在Apache Hadoop的起步阶段,主要支持类似搜索引擎的功能。如今,Hadoop已经被数十个行业采用,它们依靠大数据计算来提升业务处理性能。政府、制造业、医疗保健、零售业和其他部门越来越多的从经济发展和Hadoop计算能力中受益,然而受到传统企业解决方案限制的公司将会发现竞争变得越来越残酷。
选择一个合适的Hadoop发行版和在业务中应用Hadoop一样有必要。最终,你会发现选择哪种Hadoop发行版取决于主机的规格,尽管性能和扩展性才是你应该仔细检查的两个主要特性。让我们了解一下一些具体的Hadoop性能和扩展性要求,以及对几个关键架构的要求。
性能
企业需要摆脱传统的数据库解决方案来管理数据,主要原因是为了增加原始性能并获得可扩展性。这可能会让你感到惊讶,因为并不是所有创建出的Hadoop分布系统都一样。
在我的另一篇文章中曾讲到,增加250毫秒的延迟可能会毁掉整个线上销售的旺季,我们可以了解一下为什么性能的低下(高延迟)会让人难以忍受。网站性能的迟缓会使线上的销售转化率下降7%,这对于流量很大的线上零售商来说意味着数百万美元的损失。
正如你在下图看到的那样,将MapR M7版本与另一个Hadoop发行版对比,在延迟上的差别意味着性能的不同,而不同发行版之间性能差距也是惊人的。
当你考虑Hadoop的实时应用时,比如金融安全系统的实时应用,那样对高性能增加的要求甚至更高。
要特别感谢像Hadoop这样的技术,它使金融罪犯窃取数字资产变得越来越难,金融服务公司比如Zions银行现在已经能够在银行客户感觉到任何实质性影响之前阻止财务欺诈。对于分析和实时数据响应来说,高性能和可靠性很有必要,这可以阻止破坏性欺诈活动。
扩展性
Hadoop的另一个主要优点是可扩展性。不用通过单一的企业服务器限制数据吞吐量,Hadoop可以跨计算机集群完成对大型数据集的分布式处理,从而在商品化硬件多个部分之间采用逐个击破的办法消除数据上限。
这种体系结构只是数据可扩展性提升的起点,还远没有结束。关于可扩展性,Hadoop平台内还有三个方面需要进一步考虑:
文件瓶颈
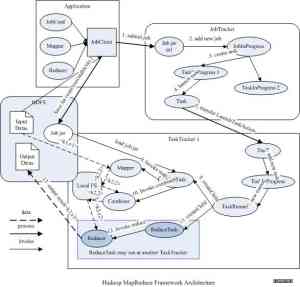
Hadoop默认的体系结构利用单一NameNode作为剩余数据节点的主节点。因为单个NameNode,所有数据被迫进入到一个瓶颈期,这就将Hadoop集群限制在只能有5000万到2亿个文件。
单个NameNode的执行情况也需要使用商业级NAS,而不是预算友好型的商品化硬件。
对于单一NameNode体系结构有一种更好的选择——使用分布式元数据结构。下面提供两种体系结构的可视化比较:
正如你所看到的那样,分布式元数据架构使用的完全是商品化硬件,不仅节省了成本,它还使性能提升了10-20倍,摆脱了文件瓶颈,使文件数上限达到了10亿,比单个NameNode的体系结构在容量上提升了5000倍,这确实是很大的成功。
节点扩展
Hadoop的一些较小用户对数据存储和处理并没有太高要求,因此能够在更少的节点上运行,而有些Hadoop实现则可以达到了数千节点的规模。
这也是Hadoop可扩展性非常出色的地方。从一个入门级大数据实现扩展到具有数千个节点的集群很容易,按照需求增加商品化硬件可以使成本最小化,这涉及到数据处理成本以及需求增加所需投入的成本。
节点容量
除了节点的数量,考虑到物理存储限制,Hadoop用户还应该检查每个处理和存储容量。你可以使用具有更高磁盘密度的节点减少总体节点数量,同时还能保证数据存储的要求。
架构基础
Hadoop的性能和可扩展性可以被进一步提升,前提是你要有多架构基础分布式系统的思想。
减少软件层
软件层太多,会导致导航成本的增加,使Hadoop系统的性能很难得到提升。
使所有应用程序在同一个平台上运行
一些Hadoop发行版可能会要求你创建多个实例,一个优化执行将使同一个环境中所有的工作负载被同时处理,这就减少了重复数据的产生,因此提高了可扩展性和性能。
利用公共云平台获取更好的弹性和可扩展性
一个好的发行版使你可以在自己的防火墙内灵活地使用Hadoop以及可靠的云环境,比如亚马逊网络服务和谷歌计算引擎。
最后,选择正确的Hadoop发行版应符合业务需求,不仅仅考虑当前的需求还应考虑未来的需求。分析每个发行版的性能和可扩展性,同时考虑架构基础,这也是在组织内成功实施和评估Hadoop的基础。