前言:想要写一篇关于大数据平台的发展变革,以及诸葛io自身架构演变的文章,是因为在诸葛io上线的20个月里,我们经历了客户量从0到10,000的突破。今天,诸葛io作为新一代数据分析平台,累计了过万的企业用户,每月活跃客户数2000+家,月有效行为数据处理量超过了100亿。期间,我们的研发团队面临过许多难题与挑战,同时,对于大数据平台的发展与架构也有更多的思考与沉淀。这些思考与实践,正是本文中将要和大家分享的内容。

大数据平台的三次浪潮
在讨论诸葛io这样的新一代数据分析平台之前,我们可以回顾一下1990年到2016年间,大数据平台经历的三次浪潮。
1、第一波浪潮
第一波浪潮起源于90年代,当时从计算机到软件大多还是企业级的,而数据分析就已经开始,这个时代也还是集中式软件时代,存储数据的成本也非常昂贵,所以大部分企业以KPI角度,抽取少量结构化数据,采取特定数据。代表企业如MicroStrategy、Microsoft、Oracle,代表产品诸如Sybase、Congos。这个时代能产生的数据有限,能处理数据的能力有限。

图1
2、第二波浪潮
发展到2000年左右,互联网的兴起,带动了计算机和软件从工具型走向消费级,由于互联网基础设施的发展,以下三点带来了数据的爆发式增长。
1)网络带宽的升级优化,从2g到4g,从拨号上网到光纤入户。
2)围绕互联网信息化带来大量的数据产生,如门户网站,社交平台,内容和视频平台等。
3)科技发展,从PC到移动设备到各种智能设备,都可以采集传输数据。
数据的存储成本越来越低,数据的产生速度越来越快,数据量越来越大,第一波浪潮时的技术体系无法满足需求,并且由于摩尔定律基础硬件设备和条件也在优化,处理数据的能力越来越强,此时带来了大数据平台第二波浪潮的发展:
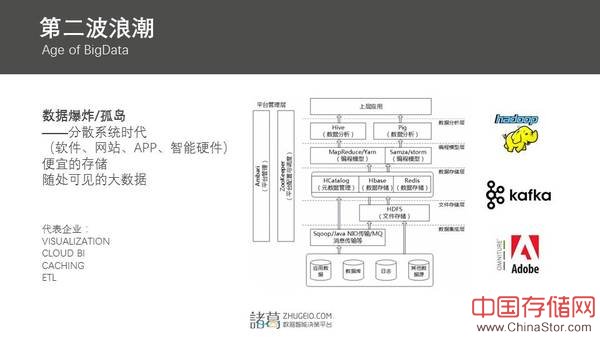
图2
面临这样的环境趋势,第二波浪潮需要解决的核心技术问题包括三方面:
1)越来越分散的数据需要集中采集处理
数据采集集中大多是“Pull”和“Push”两种方式,由于收集方式,可扩展性,收集效率,消息队列等都需要一些突破。
2)计算的可扩展性
机器资源已经不是瓶颈。如何能分布式计算,把计算的复杂度分散拆解是核心要解决的问题,比如算法上的“多项式拆分”到计算框架上的“批处理”
3)存储的可扩展性
越来越大量的数据,如果只是本地文件存储或者数据库存储,效率越来越低下,所以保障访问和提高效率,可以灵活扩展存储数据也是要解决的问题。
大数据技术在这个阶段陆续诞生了从Facebook早期开源的Scribe到Cloudera的Flume,到Linkedin的Kafka,以及后来的Flink等数据流处理框架,熟知的还有Spark/Storm/Samza等实时处理技术。这个阶段,很多人都在提大数据和Hadoop,但是我们做到的是数据流处理和实时处理以及存储方式的突破和革新,分析主体是分析中心化方式。由BI团队或者数据团队驱动,集中式的制定KPI,数据采集集中之后会按照KPI进行处理展现。如果遇到多样化或者探索性的业务分析需求,还需要on-demand(按需)去编写程序或者SQL来基于这些大数据平台获取结果。
