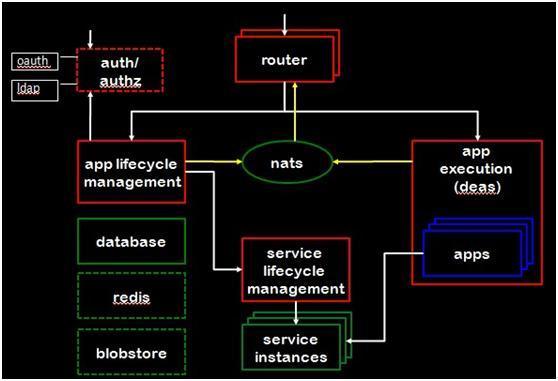
这个架构图以及下文所用到的各模块架构图均来自Pat的PPT。从上图能够看到Cloud Foundry主要有以下几大组件组成:
1、 Router:顾名思义,Router组件在Cloud Foundry中是对所有进来的Request进行路由。进入Router的request主要有两类:首先是来自VMCClient或者STS的,由Cloud Foundry使用者发出的,管理型指令。
例如:列出你所有apps的vmcapps,提交一个apps等等。这类request会被路由到AppLife Management组件,又叫CloudController组件去;第二类是外界对你所部署的apps访问的request。这部份requests会被路由到Appexecution,又或者叫做DEAs的组件去。所有进入Cloud Foundry系统的requests都会经过Router组件,看到这里可能会有朋友会担心Router成为单点,从而成为整个云的瓶颈。
但是Cloud Foundry作为云系统,其设计的核心就是去单点依赖,组件平行扩充,且可替代的以保证扩展性,这是Cloud Foundry,甚至所有云计算系统的设计原则,后文会讨论Cloud Foundry如何做到这点,目前只要知道,系统可以部署多个Routers共同处理进来的requests,但是Router上层的LoadBalance不在Cloud Foundry的实现范围,Cloud Foundry只保证所有的request是无状态的,这样就使上层均衡附载选择面非常非常大了,例如可以通过DNS做,也可以部署硬件的LoadBalancer,或者简单点,弄台ngnix作负载均衡器,都是可行的。
Router组件,目前版本是对nginx的一个简单封装。熟悉ngnix的朋友应该知道,它可以一个套接字文件(.sock文件)作为输入输出。所有安装Cloud Foundry的Router组件服务器都会安装一个nginx,其ngnix.conf文件有以下配置:

从整体的来看,Router组件的结构如下:

外界httprequest进入Cloud Foundry服务器,nginx会首先接到request,nginx通过sock与router.rb进行交互,于是真正处理请求的是Router组件。router.rb里面根据传入的url,用户名密码等,进行逻辑判断,到CloudController组件或者DEA组件取数据并且返通过与niginx连接的.sock文件返回。
router.rb是对nginx进行了逻辑封装。熟悉Cloud Foundry的朋友肯定知道,Cloud Foundry给每一个app分配了一个url访问,如果直接使用VMware所托管的Cloud Foundry.com的话,那你的app的url可能就是xxx.Cloud Foundry.com,无论通过命令给你的app扩展了多少个instances,都是从这个url访问的,这里面的url转换路由就是由router.rb实现的。
2、DEA(Droplet Execution Agency): 首先要解析下什么叫做Droplet。Droplet在Cloud Foundry的概念里面是指一个把你提交的源代码,以及Cloud Foundry配套好的运行环境,再加上一些管理脚本,例如Start/Stop这些小脚本全部压缩好在一起的tar包。还有一个概念,叫做Stagingapp,就是指制作上面描述这个包,然后把它存储好的过程。Cloud Foundry会自动保存这个Droplet,直到你start一个app的时候,一台部署了DEA模块的服务器会来拿一个Droplet的copy去运行。所以如果你扩展你的app到10个instances,那这个Droplet就被会复制十份,让10个DEA服务器拿去运行。
下图是DEA模块的架构图:
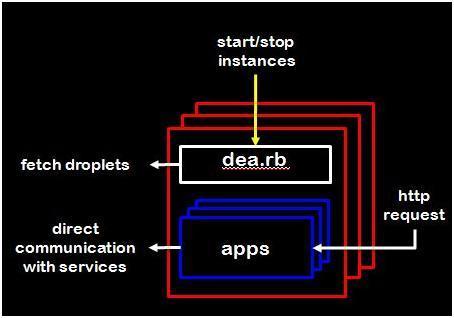
Cloud Controller模块(下面会介绍)会发送start/stop等基本的apps管理请求给DEA,dea.rb接收这些请求,然后从NFS里面找到合适的Droplet。前面说到Droplet其实是一个带有运行脚本的,带运行环境的tar包,DEA只需要把它拿过来解压,并即行里面的start脚本,就可以让这个app跑起来。到此,app算是可以访问,并start起来了,换句话说就是有这台服务器的某一个端口已经在待命,只要有request从这个端口进来,这个app就可以接收并返回正确的信息。
