在第二篇中我们介绍了如何通过shell与HBase进行交互。第三篇中,我们将从整体了解一下HBase的架构。
导航:使用HBase处理海量数据系列文章共5章:1、HBase的概要介绍;2、初步了解HBase交互;3、HBASE架构了解;4、HBase中Java API使用;5、数据建模。
HBase是一个分布式数据库,原本是设计运行在上千台甚至更多的服务器集群中。因此,HBase的安装自然比在单台服务器上安装一套独立的关系型数据库更加复杂。同时,所有分布式计算中都存在的典型问题HBase也不能避免,比如远程处理的合作与管理、锁、数据分布、网络延迟以及服务器间的交互。好在HBase利用了很多成熟技术,比如Apache Hadoop和Apache ZooKeeper解决了很多类似的问题。下面的图中展示了HBase的主要架构组件。
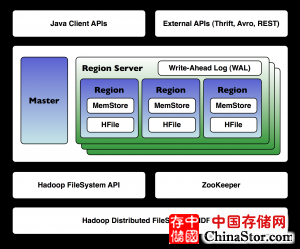
上图中可以看到,存在单个HBase主节点以及多个域服务器。(HBase可以运行在多主节点集群中,但同时只会有单个活动主节点)。HBase的表分割并存储在多个域中,每个域保存表中一定范围数据,由主节点将多个域分配至一个域服务器。
HBase是一个面向列的存储,即数据按照列存储而不是行。这样使得数据访问方式比面向行的传统数据存储系统更加高效。例如HBase中如果列簇中不包含数据,则根本不会存储任何信息。而对于一个关系型数据库来说,则会存储null值。另外,若在HBase中查询数据,只需要指定你需要的列簇,因为在一行数据中可能存在上百万行数据,你需要确定你只查询自己需要的数据。
HBase使用ZooKeeper(分布式协作服务)来管理域分配至域服务器,以及在域服务器崩溃时,能够通过将崩溃的域服务器中的域加载至其他有效的域服务器上来恢复功能。
域包括内存数据(MemStore)以及持久化数据(HFile),域服务器中的所有域共用一个先写日志(write-ahead log [WAL]),该日志用于在还未持久化存储前保存新数据,并且当域服务器崩溃后能够恢复数据。每个域都保存了一定范围内的行主键,当域包含的数据量超过定义的范围时,HBase会将域分割至两个子域,这样就扩展了HBase。
当表增大时,集群中会构建和分割出越来越多的域。当用户查询一个指定行主键或者指定范围内的主键,HBase给出这些主键所在的域,用户可以直接与这些域存在的域服务器通信。这样的设计最小化搜索指定行时可能出现的问题的数量,并且优化了数据回传时HBase的磁盘传输。关系型数据库则可能在从磁盘回传数据之前要进行大规模的磁盘扫描,甚至在有索引建立的情况下也一样。
HDFS组件使用了Hadoop分布式文件系统,分布式、高容错性、可扩展文件系统用于防止数据丢失,能够将数据切分为块且分散在整个集群中,这是HBase实际存储数据的地方。严格来说只要实现了Hadoop文件系统的API的任何形式数据都可以被纯粹,一般来说HBase会发布在运行了HDFS的Hadoop集群中。实际上,当你第一次在单机上下载和安装HBase时,如果你没用修改配置,使用的就是本地文件系统。
用户通过有效的API与HBase交互时,包括本地Java API、基于REST的接口和一些RPC接口(Apache Thrift, Apache Avro)。也可以通过Groovy, Jython, 和Scala来访问接口(Domain Specific Language [DSL])
第三篇总结
本文中,我们从一个较全面的高度了解了HBase的架构。下面,我们会使用HBase的Java API编码,并展示一些HBase的基础功能。
原文链接: dzone 翻译: ImportNew.com - 陈 晨 译文链接: http://www.importnew.com/8819.html