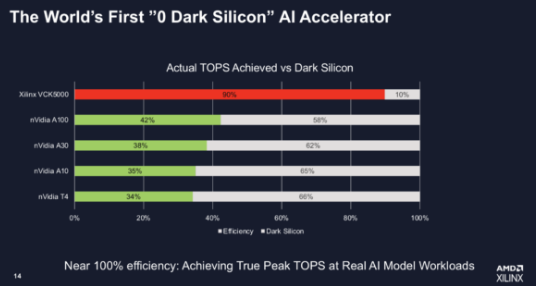
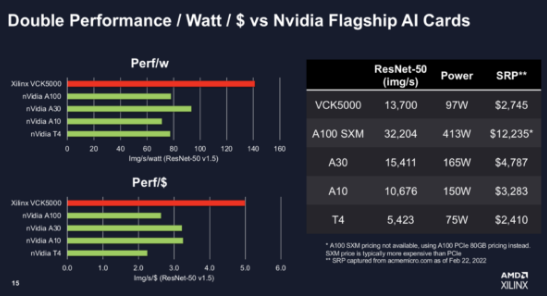
AMD/Xilinx 发布了其 VCK5000 AI 推理卡的改进版本以及一系列直接针对 Nvidia 的 GPU 产品线的竞争性基准测试。AMD 表示,新的 VCK5000 的性能是早期版本的 3 倍,并且 TCO 是 Nvidia T4 的 2 倍。AMD 还展示了针对几款 Nvidia GPU 的良好基准,声称其 VCK5000 在“真正的 AI 模型工作负载”上实现了 90% 的真实峰值 TOPS,而 Nvidia 的 A100、A30、A10 和 T4 为 34% 到 42%。
采取如此强硬的立场,强调对 Nvidia 产品的 TCO 有点让人想起 AMD 在 2017 年对英特尔的战略,当时 AMD在数据中心长期缺席后推出了 Epyc CPU 系列。当然,AMD上周刚刚完成了对 Xilinx的收购,早在 2020 年就宣布了这笔交易。VCK5000 现在的售价为 2745 美元,AMD 称这是一个非常有竞争力的价格,尤其是考虑到“当前的供应链问题”。
VCK5000 是第一款采用我们 7nm Versal ACAP 芯片的 PCIe 卡。它针对 AI 推理进行了优化,这是我们第一次将 AI 引擎内核中的一些东西放入 FPGA,”AMD 新的自适应和嵌入式计算事业部的 AI 和软件解决方案产品营销总监 Nick Ni 说。“这张卡实际上并不新,但改变的是我们在 AI 推理上的性能提高了近 3 倍。我们还声称我们是世界上第一个用于人工智能推理的零暗硅——我们是唯一实现接近 100% 数据表峰值的公司,这是其他人无法接近的。”
VCK5000 AI 推理卡包括 FPGA 和 Arm CPU 元件(见下图),于去年 5 月推出。它是 AMD Versal 自适应计算加速平台 (ACAP) 的一部分。AMD 表示,整体设计解决了它所谓的“暗硅”问题——基本上是空闲的处理元件等待来自内存的数据。

HPC 社区可能更熟悉 Xilinx-Alveo U55C,该公司围绕 SC21推出并宣传为其最强大的基于 FGPA 的加速器卡。当被要求区分这两张卡时,AMD 提供了以下内容:
- “Alveo U55C 属于 AMD-Xilinx 生产加速卡产品组合,专门针对 HPC 和大数据工作负载。它基于 Virtex UltraScale+ FPGA,与 VCK5000 相比具有不同的外形尺寸。借助基于 Xilinx RoCE v2 的集群解决方案,我们使具有大规模计算工作负载的广泛客户能够使用他们现有的数据中心基础设施和网络实施基于 FPGA 的强大 HPC 集群。
- “VCK5000 是一款基于公司 7nm Versal 产品组合的开发卡,针对需要高吞吐量 AI 推理和信号处理计算性能的设计进行了优化。VCK5000 是第一款实现接近零暗硅的 AI 芯片,使用标准基准模型,其性能功耗比比 Nvidia 的 A100 和 T4 GPU 等竞争设备高出 2 倍。”
广泛使用 FPGA 的一个长期绊脚石是其冗长而复杂的开发过程,需要在RTL级别进行编程。Alveo U55C 和 VCK5000 卡都试图通过利用 AMD/Xilinx Vitis 统一软件平台来应对这一挑战。