接着dea.rb要做些善后的工作:1、把这个信息告诉Router模块。我们前面说到,所有进入Cloud Foundry的requests都是由Router模块处理并转发的,包括用户对app的访问request,一个app起来后,需要告诉router,让它根据loadbalance等原则,把合适的request转进来,使这个app的instance能够干起活;2、一些统计性的工作,例如要把这个用户又新部署了一个app告诉CloudController,以作quota控制等;3、把运行信息告诉HealthManager模块,实时报告该app的instance运行情况。另外DEA还要负责部份对Droplet的查询工作,譬如,如果用户通过CloudController想查询一个app的log信息,那DEA需要从该Droplet里面取到log返回等等。
3、CloudController:CloudController是Cloud Foundry的管理模块。主要工作包括:
a) 对apps的增删改读;
b) 启动、停止应用程序;
c) Staging apps(把apps打包成一个droplet);
d) 修改应用程序运行环境,包括instance、mem等等;
e) 管理service,包括service与app的绑定等;
f) Cloud环境的管理;
g) 修改Cloud的用户信息;
h) 查看Cloud Foundry,以及每一个app的log信息。
这似乎有点复杂,但简单的说,可以很简单:就是与VMC和STS交互的服务器端。VMC和STS与Cloud Foundry通信采用的是restful接口,另一方面CloudController是一个典型的Rubyon Rails项目,从VMC或者STS接到JSON格式的协议,然后写入CloudController Database,并发消息到各模快去控制管理整个云。和其他ROR项目一样,CloudController的所有API可以从conf/routes.rb里看到。开放的Restful接口好处在于第三方应用开发和集成,企业在用Cloud Foundry部署私有云的时候,可以通过这些接口来自动化控制管理整个Cloud环境。这部份内容将在第二部份论述。
下图是Cloud Controller的架构图:
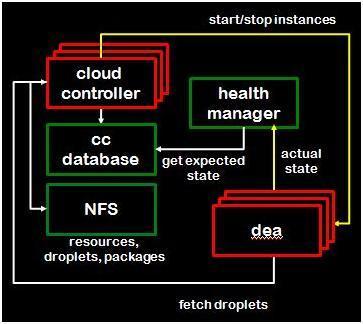
图中Health Manager和DEA是外部模块,CCDatabase就是CloudController Database,这个是整个Cloud Foundry不能做HP的地方。CloudController Database的并发性不会很多,应用级别的数据库访问是由底下的Service模块处理的,这个数据库存的是Cloud的配置信息。读操作主要来自DEA启动,作为初始化DEA的依据;以及healthmanager模块会从这里读取预期的状态信息,这部份数据会与从DEA得到的实际状态信息进行比对。
NFS是多个CloudController的共享存储,CloudController其中一个重要工作就是StagingApps。Droplets的存储是在集群环境的唯一的。而CloudController是集群运行,换言之,就是每一个控制Request可能由不同的CloudController处理,假设一个简单的用户场景:我们需要部署一个app到Cloud Foundry中。我们在敲完那条简单的push命令后,VMC开始工作,在做完一轮的用户鉴权、查看所部署的apps数量是否超过预定数额,问了一堆相关app的问题后,需要发4个指令:
1.发一个POST到”apps”,创建一个app;
2.发一个PUT到”apps/:name/application”,上传app;
3.发一个GET到”apps/:name/”,取得app状态,看看是否已经启动;
4.如果没有启动,发一个PUT到”apps/:name/”,使其启动。
