Facebook作为全球知名的社交网站,拥有超过3亿的活跃用户,其中约有3千万用户至少每天更新一次自己的状态;用户每月总共上传10亿余张照片、1千万个视频;以及每周共享10亿条内容,包括日志、链接、新闻、微博等。因此Facebook需要存储和处理的数据量是非常巨大的,每天新增加4TB压缩后的数据,扫描135TB大小的数据,在集群上执行Hive任务超过7500次,每小时需要进行8万次计算,所以高性能的云平台对Facebook来说是非常重要的,而Facebook主要将Hadoop平台用于日志处理、推荐系统和数据仓库等方面。
Facebook将数据存储在利用Hadoop/Hive搭建的数据仓库上,这个数据仓库拥有4800个内核,具有5.5PB的存储量,每个节点可存储12TB大小的数据,同时,它还具有两层网络拓扑,如下图所示。Facebook中的MapReduce集群是动态变化的,它基于负载情况和集群节点之间的配置信息可动态移动。
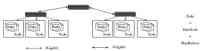
▲集群的网络拓扑
下图为Facebook的数据仓库架构,在这个架构中,网络服务器和内部服务生成日志数据,这里Facebook使用开源日志收集系统,它可以将数以百计的日志数据集存储在NFS服务器上,但大部分日志数据会复制到同一个中心的HDFS实例中,而HDFS存储的数据都会放到利用Hive构建的数据仓库中。Hive提供了类SQL的语言来与MapReduce结合,创建并发布多种摘要和报告,以及在它们的基础上进行历史分析。Hive上基于浏览器的接口允许用户执行Hive查询。Oracle和MySQL数据库用来发布这些摘要,这些数据容量相对较小,但查询频率较高并需要实时响应。
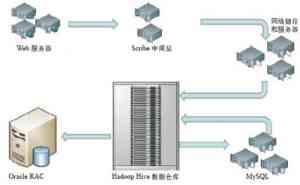
▲Facebook数据仓库架构
一些旧的数据需要及时归档,并存储在较便宜的存储器上,如下图所示。下面介绍Facebook在AvatarNode和调度策略方面所做的一些工作。AvatarNode主要用于HDFS的恢复和启动,若HDFS崩溃,原有技术恢复首先需要花10~15分钟来读取12GB的文件镜像并写回,还要用20~30分钟处理来自2000个DataNode的数据块报告,最后用40~60分钟来恢复崩溃的NameNode和部署软件。表3-1说明了BackupNode和AvatarNode的区别,AvatarNode作为普通的NameNode启动,处理所有来自DataNode的消息。AvatarDataNode与DataNode相似,支持多线程和针对多个主节点的多队列,但无法区分原始和备份。人工恢复使用AvatarShell命令行工具,AvatarShell执行恢复操作并更新ZooKeeper的zNode,恢复过程对用户来说是透明的。分布式Avatar文件系统实现在现有文件系统的上层。
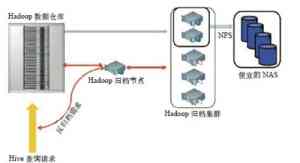
▲数据归档
表:BackupNode和AvatarNode的区别

基于位置的调度策略在实际应用中存在着一些问题:如需要高内存的任务可能会被分配给拥有低内存的TaskTracker;CPU资源有时未被充分利用;为不同硬件的TaskTracker进行配置也比较困难等。Facebook采用基于资源的调度策略,即公平享有调度方法,实时监测系统并收集CPU和内存的使用情况,调度器会分析实时的内存消耗情况,然后在任务之间公平分配任务的内存使用量。它通过读取/proc/目录解析进程树,并收集进程树上所有的CPU和内存的使用信息,然后通过TaskCounters在心跳(heartbeat)时发送信息。
Facebook的数据仓库使用Hive,其构架如下图所示,有关Hive查询语言的相关知识可查阅第11章的内容。这里HDFS支持三种文件格式:文本文件(TextFile),方便其他应用程序读写;顺序文件(SequenceFile),只有Hadoop能够读取并支持分块压缩;RCFile,使用顺序文件基于块的存储方式,每个块按列存储,这样有较好的压缩率和查询性能。Facebook未来会在Hive上进行改进,以支持索引、视图、子查询等新功能。
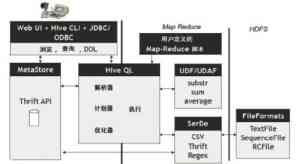
▲Hive的体系结构
现在Facebook使用Hadoop遇到的挑战有:
·服务质量和隔离性方面,较大的任务会影响集群性能;
·安全性方面,如果软件漏洞导致NameNode事务日志崩溃该如何处理;
·数据归档方面,如何选择归档数据,以及数据如何归档;
·性能提升方面,如何有效地解决瓶颈等。
作者简介:陆嘉恒,《Hadoop实战》作者,中国人民大学副教授,新加坡国立大学博士,美国加利福尼亚大学尔湾分校(University of California, Irvine) 博士后。