Google Compute Engine 的虚拟机提供了一种快速、可靠的方式来运行 Apache Hadoop。如今,Google 正在努力通过Google Cloud Storage Hadoop预览版更简单的在 Google Cloud Platform 上运行Hadoop,这样你就可以更加专注于数据处理逻辑而不是集群管理和文件系统。
下图是Hadoop在Google Cloud Platform上的图解。在Google Cloud Storage上存储数据时HDFS、NameNode是可选的。
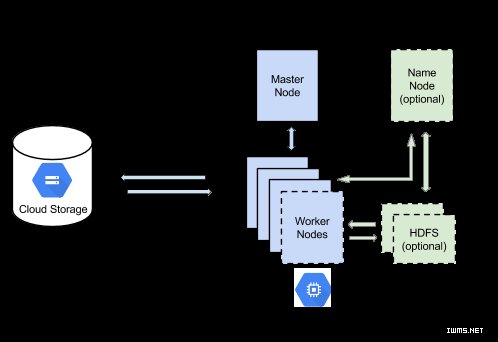
在十年前,从Google第一次介绍了Google File System (GFS)——Hadoop Distributed File System(HDFS)的基础——Google一直在努力改善Google大数据处理的存储系统。最新的成果是Colossus。
今天的发行版本提供了准确的——使用了一个简单的连接器库,Hadoop现在可以直接地在Google Cloud Storage运行——一个对象存储创建在Colossus上。这意味着你在大数据处理时可以从Google的这项技术中获益。
下面是用Google Cloud Storage运行Hadoop的优势:
兼容性:Google Cloud Storage connector for Hadoop 代码兼容Hadoop。只要将URL指向你的数据就可以。
快速启动:数据准备处理。当你的数据复制到HDFS以及NameNode,你不必等待过长时间来结束这个安全模式。同时,你也不需要花费数据复制VM时间。
更高的可用性和可扩展性: Google Cloud Storage比HDFS具有更高的可用性,因为它有独立的Compute Nodes和NameNode。如果虚拟机拒绝(或云禁止、崩溃)你的数据还在。
低成本:包括存储和计算:存储,因为没有必要维护两份数据,一个用于备份,另一个用于运行Hadoop;计算,因为你不需要仅仅为服务数据而保持VM一直运行。同时,它是以分钟计费,你可以在多个内核上更快的运行Hadoop,并且你的成本不再是四舍五入为一个小时来计算。
没有存储管理开销:鉴于HDFS需要日常维护——比如文件系统校验、重整、升级、反转和NameNode重启——Google Cloud Storage只需要为计算付费。你的数据是安全和一致的,不需要更多的努力。
互通性:通过在Google Cloud Storage保管你的数据,你可以从Google上其它已经完美融合的服务中获益。
性能:由于有了Google Cloud Storage,Google的基础设施将会比HDFS提供更高的性能——因为它没有管理和维护开销。

如果想了解Google Cloud Platform到底有哪些优势,可以访问这个简单指导 。 Google很乐意听到你关于如何更好的在Google Cloud Platform运行Hadoop和MapReduce的反馈和想法。