3、第三波浪潮
发展到2010左右,互联网发展从信息化走向了服务化,创业方向也从之前的“门户时代”、“社交时代”,“垂直化门户时代”,“内容视频时代”走向了电商、出行、外卖、O2O等本地服务。如果说面向信息化的时代更多的是基于流量广告等商业模式,面向服务化时代更多的是直接面对客户价值的变现商业模式,或者说消费者服务,所以从行业发展来看,服务类对分析的需求也要旺盛很多。
我们可以用破木桶蓄水过程来类比,到处都是水源的时候,并且外部水源流入率大于自身流失率的时候,更多的思考的是抓紧圈水源而不是找短板。从2000年到2014年,流量势头猛进,到处都是用户,对于企业而言更多的思考是如何圈用户,而不是如何留住用户并去分析流失原因。
当外部没有更多水源进入并且四处水源有限的时候,我们需要的是尽可能修复木桶,并且找到木桶的短板。在2014到2015年之间,互联网流量红利也初现消退之势,国内的经济下行压力也逐渐增大,就好比水源有限一样,企业更多的需要分析自身原因了,去提高各种转化率,增加用户的忠诚度和黏性,减少用户的流失。因此分析需求开始逐步提升,各个业务部门也都需要自我分析优化成本,提高产出和利润。
过去企业更多面临的是由上而下的KPI中心化式分析,形成了分析中心化体系,基本上整个公司有统一关注的指标和数据看板,但是各业务部门的分析需要单独处理。
数据分析从行业、角色、部门和场景而言,都是差异化的。比如行业上,电商关注的是购买相关指标,内容关注的是阅读相关指标,社交关注的是参与度相关指标,工具关注的是功能使用情况。角色上,CEO关注的是整体、财务各部门的KPI;市场VP关注的是营销相关的子项目KPI;销售VP关注的是销售阶段状态和结果相关的指标;如部门上,市场关注的是投放转化率等指标;产品关注的是功能留存率等指标。如果要更充分的满足分析需求,需要从KPI中心化分析转向分析去中心化,也就面临着又一次大数据平台的技术革新,也因此推动了大数据平台第三波浪潮的变革。
第一第二波浪潮更多解决的还是技术问题,第三波浪潮最重要的是要解决分析问题,但是分析的问题主要有三点:
1)分析由于行业经验的积累和行业经验的信息不对称而诞生
2)大多数公司缺少专业分析经验的人和能构建数据分析平台的团队
3)依赖数据分析团队集中分析的方式效率低下,需求排队。
所以也就意味着第三波浪潮带来的更多不是通用的技术平台,而是更多深入的行业分析应用,所以在数据模型和数据仓库这一层的变革会更大,当然少不了的还是Google这样大鳄的弄潮,开源了BigTable带来的是以Hadoop为核心的第二波浪潮兴起,而Google的BigQuery是第三波浪潮的代表。
图3
