2013年11月22-23日,作为国内唯一专注于Hadoop技术与应用分享的大规模行业盛会,2013 Hadoop中国技术峰会(China Hadoop Summit 2013)于北京福朋喜来登集团酒店隆重举行。来自国内外各行业领域的近千名CIO、CTO、架构师、IT经理、咨询顾问、工程师、Hadoop技术爱好者,以及从事Hadoop研究与推广的IT厂商和技术专家将共襄盛举。

在SQL&NoSQL专场,来自巨彬软件的CTO王涛做了《文档式数据库在Hadoop集群中的应用》演讲,从大数据的回顾、文档式数据库特性、数据库在Hadoop中的定位以及用户案例四个方面详细介绍了NoSQL在大数据时代的作用。
王涛介绍到,谈到大数据我们首先想到的就是3V(Volume、Variety、Velocity),Volume代表海量数据规模,据统计已有50%以上的组织拥有和正在处理超过10TB的数据,其中超过10%的组织已经超过1PB的数据,这也是大数据面临的第一个挑战;Variety代表高时效性,有30%的组织每天需要处理超过100G的数据,如何从海量的数据中实时得到我们想要的数据这是大数据所面临的第二个挑战;Velocity是多样化,大数据里我们需要处理的数据更加多样化,比如图形、视频、通话记录而这些数据可能都需要被处理和分析,如何处理这些多样化的数据是我们在大数据里面临的第三个挑战。
想要真正的解决大数据问题,可以用Hadoop+NoSQL组合来使用。如下图,Hadoop很好的解决了海量数据与多样化数据的问题,NoSQL解决了海量与高时效性数据。王涛谈到,Hadoop与NoSQL互为补充,而非取代。

▲Hadoop与NoSQL—解决BigData的核武器
谈到普通关系型数据库在大数据环境下面临的困境,王涛介绍到,一是数据模型僵化,无法处理海量的数据,造成了性能的上线;二是强一致性,关系型数据库中日志、锁构成了性能瓶颈;而文档式数据库却可以很好的解决这些问题。王涛继续谈到,文档式数据库数据模型灵活,Schemaless带来开发的敏捷和可扩展性的提升;最终一致性也带来了性能大幅度的提升;同时,NoSQL也体现在低成本方面,可以使用PC服务器进行水平扩张。
接着,王涛介绍了文档型数据库的几大特性,首先是在线扩容,只要把新的节点增加到集群里,然后划分数据分区,系统就可以自动的把数据从其他的机器搬到新的机器上。其次是异构数据复制机制,可以保证数据的稳定性、不丢失。三是多索引的支持,和很多KV或者宽表数据库比起来,文档型数据库一般对一个集合能够在不同字段上创建多个索引。
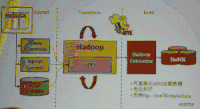
谈及Hadoop与NoSQL的结合点,王涛谈到了NoSQL数据库在Hadoop中的定位(如下图),把NoSQL放到了hadoop的下面,与HDFS处于同一层,而做为一个数据源。这样做的好处就是,我们每次访问数据的时候,从需要从上方导入HDFS再使用,而是可以直接的访问原生的数据库接口访问到数据。

▲NoSQL数据库在Hadoop中的定位
▲从Hadoop导入数据
最后,王涛分享了Hadoop与NoSQL的成功应用案例:
首先,客户挑战面临每天需要入库归档超过100G数据,需要能够并发、实时、由多个维度访问超过2年的历史数据,当前的Oracle数据库无法满足实时查询的需求。
解决方式:使用MapReduce与Hive作为ETL处理的补充进行数据清洗和转换,使用Hive将最终结果进行加载入SequoiaDB,小规模x86集群平台降低TCO,使用SequoiaDB,在常用查询字段上建立多个索引保证查询性能。
最终结果:可以在线针对2年的历史数据进行多条件检索,高数据压缩比节省数据存储空间,利于细分客户群,发现高价值用户,降低客户流失率,帮助自营产品、套餐等设计与创新,提升客户体验进行策略管控。