Oracle数据泵概念简介
数据泵是Oracle数据库本身提供的“基于服务器的工具”,用于在加载和卸载数据时获得高性能。因为他是基于服务器的,所以所有操作一定要在服务器端进行。
本文不想介绍太多的理论知识和参数,主要介绍数据泵“导入/导出”的基本步骤,其目的就是让读者轻松的掌握数据泵的基本使用方法(可以满足日常工作需求)。
该工具还有很多参数,读者可深入研究,欢迎交流。
导出详细步骤
一、导出数据
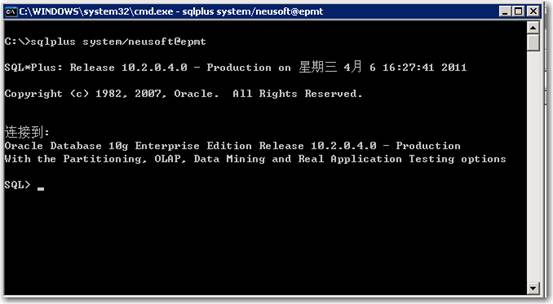
1、在数据库服务端,用system用户通过sqlplus命令登录到oracle,如下:

进入sqlplus,如下图所示:
2、在oracle中创建目录,如下:
CREATE DIRECTORY DUMP_EXP AS 'e:data';
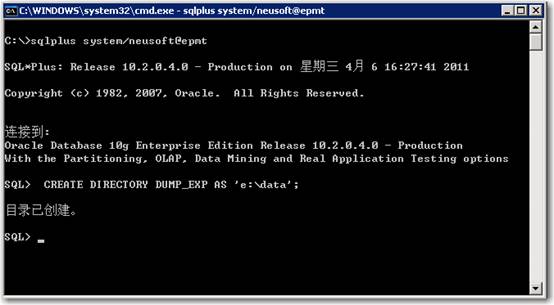
注意:e:data 这个目录必须是磁盘上实际存在的,可以是其他目录名称和路径。
3、导出数据
a、退出sqlplus:quit
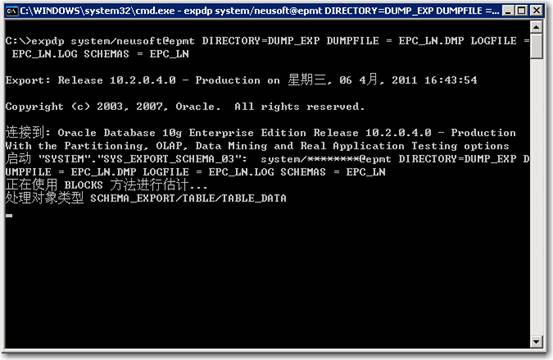
b、在dos窗口中,执行以下语句:
expdp system/neusoft@epmt DIRECTORY=DUMP_EXP DUMPFILE = EPC_LN.DMP LOGFILE = EPC_LN.LOG SCHEMAS = EPC_LN
DIRECTORY=DUMP_EXP : DUMP_EXP 我们第二个步骤所创建的目录名(实际指向E:DATA)
SCHEMAS = EPC_LN,如果是多个SCHEMA使用“,”分割。
回车执行如下图所示:

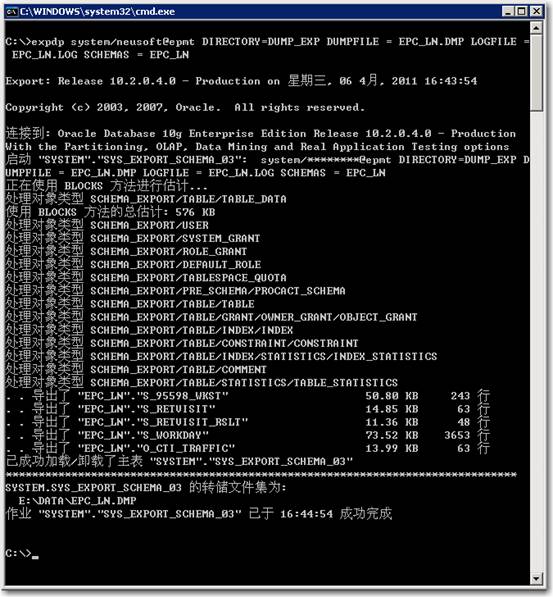
导出成功如下图所示:
导入详细步骤
1、在dos窗口输入导入命令,如下图所示
impdp system/neusoft@epmt DIRECTORY=DUMP_EXP DUMPFILE = EPC_LN.DMP LOGFILE = EPC_LN_IMP.LOG
回车执行
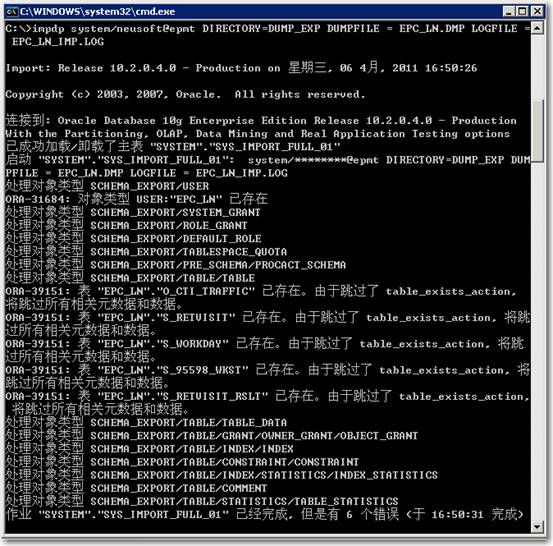
注:测试源和目标完全一致,所以跳过了已经存在的内容,日志显示有6个错误。数据泵默认都是full方式导入,可同时实现全量和增量的导入。
总结
1、 数据泵的所有操作都要在服务器端进行。
2、 数据泵方式适合于系统的数据库初始化部署和大数据量表的导入导出(导出/入表的参数是TABLES)
3、 由于数据泵在导出的时候,涵盖了创建SCHEMA的所有信息,所以目标数据库可以不存在源导出的SCHEMA。
4、 获得数据泵参数的帮助,dos窗口输入:expdp -help