第三波浪潮带来了一个新的概念——DI(数据智能)。不同于BI的是:DI关注的是数据对各个业务部门的决策驱动和应用,而BI关注的是基于业务收集数据处理数据的过程。
第三波浪潮下的大数据平台,会从分析看板开始,有各个行业下各个业务部门所关注的指标,并且业务人员可以灵活的配置,同时对于复杂的分析下钻和数据探索的过程而言,业务人员也无需SQL或者代码,可以直接通过交互式的查询组件进行自助式分析和配置。大数据分析的基础技术已经逐渐成熟,而挑战就是基于行业理解下构建合理的数据模型,以及多维下复杂查询的效率。
诸葛io就是在第三波浪潮下诞生的一款数据分析产品,最大的特点就是快速直接给各个业务部门的人呈现他们需要的目标,无需借助专业人士,指标的可视化,一目了然。
诸葛io的业务架构实践
1、诸葛io当前业务架构
图4自下而上是诸葛io当前的主要业务架构:
1)数据采集端
诸葛io现在提供了Android、iOS、JS等SDK和REST的Http接口来采集数据,SDK和接口都提供一些面向用户的方法或者数据规范,我们分析的数据主要来于此。
2)数据接收服务
SDK和接口采集到的数据会发给我们的网关服务,我们的API会对数据进行简单加工,添加一些环境信息的字段之后,发给我们的消息队列。
3)消息队列
消息队列会成为数据的集中处理中心,我们对消息会进行统一的加工转换和清洗,比如过滤垃圾数据,关联用户的id,加工用户的状态和标签,加工行为数据等。
4)多业务处理
数据进行统一的加工和处理完成之后,我们会有多个服务同时消耗和处理基础数据。主要包括以下部分:
a.实时统计
为了减少对数据仓库的压力以及提高数据处理的效率,对于一些基础指标,比如新增、活跃、触发各种行为的人数等我们会进行实时统计,写入到内存数据库中。
b.数据仓库
数据仓库是诸葛提供的深入用户行为、多维交叉分析以及行业分析模型的核心,所以底层的数据模型和加工的中间数据层主要是在这一步完成,完成后会写入到数据仓库底层的数据库中。
c.数据索引
为了提高数据查询和检索的效率,我们会对一些维度数据生成索引,会写入到索引数据库中。
d.数据备份
我们对原始上传数据以及中间清洗后的数据会做多重备份,达到一定程度的灾难恢复保障,会写入到文件中。
5)数据访问层
我们会由统一的数据访问层来输出数据,给应用层进行调用。这一层我们会封装一些分析模型和业务逻辑,数据访问层会分为内部接口和外部接口进行分发。
6)数据应用系统
我们的数据应用主要包括以下部分:
a.诸葛io网站
网站是zhugeio.com 提供给企业客户交互式自助分析的平台,包括了丰富的功能
b.内部服务
主要是DevOps和业务监控平台需要调用一些接口进行状态监控和跟踪,保障服务质量以及稳定性。
c.数据挖掘
诸葛io有算法组和分析组两支队伍对数据进行一些复杂的挖掘和分析,包括:
i)用户行为路径挖掘
ii)行业模型和看板
iii)流失和预测分析
