通过使用Elastic Load Balancing(ELB)访问日志,管理员拥有大量的数据来描述通过ELB的流量。虽然搭配Amazon Elastic MapReduce(Amazon EMR)和相关工具也可以对ELB持续产生的大量日志数据进行分析,但是这里还存在一些数据和分析技巧。大部分情况下,分析ELB日志是为了处理一些错误,因此这些快速分析TB级日志的技巧对于技术团队来说至关重要。
幸运的是,搭建Amazon Redshift集群来加载ELB访问日志并使用SQL查询进行分析非常简单。本文将介绍如何使用Amazon Redshift便捷地分析这些日志数据,无论是临时用来响应一个事件,或者是进行周期性的分析。不管是TB或者是PB数据,通过Amazon Redshift都可以快速的提供一个数据仓库集群,并行的存入大量数据,并通过ODBC/JDBC PostgreSQL接口访问,因此对于ELB日志分析来说,Amazon Redshift是一个相当不错的SQL-based解决方案。如果你有大量的 Amazon EMR使用经验,并且喜欢使用MapReduce风格来分析你的数据,Amazon已经提供了一个将ELB日志加载到EMR的向导。
确定你的日志文件
第一步,确定你期望分析的日志,并设置适当大小的 Amazon EMR集群进行保存,这主要决定于你需求分析的周期时间,下面这些步骤可以帮助你确定对应的日志文件。在Amazon ELB日志保存的Simple Storage Service (Amazon S3) bucket中,你可以发现下图这个目录记录:

图1
从图1,能了解到2014年3月5日East区域的日志可以在以下目录找到:
s3://corporation-com-elb-logs/ AWSLogs/515290123456/elasticloadbalancing/us-east-1/2014/03/05
因此,你可以使用以下目录来指定3月份East区域的所有日志
s3://corporation-com-elb-logs/ AWSLogs/515290123456/elasticloadbalancing/us-east-1/2014/03
在每天的文件中,都存在一个以上的对象。为了获取文件夹的大小,你既可以使用控制台手动地添加所有对象的大小,也可以使用下面这个CLI命令(使用bucket name替换掉下面这个yourbucket,以及使用account number替换掉youraccount#):
aws s3 ls s3://yourbucket/AWSLogs/youraccount#/elasticloadbalancing/us-
east-1/2014/03/16--recursive | grep -v -E "(Bucket: |Prefix: |LastWrite
Time|^$|--)" | awk 'BEGIN {total=0}{total+=$3}END{print total/1024/
1024" MB"}'
使用下面命令来确定3月日志文件的大小:
aws s3 ls s3://yourbucket/AWSLogs/youraccount#/elasticloadbalancing/us-
east-1/2014/03--recursive | grep -v -E "(Bucket: |Prefix: |LastWriteTim
e|^$|--)" | awk 'BEGIN {total=0}{total+=$3}END{print total/1024/1024"
MB"}'
无论使用什么方法,必须计算出你需要加载数据的大小。
发布一个Amazon Redshift集群
下一步,你需要设置Amazon Redshift集群来保存弹性负载均衡器的访问日志数据。首先,你需要登入AWS控制台,并且从服务菜单中选择Redshift。
图2
作为发布集群的一部分,你必须建立一个安全组(security group ),它将允许你使用SQL客户端访问数据时阻断其他所有流量。从一个指定的CIDR块或者Amazon Elastic Cloud Compute (Amazon EC2)安全组,安全组可以访问你的Amazon Redshift集群。下一步就是安装SQL客户端,确定一个主机然后创建恰当的安全组规则。如果你期望在Amazon EC2 实例上安装安全组,你需要保护这个实例的安全组。如果你希望从本地工作站中运行,你需要这个工作站在网络中的IP地址(或者IP范围)。
在识别你的客户端主机后,在Amazon Redshift页面左边菜单中点击Security按钮,然后在Security Groups标签中,点击蓝色的Create Cluster Security Group按钮。
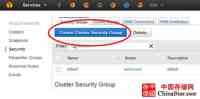
图3
在Cluster Security Group对话框中,建立下表中的字段:

表格1
完成上面这个操作后,点击建立。
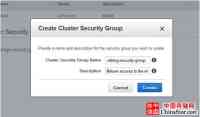
图4
安全组最初会阻断所有流量。你必须建立一个规则,从而为需要使用的集群允许指定的传输。为你的新组选择指定的类型,然后在下拉框Connection Type中选择CIDR/IP。
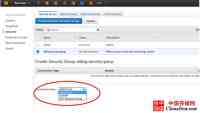
图5
在下一个界面中,填写如下字段:
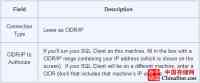
表格2
填好字段后,点击Authorize。
图6
注意:之前的指令通过IP地址(不管是本地工作站,还是Amazon EC2实例)确定了你的SQL客户端。如果你使用的是一个Amazon EC2实例,给实例分配一个安全组可以通过在Connection Type下拉框中选择EC2 Security Group来完成。
到这里,安全组建立完成后,是时候建立你的集群了。在左边的菜单栏中点击Clusters链接,在下一个界面,点击蓝色的Launch Cluster按钮。
图7
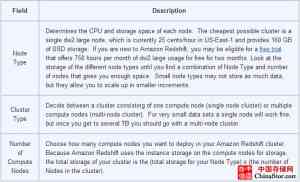
在集群详情页面中,填写好下表的字段:
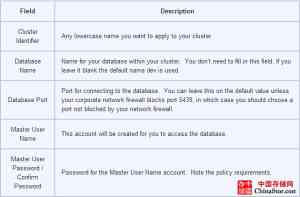
表格3
在填好所需字段后,点击下一步。

