Hadoop虚拟化的调优经验
(1)计划初始规模:集群表现于跟数据中心基础设施和配置密切相关,建议用户在一开始对环境表现难以预测的时候,先建立小规模集群,比如5台或者6台服务器,部署Hadoop,然后运行标准Hadoop基准了解自己数据中心的特点。然后根据需要逐步添加服务器和存储等资源。
(2)选择服务器:CPU建议不要少于2 * Quad-core并且激活HT(Hyper-Threading);为每个计算内核配置至少4G内存,并且预留6%的内存为虚拟化的有效运行。 Hadoop性能对I/O很敏感,建议每台服务器配置多块本地存储而不建议配置少块大容量的硬盘。考虑任务调度的代价,对于每个计算内核不建议配置超过2 块本地存储。为高性能考虑,推荐使用10G网卡。考虑为主节点服务器(运行namenode、Jobtracker)配置双电源以提高可靠性。
(3)虚拟化配置:本地存储尽量避免配置成RAID,为每一个物理盘创建一个datastore虚拟化网络配置时为了可靠性和网络传输效率,隔离管理网络和Hadoop集群网络。如图4所示:
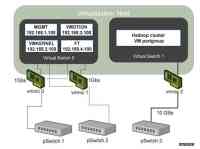
图:虚拟化网络配置
(4)系统设置:BDE将会自动配置根据实验经验取得的虚拟磁盘和操作系统参数,向用户屏蔽性能优化的具体细 节。建议对性能敏感的用户替换默认模板采用CentOS6*,因为Linux 6.* 内核的THP(TransparentHuge Page)和EPT(Extended PageTables,Intel处理器)可以一起帮助虚拟化性能。
(5)Hadoop配置: BDE将会自动产生并配置hadoop配置文件(主要在map- site.xml,core-site.xml,和 hdfs-site.xml内),包括块大小(blocksize),会话管理和日志功能。但是有一些相关于MapReduce任务的参数,包括 mapred.reduce.parallel.copies,io.sort.mb,io.sort.factor,io.sort.record.percent, 和tasktracker.http.thread,需要根据不同负载具体设置。
(6)扩展建议:如果用户观察集群中CPU的利用率经常超过80%,建议加入新的节点。另外单个存贮节点的容量不建议超过24TB,否则一旦节点失败,数据备份拷贝容易造成数据拥塞。扩展可以按照小规模集群上运行性能基准经验和资源使用情况进行。