iv)自动化的分析报告
d.开放API
我们提供给客户的不仅仅是汇总统计的数据,还允许用户直接访问和导出自己的原始数据和加工后的数据,因此我们把一些查询封装成了API的逻辑,允许客户进行二次开发或者调用,所以我们有一个开放的API平台。
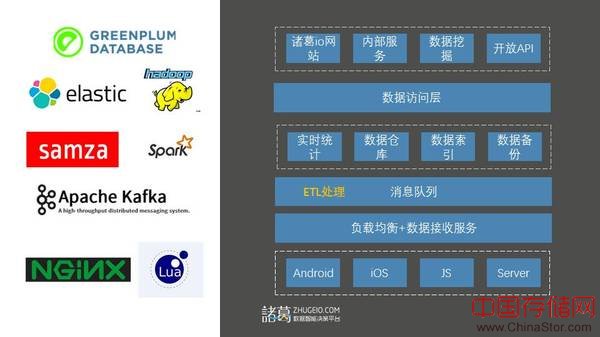
图4
诸葛io的架构经历了两次迭代,目前正在进行第三次的重构。我们重构的目的包含两方面:第一次重构主要是技术方案的瓶颈突破,第二次重构主要是业务领域问题的延伸和拓展。
架构永远是贴合业务的。诸葛io是新一代分析平台里面最早上线的。我们从2014年10月开始研发,上线于 15年3月份。当时,我们需要让产品快速上线,验证想法,所以架构搭建的比较简单。包括我在内的6个工程师,完成了整套从数据采集到数据处理到网站到前端可视化的大数据架构。由于我们的研发团队在大数据领域经验比较丰富,能解决各种技术难题。当时我们搭建的简单架构如图5:
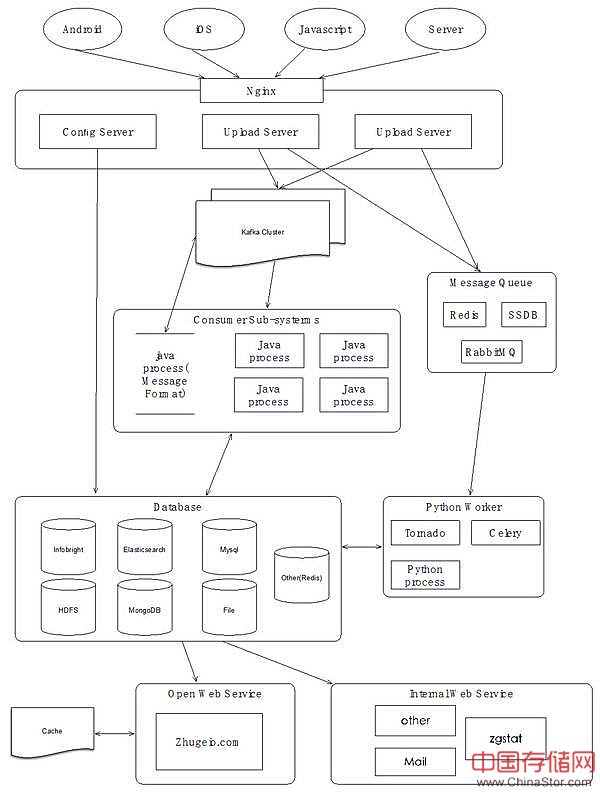
图5:诸葛io第一次上线的架构实践
初次上线的架构在刚开始的一段时间内一切正常。随着业务发展,诸葛io的客户量逐步增加,如暴走漫画、小影、墨迹天气等大体量的客户陆续接入平台,这个时候也面临着诸多考验。
2、第一次上线架构得到的经验
下图是我们第一次上线架构数据处理流的架构图,标出了三个问题点:
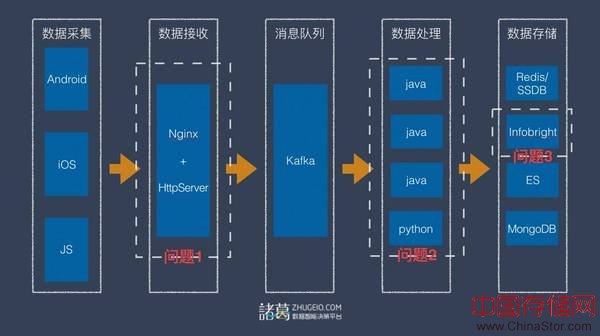
图6:诸葛io第一次上线的数据处理流:
1)数据上传延时高。
上传延时很高主要有两方面:
a.HTTPS建立连接和加密验证过于耗时
HTTPS比普通的Http的三次握手多一个SSL验证过程,我们第一次上线使用的是比较老的Nginx,并且只有单Nginx的支撑,握手压力过大。虽然我们在系统参数调优上做了很多尝试,但是本质还是需要一次架构优化,因此选择了在Nginx前加了一个LVS,把Nginx升级到最新版,并且支持了HTTP2的协议,扩展了Nginx的服务器数量。
b.数据上传模块的设计缺陷
诸葛io之前的数据上传模块逻辑是:客户端上传数据到服务端,服务端接收后会解压并且加入一些上传的IP、上传时间等字段,然继而写入到Kafka消息队列中,然后返回给客户处理结果。这个过程不需要客户端等待处理过程,需要我们团队进行优化,优化后的逻辑是客户端上传成功后即返回。我们之前的服务端是用C++编写的,我们直接参考一些秒杀的高并发架构进行了优化,在选择了Nginx+Lua后,在没有数据丢失的情况下,单节点每秒并发处理完成数提高了5倍多。
2)数据处理流使用的是多java进程方式
我们在第一次架构过程中,对于各个子业务处理的都是独立的java程序进行数据消费和处理,由于这种方式不利于我们后续的业务扩展和运维管理,有很大的隐患,我们将其改成了通过Samza平台的处理过程。选择Samza的主要原因是,处理的输入输出都是Kafka,并且Samza的实时性也有保证。
