执行摘要
问题:如何最高效地分析大量数据(大数据)。
解决方案:解决方案要涵盖三个方面:
1. 找到组织和压缩数据的方式,让大量数据可以占用更少的空间,并找出一种可以读取已压缩的数据,以加快查询速度的方式;
2. 使用高效的算法,加快大数据分析的速度;
3. 选择一个可以提供均衡的资源利用率的系统环境,让CPU 处理能力、内存、输入/输出(I/O)、网络和存储能以均衡的方式协同工作,尽可能迅速地生成查询结果。
三家公司(IBM、SAP 和Oracle)都构建了旨在加快大数据分析的软件环境。然而,各厂商在组织/查询数据的方式,以及在相关的系统设计方面存在着非常明显的差异:
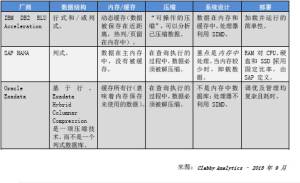
IBM 的方法使用了一项创新的技术,称为DB2 BLU Acceleration。BLU 使用列式方法,迅速减小了大数据的数据库大小,以隔离相关的数据,有效地快速读取大型数据库(这种方法使BLU 实现了比传统基于行的方法快10-50 倍的性能)。IBM 的方法还使用了数据库压缩、在内存中读取已压缩数据的能力,以及均衡的系统设计等特性;
SAP 的HANA 依赖于将大量的列式数据放在主内存中,在那里可以实时分析整个数据库。HANA 的数据压缩率高达20 倍(但需要解压缩数据后才能执行查询处理)。我们喜欢HANA,但我们对系统资源利用率是否达到良好的均衡存有疑问;
Oracle 自己的网站将Exadata Database Machine 描述为“结合大规模内存和廉价磁盘,以最低的成本提供最高的性能和PB 级的可扩展性”。对我们来说,Exadata 是一个高度调优的Oracle 真正应用集群(RAC),它被打包为配有存储的设备,使用Oracle 数据库以及数据库内高级分析。该产品没有利用列式数据;不读取已压缩数据;并且其压缩设施落后于IBM 的DB2。
更仔细地看看每家厂商的大数据分析产品,可以说明在几个方面的主要差异:缓存和压缩数据的方式;管理工作负载的方式;使用内存的方式,以及系统内的平衡/优化。
在我们从这些角度考察各厂商的产品时,我们发现IBM 的DB2 和BLU Acceleration与SAP HANA 和Oracle Exadata 相比均具有较大的优势,在均衡的系统设计和性能方面尤其明显。在此研究报告中,Clabby Analytics 更深入地讨论了这些系统有何差异。
大数据市场
由于并行处理的发展;存储成本的不断下降;数据管理软件的简化,以及成本更低、更强大、更灵活的业务分析软件不断出现,现在,对大量企业数据运行分析应用程序已经变得比以往任何时候都更实惠。多年来,企业一直在捕获有价值、有用的数据,但挖掘(分析)这些数据的成本一直过高。现在,随着系统、存储和软件成本的降低,企业发现他们可以通过分析自己早已能够捕捉到的、越来越多的结构化和非结构化数据,从而实现出色的投资回报。
一项名为“Leading Through Connections(通过连接取得领先)”的CEO 调查显示,企业现在可以实现业务分析的战略价值。企业在清理其数据,整合以及并行化其数据库,并构建集成的基础架构。作为大数据分析战略重要性的证据,在MIT Sloan 管理评论中发表的此调查的结论是,使用大数据分析的企业有两倍的可能性超越其竞争对手。这项调查还发现,在过去几年中,业务分析的使用增加了60%。
组织并使用大数据
业务分析的目标是帮助人们制定更明智的决策,从而实现更好的业务成果。为了制定更明智的决策,企业需要:
组织、集成和治理结构化以及非结构化的数据;
通过数据和计算并行性解决数据增长问题(规模);
寻找经济高效的方法来管理和存储大型复杂数据集。
为了实现数据的一致性和运营效率,需要整合以及并行化多个孤立的数据仓库,以创造一个版本的真相(一个公共的数据库视图)。此外,还需要满足可靠性、可用性和安全性(以及可扩展性和性能)方面的服务质量(QoS)要求。
在清理并联合数据后,企业需要弄清楚如何使用这些数据。可以将整个数据库都放进内存,或者动态地缓存它们(放在存储子系统中,然后按需访问)。可以对数据进行分层,最重要的数据可以放在非常接近处理器的快速磁盘上,从而得到最快速的分析。可以压缩数据,从而占用较少的空间(节省存储和内存成本)。可以将数据组织成列,使分析性能优于传统基于行的数据。有些厂商甚至可以读取压缩后的数据,比竞争对手更快速地生成结果。
在分析数据的组织方式以及系统设计如何支持大数据分析处理时,开始出现很大的差异在比较IBM、SAP 和Oracle 的方法时,我们考察的一些比较点包括:
数据结构是什么?它是行式数据还是列式数据,还是两者都有?
数据被缓存,还是全部保存在内存中?
如何处理压缩?
系统设计的特点是什么?在哪里/如何处理数据?
采取哪些措施来精简CPU、内存和I/O 交互?
部署的特点是什么?
如图1 所示,IBM、SAP 和Oracle 在数据的表达方式(行式与列式);内存管理/缓存的处理方式;压缩的处理方式;以及系统处理数据的方式(资源利用率)这几个方面也有很大的差异。
图1 – IBM、SAP 和Oracle 如何组织大数据