图8
在Review界面中,检查你的设置。同时,在集群发布前,你还可以看到费率。如果所有设置正确,你对费率也比较满意,点击Launch Cluster发布你的集群。
表格4
你的集群需要几分钟来发布,一旦集群建立,下一步则需要设置PostgreSQL客户端。
设置PostgreSQL客户端
为了操作你的Amazon Redshift集群(举个例子,建立表格、导入数据以及做查询),你需要建立一个PostgreSQL客户端。这里有几个选项,比如:
RazorSQL:一个具有30天试用期的产品,内置JDBC驱动。(http://www.razorsql.com)
SQL Workbench/J:一个免费的PostgreSQL客户端。AWS提供了建立PostgreSQL客户端的向导。(滚屏以Install SQL Client和Drivers)
将ELB日志导入Amazon Redshift
回到Amazon Redshift主页(在Services页面中点击Redshift),并点击左边菜单中的Clusters按钮。当你的集群就绪后,Cluster Status会显示“就绪”字样。
图9
如果想浏览你的集群详情,点击集群名称边上的 Info图标来打开如下界面。
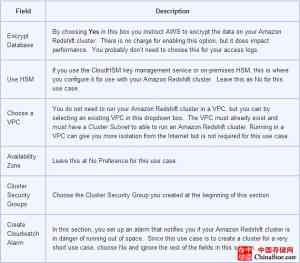
表格5
这个页面上的重点信息是访问数据库的JDBC和ODBC URLs(上图高亮了JDBC)。
打开你的Amazon Redshift客户端,随后打开你可以建立新链接的界面。下面以SQL Workbench/J为例,但是使用其他心仪的SQL客户端也不会有难度。在下图,注意显示Cluster Details的页面。URL字段包含了上面Cluster Info屏幕我们说到的JDBC URL。通过这些指派来打开Amazon Redshift集群的一个会话。
图10
在连接到你的Amazon Redshift后,你可以通过PostgreSQL和Amazon Redshift指令来操纵它。首先,建立一个表格,用它来保存访问数据。使用如下的CREAT TABLE命令来建立表格:
CREATE TABLE elb_logs (
RequestTime DateTime encode lzo,
ELBName varchar(30) encode lzo,
RequestIP_Port varchar(22) encode lzo,
BackendIP_Port varchar(22) encode lzo,
RequestProcessingTime FLOAT encode bytedict,
BackendProcessingTime FLOAT encode bytedict,
ClientResponseTime FLOAT encode bytedict,
ELBResponseCode varchar(3) encode lzo,
BackendResponseCode varchar(3) encode lzo,
ReceivedBytes BIGINT encode lzo,
SentBytes BIGINT encode lzo,
Verb varchar(10) encode lzo,
URL varchar(2083) encode lzo,
HttpVersion varchar(10) encode lzo
)
sortkey(RequestTime) ;
注意:上图的代码指定了每个数据列的压缩方式。在以后设计表格的过程中,Amazon Redshift的COPY命令在第一次加载时可以为每列自动选择适当的压缩算法,这个操作基于你输入的样本。
在表格建立好后,将你的ELB数据导入。这里你可以使用COPY命令来利用并行加载数据特性,COPY命令会根据你定义的文件规范导入多个文件。这里有一些示例:
Include all the logs for March 16, 2014: s3://yourbucket/AWSLogs/youraccount#/elasticloadbalancing/us-east-1/2014/03/16 Include all the logs for March 2014: s3://yourbucket/AWSLogs/youraccount#/elasticloadbalancing/us-east-1/2014/03
如果想加载指定两天的数据,你必须运行COPY命令两次,每天都有一个文件规范。使用下面的COPY命令可以加载对应文件的数据:
copy
elb_logs
from
's3://yourfilespec'
COMPUPDATE OFF
CREDENTIALS
'aws_access_key_id=yourkey;aws_secret_access_key=yoursecretkey'
delimiter ' '
TIMEFORMAT as 'auto'
ACCEPTINVCHARS
MAXERROR as 100000
COPY命令会以最快的速度将数据导入Amazon Redshift中,你需要进行以下两步来优化你的查询性能。两个命令如下:
VACUUM elb_logs; ANALYZE elb_logs;
在第一次加载后,VACUUM命令不是必须被运行,但是请保持这个习惯。做完这步,你的数据已经加载到Amazon Redshift数据仓库中,分析就绪。
分析你的数据
你可以使用任何PostgreSQL查询来检查你表格中的数据。为了帮助你开始,这里有一些简单的例子:
查询在两个时间内的所有访问请求:
select
RequestTime,
URL,
RequestIP_Port,
to_char(BackendProcessingTime, 'FM90D99999999') BackendTime
from
elb_logs
where
requesttime >= cast('2014-03-18 03:00:00' as DateTime) and
requesttime < cast('2014-03-18 04:00:00' as DateTime)
获得10个最慢的请求:
select top 10
RequestTime,
ELBName,
RequestIP_Port,
BackendIP_Port,
to_char(RequestProcessingTime, 'FM90D99999999') RequestTime,
to_char(BackendProcessingTime,'FM90D99999999') BackendTime,
to_char(ClientResponseTime, 'FM90D99999999') ClientResponseTime,
ELBResponseCode,
BackendResponseCode,
ReceivedBytes,
SentBytes,
Verb,
URL,
HttpVersion
from elb_logs
order by BackendTime desc
总结
通过非常快的几部,你建立了一个数据仓库,并用大量的访问请求数据进行填充,随后运行查询以分析ELB流量的状况。在数据分析之后,记得删除集群以避免更多额外的开销。如你所见,再次分析时,集群建立非常容易。