如果第2和第4步由不同的Cloud Controller来处理,而又无法保证他们能找到同一个Droplet,那第4步将会因为找不到对应的Droplet而启动失败。如何保证这一连串指令过来所指向的Droplet都是同一个呢?使用NFS,使CloudController共享存储是最简单的方法。但是这个方法在安全性等方面并不完美。在10月12日的VMwareCloud Forum上,Pat告诉我们下一版本的Cloud Foundry这里将会有大调整,但是在那部份代码公开前,我不方便在这评价太多。
4、HealthManager: 做的事情不复杂,简单的说是从各个DEA里面拿到运行信息,然后进行统计分析,报告等。统计数据会与CloudController的设定指标进行比对,并提供Alert等。HealthManager模块目前还不是十分完善,但是CloudManage栈里面,自动化health管理、分析是一个很重要的领域,而这方面可以扩展的地方也很多,结合OrchestrationEngine可以使云自管理、自预警;而与BI方面技术结合,可以统计运营情况,合理分配资源等。这方面Cloud Foundry还在发展之中。
5、Services:Cloud Foundry的Service模块从源代码控制上看就知道是一个独立的、可Plugin的模块,以方便第三方把自己的服务整合入Cloud Foundry生态系统。在Github上看到service是与Cloud Foundry Core项目vcap独立的一个repository,为vcap-service。Service模块其中设计原则是方便第三方服务提供商提供服务。在这方面Cloud Foundry做得很成功,从Github上看,已经有以下服务提供:a)MongoDB; b) mysql; c) neo4j; d) PostgreSql; e) RabbitMQ; f) Redis; g)vBlob。基类都是放在base文件夹中。
第三方如果需要自己开发Cloud Foundry的服务,需要继承改写它里面的两个基础类:Node和Gateway;而里面一些操作,如:Provision,可以在base的provisioner.rb基础上加入自己的逻辑,同样的还有Service_Error和Service_Message等。关于如何写自己的Service,ELC的博客会推出相应文章详细论述,并不在本文的讨论范围里面,从架构了解上来说,只要知道服务间的关系,知道个服务与base间透过继承关系来横向扩充,而Cloud Foundry与apps调用Service是通过base来完成这一简单的架构方法即可。
6、NATS(Message bus): 从Cloud Foundry的总架构图看,位于各模块中心位置的是一个叫nats的组件。NATS是由Cloud Foundry的架构师Derek开发的一个轻量级的,支持发布、订阅机制的消息系统。Github开源地址是:https://github.com/derekcollison/nats。其核心基于EventMachine开发,代码量不多,可以下载下来慢慢研究。
Cloud Foundry是一个多模块的分布式系统,支持模块自发现,错误自检,且模块间低耦合。其核心原理就是基于消息发布订阅机制。每个台服务器上的每个模块会根据自己的消息类别,向MessageBus发布多个消息主题;而同时也向自己需要交互的模块,按照需要的信息内容的消息主题订阅消息。譬如:一个DEA被加入Cloud Foundry集群中,它需要向大家吼一下,以表明它已经准备好服务了,它会发布一个主题是”dea.start”的消息:

@ hello_message_json中包括DEA的UUID,ip, port, 版本信息等内容。
再例如,CloudController需要启动一个Droplet的instance:
a)首先一个DEA在启动的时候,会首先会对自己UUID的消息主题进行订阅。

其他模块需要通过’’dea.#{uuid}.start”这个主题发送消息来使它启动,一旦这个DEA接收到消息,就会触发process_dea_start(msg)这个方法来处理启动所需要的工作。
b)Cloud Controller或者其他模块发送消息,让UUID为xxx的DEA启动。

