Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,支持密集型分布式应用并以Apache2.0许可协议发布。
Hadoop:以Hadoop分布式文件系统HDFS(Hadoop Distributed Filesystem)和MapReduce(GoogleMapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构
1.Hadoop实现了MapReduce的编程范式:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上执行或重新执行。
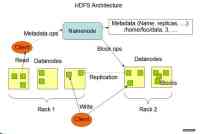
2.HDFS:用以存儲所有計算節點的數據,這為整個集群帶來了非常高的帶寬。
3.Hadoop集群结构为:Master和Slave。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。
4.MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
5.HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。 HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
Hadoop的五大优势
高可扩展性
Hadoop是一个高度可扩展的存储平台,因为他可以存储和分发横跨数百个并行操作的廉价的服务器数据集群。不同于传统的关系型数据库系统不能扩展到处理大量的数据,Hadoop是能给企业提供涉及成百上千TB的数据节点上运行的应用程序。
成本效益
Hadoop 还为企业用户提供了极具成本效益的存储解决方案。传统的关系型数据库管理系统的问题是,他并不符合海量数据的处理器,不能够符合企业的成本效益。许多公司过去不得不假设那些数据最优价值,然后根据这些有价值的数据设定分类,如果保存所有的数据,那么成本就会过高。虽然这种方法可以短期内实现工作,但是随着数据量的增大,这种方式并不能很好的解决问题。
Hadoop的架构则不同,其被设计为一个向外扩展的架构,可以经济的存储所有公司的数据供以后使用,节省的费用是非常惊人的,Hadoop提供数百TB的存储和计算能力,而不是几千块钱就能解决的问题。
灵活性更好
Hadoop能够使企业轻松访问到新的数据源,并可以分析不同类型的数据,从这些数据中产生价值,这意味着企业可以利用Hadoop的灵活性从社交媒体、电子邮件或点击流量等数据源获得宝贵的商业价值。
此外,Hadoop的用途非常广,诸如对数处理、推荐系统、数据仓库、市场活动分析以及欺诈检测。
快
Hadoop拥有独特的存储方式,用于数据处理的工具通常在与数据相同的服务器上,从而导致能够更快的处理器数据,如果你正在处理大量的非结构化数据,Hadoop能够有效的在几分钟内处理TB级的数据,而不是像以前PB级数据都要以小时为单位。
容错能力
使用Hadoop的一个关键优势就是他的容错能力。当数据被发送到一个单独的节点,该数据也被复制到集群的其它节点上,这意味着在故障情况下,存在另一个副本可供使用。非单点故障。
Hadoop集群配置实例:架构
1个Master,1个Backup(主机备用),3个Slave(由虚拟机创建)。
节点IP地址:
rango(Master) 192.168.56.1 namenode
vm1(Backup) 192.168.56.101 secondarynode
vm2(Slave1) 192.168.56.102 datanode
vm3(Slave2) 192.168.56.103 datanode
vm4(Slave3) 192.168.56.104 datanode
ps:Hadoop最好运行在一个单独的用户下,且所有集群中的用户应该保持一致,即用户名相同。
Master机器配置文件中:masters文件中指定的是要运行的secondarynamenode,slaves文件指定的是要运行的datanode和tasktracker
Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;Salve机器配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行。
在进行Hadoop集群配置中,需要在"/etc/hosts"文件中添加集群中所有机器的IP与主机名,这样Master与所有的Slave机器之间不仅可以通过IP进行通信,而且还可以通过主机名进行通信。JDK(java集成开发环境)和hadoop的安装、配置。
MapReduce:" 任务的分解与结果的汇总"。用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是 TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台 JobTracker(位于Master中)???
MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
Hadoop配置实例:具体过程
1.网络、主机配置:在所有主机上配置其主机名
/etc/hosts:将集群中所有主机的主机名和对应ip地址加入所有机器的hosts文件中,以便集群之间可以用主机名进行通信和验证。
2.配置ssh无密码登录
3.java环境安装
集群所有机器都要安装jdk,jdk版本:jdk1.7.0_45,并配置好环境变量:/etc/profile:
# set java environment
export JAVA_HOME=/usr/java/jdk1.7.0_45
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
source /etc/profile 使其生效
4.hadoop安装和配置:所有机器都要安装hadoop,hadoop版本:hadoop-1.2.1
4.1 安装:tar zxvf hadoop-1.2.1.tar.gz ; mv hadoop-1.2.1 /usr/hadoop;
将文件夹hadoop的权限分配给hadoop用户。
4.2 hadoop环境变量:#set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH :$HADOOP_HOME/bin
在"/usr/hadoop"创建"tmp"文件夹:mkdir /usr/hadoop/tmp
4.3 配置hadoop
1)配置hadoop-env.sh:
# set java environment
export JAVA_HOME=/usr/java/jdk1.7.0_45
2)配置core-site.xml文件:
3)配置hdfs-site.xml文件
4)配置mapred-site.xml文件
5)配置masters文件:加入的为secondarynamenode的ip地址
6)配置slaves文件(Master主机特有):添加datanode节点的主机名或ip地址。
ps:可以先在master安装并配置好,然后通过scp -r /usr/hadoop root@服务器ip:/usr/,将Master上配置好的hadoop所在文件夹"/usr/hadoop"复制到所有的Slave的"/usr"目录下。然后在各自机器上将hadoop文件夹权限赋予各自的hadoop用户。并且配置好环境变量等。
5 启动和验证
5.1 格式化HDFS文件系统
在Master上使用hadoop用户进行操作:
hadoop namenode -format
ps:只需一次,下次启动不再需要格式化,只需start-all.sh
5.2 启动hadoop:
在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭:
service iptables stop
使用下面命令启动:
start-all.sh
启动hadoop成功后,在Master 中的tmp 文件夹中生成了dfs 文件夹,在Slave中的tmp 文件夹中均生成了 dfs 文件夹和mapred 文件夹。
5.3 验证hadoop:
(1)验证方法一:用"jps"命令
(2)验证方式二:用"hadoopdfsadmin -report")验证
6 网页查看:访问"http://masterip:50030"
Hadoop使用端口说明
默认端口 设置位置 描述信息
8020 namenode RPC交互端口
8021 JT RPC交互端口
50030 mapred.job.tracker.http.address JobTrackeradministrative web GUI
JOBTRACKER的HTTP服务器和端口
50070 dfs.http.address NameNode administrative web GUI
NAMENODE的HTTP服务器和端口
50010 dfs.datanode.address DataNode control port (each DataNode listens on this port and registers it with the NameNode onstartup) DATANODE控制端口,主要用于DATANODE初始化时向NAMENODE提出注册和应答请求
50020 dfs.datanode.ipc.address DataNode IPC port, usedfor block transfer
DATANODE的RPC服务器地址和端口
50060 mapred.task.tracker.http.address Per TaskTracker webinterface
TASKTRACKER的HTTP服务器和端口
50075 dfs.datanode.http.address Per DataNode webinterface
DATANODE的HTTP服务器和端口
50090 dfs.secondary.http.address Per secondary NameNode web interface
辅助DATANODE的HTTP服务器和端口
总结