大数据的火爆已不容置疑,在本次Hadoop技术开发与应用实践分享会上,加座、站票已经完全解决不了问题,工作人员不得不临时设立两个会场,满足更多参会人员与讲师面对面沟通的机会。

本次CSDN云计算俱乐部邀请到了Hadoop大数据红象云腾公司创始人童小军、上海宝信高级工程师汪振平及智联招聘高级工程师李尤,对Hadoop与大数据上的实践做出了深度分享。
童小军:Hadoop原理、适用场景及核心思想

童小军,EasyHadop 社区创始人、原暴风影音平台研发经理;国内首位获得美国Cloudera公司Apache Hadoop开发工程师(CCDH)认证考试);中科院、工信部外聘Hadoop专家讲师;RedHadoop 红象云腾 创始人&首席架构师;多次在中国CIO年会、阿里云大会、北大CIO论坛发表大数据演讲,更是Data Wis 大数据Hadoop专家。在本次的大数据沙龙上,第一个发表了演讲。
Hadoop使用原理
Hadoop市场正在快速的发展,甚至在银行、电信各方面已经开始尝试。而童小军则主要从以下3个方面对Hadoop进行了剖析:
Hadoop原理、工作原理和工作机制
已证实及有待测试和探索的场景
实际用例
童小军集合了EasyHadop社区与RedHadoop(初创公司)的实践,描述了Hadoop、大数据、云计算之间的紧密联系:
1. 诞生的新数据服务:类似百度、腾讯、阿里云等大公司,通过Hadoop这样平台构建更大的数据平台,收集数据进行分析,并通过其它方式推送出去,也就是数据服务的理念。
2. 云计算带来竞争力:本质上其实是一种数据的开放。对比传统数据库,可以更好的进行个体分析,而Hadoop也正是做到了这一点。
Hadoop与旧平台的对比
大数据技术理念核心主要分为两个部分:虚拟化技术和类似Hadoop的技术。同样也是两个对立面,虚拟化更注重于将资源打造成一个大型机,而Hadoop恰恰相反,将各种资源池化。非Hadoop平台系统,均属核心的业务系统,比如代表性IOE,下面将分说两种系统的优劣:
大型机:稳定性、源质性高,IO能力极强,可以管理较多的磁盘及数据资源,CPU数量也占优势。当然这里面,限制在于机器间传输,存储和内核需要共同带宽。机器间的相互传输导致大量磁盘IO,从而造成磁盘瓶颈,同样带宽也很成问题。同时多CPU利用差的问题也暴露无遗,总体来说IO成为整个系统的瓶颈所在。
Hadoop:化整为零,文件被切开到不同层面,将计算移动到所在数据的节点上,通过节点实现并行化IO,因此需要挂很多层。而Map Reduce任务的数量跟CPU核数捆绑,因此CPU核数越多,Map配置就越快。通过移动计算取代移动数据,以获得更高的IO,这正是大数据存在的意义。
在本节中,童小军以求和等例子入手,更详细剖析了MapReduce的运行机制,同时还讲解了HBase的作用和功能。
Hadoop适用场景
童小军认为当下Hadoop的主要应用场景在归档、搜索引擎(老本家)及数据仓库上面,各个机构使用Hadoop不同的组件来实现自己的用例。而在这3个场景之外还有一个比较冷门的场景——流处理,这块源于Hadoop 2.0可结合其他框架的特性,而在将来,Hadoop肯定会发展到联机数据处理。
Hadoop核心思想
Hadoop平台是能够推动企业内部的数据开放,能够让每个人参与到报表、数据的研发过程。能够实现企业的数据共享,特别是Hadoop队列,资源池,队列,任务调度器的机制,能让整个机型切换成多个资源,而不是以前的数据库,一层层的隔离去使用。最后,童小军还从实际出发,对多个实践进行了讲解。
汪振平:基于Hadoop日志交易平台的架构及挑战
上海宝信高级工程师汪振平从金融行业入手,从背景、需求与目标、问题、系统架构及其它Hadoop相关知识5个方面对基于Hadoop的日志交易平台进行深度分享:
背景
使用场景:信用卡消费的延时、交易失败和失败的原因及类型、不规范交易机构和商户的寻找与产生原因。
数据特征:在数据量上,每天近3亿笔交易日志;在数据状态上,目前仅存储拟合后的交易,对原始交易日志不可用。
需求与目标:交易日志的秒级查询、交易失败分析、不合规交易分析、用户自助分析、与其它数据结合,找出交易失败原因及分析报告、报表。
打造的挑战:如何获取日志对生产系统影响最小、如何快速将每天3亿+条交易日志转译并存储到Hadoop集群、大量的作业如何管理及如何实现秒级查询。
系统的打造及架构
系统的打造就是一个发现问题和解决问题的过程,基于需求和背景,对问题逐个击破,汪振平分享了他的宝贵经验:
1. 将数据收集影响降到最低:总体上讲,无非就是基于业务选择合适的时间点和方式,这里的实际情况是:每天上午1:00~5:00之间,由于数据以二进制方式存储在本地文件中,且涉及多台机器,同时也为了能快速获取数据,采用了客户端与同业务数据源一一对应关系,每个客户端可以依据配置,能同时获取不同业务系统数据。
2. 快速将3亿+条交易日志转译并存储到hadoop集群
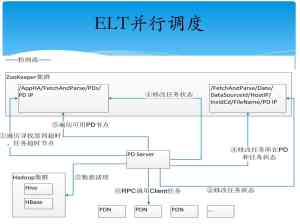
在这里汪振平弃用了MapReduce,选择了自主研发主要是因为:HDFS对文件进行切割分布,而文件又是以2进制形式进行存储。基于文件切割、报文之间分界、不完整报文等因素,而且对日志在解析过程中可用性不可控,同时也由于日志解析规范的复杂性决定。
3. 大量作业的管理
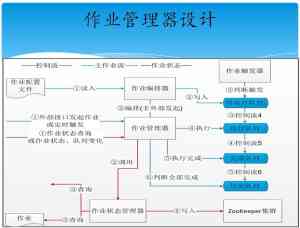
上图为其公司内部的作业管理架构,主要涉及到4个组件:作业编排器,主要负责编排作业;作业管理器,主要负责作业调度;作业状态管理器,用于审计并发现问题所在;作业触发器,触发作业,触发依赖性作业或者是其它作业。
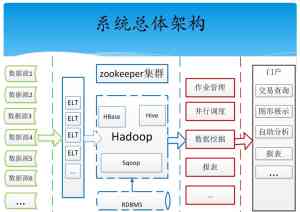
秒级查询:汪振平通过Hbase存储、二级索引、ParallelRegionQuery、支持数据区间查询、针对HBase访问API封装,提高开发效率及对集群调优实现了妙级的查询。
最后汪振平还分享了上海宝信的集群状态、Hadoop相关知识以及Hadoop个人的使用及学习相关经验,在使用经验上他认为初期要做好规模、网络、服务器硬件配置运行环境等的规划,而使用过程中则要注重集群的监控、运行日志的收集和分析及操作系统的共同调优,其中应急流程更是必不可少的一环。而在学习方面,他认为多读源码、深入了解系统运行原理是非常必要的,但无需在早期进行代码修改。
李尤:Hadoop在智联招聘的实践,及相关注意点