3)数据仓库不具有可伸缩性
我们的数据库选型一开始用的是Infobright的社区版,国内之前使用Infobright作为数据仓库的比较有名的公司是豆瓣,虽然Infobright不是分布式的,我们考虑到大多数App或者网站的DAU不会超过百万,并且Infobright的压缩和性能都不错,对于我们这种SaaS的早期创业公司而言,成本也会有保障。当我们的数据越来越大的时候,加了控制路由,会分发不同应用到不同的Infobright中。但是随着我们业务发展的逐步突破越来越多的百万甚至千万DAU的产品找到我们,我们还是要解决查询性能和数据扩展的问题 。
从数据存储可扩展性和计算资源的分布式调用来综合考虑,我们选择了Greenplum平台。

图7
3、数据处理上的技巧:
我们在数据处理上也做了一些技巧:
包含两部分:
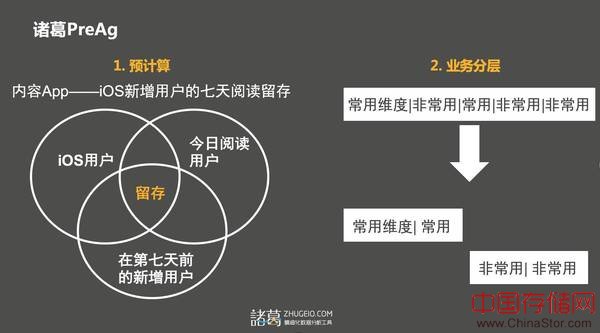
图8
1)预计算
对于互联网用户分析,大多数是分析特定行为,特定类型(新增/活跃),特定平台(Android/iOS/JS),特定渠道的用户,所以这里其实有一些集合计算法则和技巧可以利用,我们基于这个写了一个数据预处理的服务诸葛PreAg
2)模型优化——业务维度分层
很多人在设计模型是过于去找逻辑对等以及对象关系,但是其实从应用场景来看,比如同是环境的维度或者同是业务的维度,其实在查询场景上并不是同频率的,有的时候为了一些极少数出现的复杂查询我们做了过度的抽象设计,这一点我们做了很多的优化。
结合上面的问题,我们并进行了第一次架构调整。
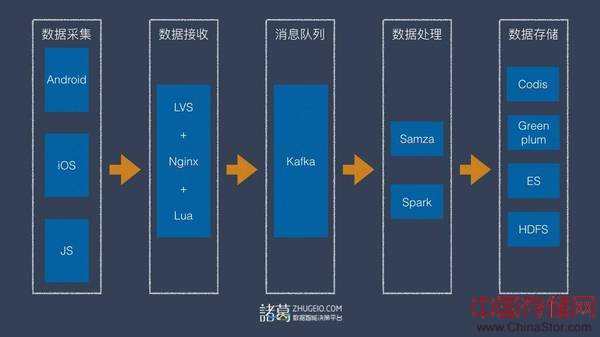
图9
架构V2比第一次架构更合理。除了上面提到的,我们把中间不易扩展的部分都替换成了一些支持分布式的技术组件和框架,比如Redis和SSDB我们都换成了Codis,比如文件我们换成了S3/HDFS
以上是我们前两次架构的经验分享,我们现在在进行第三次架构优化的过程中。这一次更多是业务领域的突破和延伸,在过去一年中,我们感受到了一个SaaS公司面临的各种挑战—不同于私有部署的资源分散。SaaS公司满足业务的同时也需要保障服务质量,任何一个小的更新和优化都需要多方面的检查。
上面提到的只是一些我觉得能结合业务有共性的优化问题,我们团队其实遇到的问题远远不止于此。底层技术上,从一开始底层硬盘的存储优化,到系统参数调优,包括上传服务器、数据仓库等底层涉及到的系统参数,如连接优化,UDP/TCP 连接优化等,再到开源平台的参数和配置测试和调优,例如Kafka的分区调整/参数配置,Greenplum的资源队列,内存资源参数,查询参数的测试优化等,这些也希望大家在自己的架构设计和实践中不要忽视,要多去结合自有的机器类型(IDC或者云机器),机器配置,业务需要进行调整。