c)DEA模块接收到消息后,就会触发process_dea_start(msg)方法。msg是由其他模块发送过来的消息内容,包括:droplet_id,instance_index, service, runtime等内容,process_dea_start会取得这些启动DEA必须的信息,然后进行一系列操作,例如从NFS中取得Droplet,解压,修改必要环境配置,运行启动脚本等等。等一切都准备好后,然后需要给Router发个消息,告诉它这个Droplet已经随时准备好报效国家,以后有相应的request记得让它来处理。
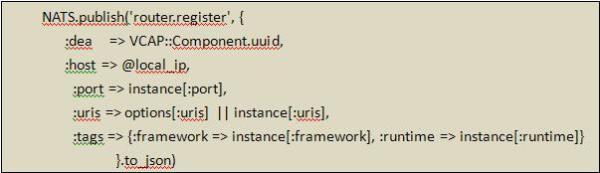
d)Router模块在启动时就已经订阅”router.register”消息主题。

收到前面DEA发出的信息后,会触发register_droplet方法,去绑定Droplet。到此启动一个Droplet的instance工作完成。
我们可以看到整个Cloud Foundry的核心就是一套消息系统,如果想了解Cloud Foundry的来龙去脉,去跟踪它里面复杂的消息机制是非常好的方法。另一方面,Cloud Foundry是一套基于消息的分布式系统,面向消息的架构是它节点横向扩展,组件自发现等云特性的基础。
Cloud Foundry的架构简单介绍至此,其实作为第一款开源的PaaS,Cloud Foundry架构有很多可以学习借鉴的地方,很多细节上的处理是很精妙的,这些内容如果有可能会在后续文章继续探讨,本文题虽为深入Cloud Foundry,其实也只是浅尝即止,把总体架构介绍一下,目标在于使我们有足够的背景知识去用Cloud Foundry搭建企业内部的私有PaaS。总结一下,笔者从Cloud Foundry的结构中学到的东西:
1、基于消息的多组件架构是实现集群的简单、且有效方法。消息可以使集群节点间解耦,使自注册,自发现这些在大规模数据中心中很重要的功能得到实现;
2、适当的抽象层,模板模式的使用,方便第三方可以方便在Cloud Foundry开发扩展功能。Cloud Foundry在DEA及Service层都做了抽象层处理,相对应地使开发者可以容易地为Cloud Foundry开发Runtime和Service。例如,在Cloud Foundry刚推出的时候,只支持Node.js,Java, Ruby,但第三方提供商、开源社区快速跟进,为Cloud Foundry添加了PHP,Python的支持。这得益于Cloud Foundry精巧的DEA架构设计,如何开发新的Runtime支持,会在后续博文中有所论述.
二、源码导读
笔者一直觉得深入理解一个技术的最好方法就是读它的源码,而Cloud Foundry是完全开源的PaaS平台,而因为刚发展起来,代码量不多,主要作者们的代码功力也相当不错,读起来很舒服,很适合研读。而不得不再次表扬一下它完全基于消息机制的架构设计,对组件扩展性,第三方接入等方面做得很好,读者可以从中学到不少思想性的东西。笔者很推荐大家去读一下它的源代码。你可以在Github上找到Cloud Foundry的全部代码:https://github.com/Cloud Foundry,你会看到几个不同的Repositories,它们分别是:
1、vcap: Cloud Foundry的Core,又或者称作Kernel;
2、vcap-service: Cloud Foundry的Service组件。Cloud Foundry的service是作为插件提供的,这出于它方便第三方开发service而设计的;
3、vmc: VMware Cloud CLI. 是一个Ruby应用,与Cloud Foundry的CLI交互。主要通过分析用户输入的CLI,向Cloud Foundry发送Restful请求;
4、vcap-java: 如果你的app是用java开发,且需要与Cloud Foundry交互,例如取得当前serviceserver的ip地址等,你可能需要这个jar,里面对我们Java开发常用框架有所支持,它底层也是对Cloud Foundry的Restful请求的包装;
5、vcap-java-client: Cloud Foundry的Restful API的Java封装,与上面的项目不一样,它只是个简单的读取Cloud Foundry信息,并放如JavaBean中;
6、vcap-test: Cloud Foundry的test cases;
7、vcap-test-assets: Cloud Foundry一些apps示例。