智联招聘高级工程师李尤表示公司集群中的数据节点已有数十台,并分享了Hadoop在智联招聘中的使用情况:
Web日志分析
不使用Ga的原因
日志数据:用户产生的日志、cdn推送过来的日志、负载均衡日志
主要分析用户产生的日志: 5月30日的日志(用gzip压缩 )遍历一遍,用时 1分21秒, piggybank中的load函数 用了正则表达式,并将字段区分开,同样的数据用时2分18秒
日志采集。
推荐系统(一种很容易理解的推荐算法:排除噪音数据,或者有一定规则的成对次数)
如何解决推荐系统的冷启动(采用了一种土办法)
对未来推荐系统的规划(机器学习)
随后他就Hadoop在智联的使用心得,分享了Hadoop在使用过程中几个必须注意的地方:
单台cpu核数即为 map和reduce槽数(内存有限时,可以考虑降低reduce槽数)
Datanode的Jvm heap不要超过2gb。Dn的磁盘数=cpu核数,且不做raid
Namenode、snn最好做raid;namenode的heap看hdfs规模了,配8gb内存大概能保证800tb的数据量(排除极端情况,有很多小文件、因为不管文件的大小是多少,一个文件、目录,block 就要占用150字节内存
如果集群比较小,可以考虑上传之前对数据源全部做压缩处理。目前智联用的是gz(这是不可分割的格式,但是节省了大量磁盘空间,是很合算的)
Shuffle配置的snappy,可以节省网络带宽
随后李尤更结合代码进行了深度的技术分享,期间还分享了Pig的主要用户,分别为:
Yahoo!:90%以上的MapReduce作业是Pig生成的
Twitter:80%以上的MapReduce作业是Pig生成的
Linkedin:大部分的MapReduce作业是Pig生成的
其他主要用户:Salesforce, Nokia, AOL, comScore
最后李尤还对Pig的主要开发者进行了讲解,其中涉及Hortonworks、Twitter、Yahoo!及Cloudera。