许多存储厂商利用基于用户定义的政策的自动化数据迁移技术来实现存储分级。以下厂商都通过某种方式实现了迁移,但是它们所用的方法各不相同,因此迁移方案的性能和成本也不太一样。
EMC FAST
自从推出FAST或Fully AutomatedStorage Tiering(全自动存储分级)技术以来,EMC得到了普遍关注。EMC的FAST是一种基于目标的解决方案,可以根据用户政策在三级存储(即闪存、光纤通道和SATA)之间进行存储对象迁移。
FAST技术一开始只提供了各存储级之间的LUN级迁移,但是升级后的FAST技术将很快支持LUN级以下级别的迁移(1GB数据块级的迁移)。EMC计划在2010年中期发布升级版FAST技术,升级后的新版FAST技术还将包括FAST高速缓存,这样就可以通过高性能闪存驱动器减少响应时间。
Compellent Data Progression
Compellent的DataProgression解决方案是一款在分级存储环境下的基于对象的数据迁移解决方案。除了提供自动化数据迁移功能之外,Compellent还支持基于驱动器类型、转速和RAID水平的9级存储。Compellent还采用了所谓的FastTrack技术,这种技术可以将访问最频繁的数据迁移到每个驱动器中速度较快的轨道上。这项技术不但可以提供跨存储级的数据迁移,而且可以实现存储级内的优化,减少最活跃数据的搜寻时间。
在Compellent的体系结构中,被迁移的数据块的粒度一般是512kb,但是也可根据特定应用软件的需求调整到最大4MB。
3PAR Dynamic Optimization
3PAR的分级存储架构Autonomic Storage Tiering中采用的数据迁移技术也是基于目标的数据迁移解决方案,它将这种解决方案称为DynamicOptimization。3PAR的数据迁移解决方案可提供跨固态硬盘、高性能光纤通道和企业级SATA驱动器的LUN级及以下级别的数据迁移。
这种解决方案包括跨SATA驱动器的数据带,以实现容量层级的最佳性能;以及将数据对称保存在选择磁盘片的内外轨道上,这同样是为了保证最佳性能。在存储级内部,3PAR允许用户修改RAID等级,以提高数据保护等级或性能。
FalconStor Data Migration
FalconStor在其网络存储服务器(NSS)中提供了一款基于网络的数据迁移解决方案。NSS是一个基于SAN的虚拟化平台,它可以被插入SAN(光纤通道和iSCSI)中。FalconStor采用了基于LUN的数据迁移技术(下方同步进行模块级镜像操作)。在数据迁移的同时,LUN也仍然可用,这样就不会影响LUN的利用率。而且,这种同步镜像操作支持任意格式的LUN。
FalconStor的NSS还可兼容最新的HyperFS文件系统,这样就可以支持大容量存储(最高可达144PB)和数十亿文件的访问。
其它的数据迁移解决方案
虽然本文只列出了四家厂商,但是其实各厂商的存储产品中都使用了数据迁移技术。其他厂商包括IBM、惠普、日立、DotHill、Pillar、Sun、富士通和其他厂商。
数据迁移综述
归档数据的迅猛增长显然推动了存储分级以及在各存储层级间动态迁移数据以实现最佳成本和性能效益的解决方案的需求的增长。从厂商的角度分析,数据迁移技术和其他重要的存储服务显然会引发许多创新,这关系到未来的成长。
自动化存储分级和数据迁移逐渐成为存储厂商们的标准配置项目,在将它们与其他的高级存储功能无缝整合的同时,厂商们仍在研究新的优化方案。
存储分级和自动化数据迁移
在大多数技术领域内,变化是唯一不变的真理。存储生态系统就是一个很好的例子,变化不但随时在进行,而且是在各个层面上进行,从独立存储设备到基本服务以及用来处理日益增长的数据所用的前端协议,无时无处不再发生变化。
以下我将介绍一些这类服务并按照这种方式略微谈谈目前正在发生的相关演变和变革。
从宏观角度来看,自动化数据迁移是最理想的数据方案。这种优化结合了数据的当前特征和所要求的存储媒体的特征。例如,将访问频率高的数据储存在高性能固态硬盘上,将访问频率低的数据或归档数据储存在相对廉价的存储设备如SATA硬盘上。
但是这些因素都可能会随着时间的推移而发生变化。新数据的使用频率可能会偏高一些,但是随着时间的推移,它们的使用频率将逐渐下降。另外,存储媒体一直在向大容量和多样化发展,这就给存储分级以及根据数据访问频率来确定存储媒体的方案提出了新的问题和机遇。
数据迁移对推动存储系统发展也很有用。数据迁移可以将旧存储系统上的数据迁移到新的存储系统,甚至在不影响用户使用存储系统的同时将数据迁移到网络上。
在下半部分,我们将会对存储分级和数据迁移技术展开讨论,并介绍一下现代存储系统及其它们的基本特征。
存储特征存储子系统可通过许多方式来改善性能,那些方式通常与高速缓存和数据精简有关,但它们最终的性能与存储媒体有很大关系。 我们将在本文中重点讨论几个具有不同特征的驱动器的例子,不同的特征对应着不同的存储级背后的不同目的。
表1通过简单地方式解释了这些差异,表1重点列出了现有各类存储媒体中的主流媒体技术(固态硬盘、光纤通道、SAS和SATA)。 例如,如果重点是廉价的容量存储设备,那么就适合使用SATA。 另一方面,如果速度是企业关注的重点,而且成本不是问题的话,那么固态硬盘则是最佳解决方案。
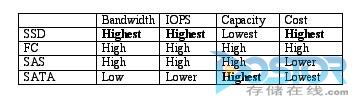
表1:常用驱动器类型的特征
这里想要表达的意思是存储媒体具有不同的特征,可以根据需要储存的数据来决定选用哪种存储媒体。 我们将用存储分级的概念来进一步探讨这个问题。
注:除了传统的磁盘接口之外,还有很多不具备本地磁盘接口的接口。 这方面的例子包括Infiniband、FCoE和iSCSI。 随着这些协议和接口的推广应用,解决方案市场也随之发生改变(注意Infiniband和10GbE为存储系统创建了更多的决策点)。
存储分级
存储分级的概念并不是个新概念,这种概念早就存在了,以前使用的名字是分层存储管理(Hierarchical Storage Management)(HSM)。 HSM被定义为一种存储技术,它可以在高价存储元件(比如存储设备中的光纤通道驱动器)和廉价存储元件(比如光盘)之间移动数据。
IBM率先将这个概念应用到它的主机计算机中,随后又将HSM技术推广到它的AIX操作系统之中。
虽然这个概念并非新概念,但是各种存储技术的发展已经让这个概念变得比以前更加重要。 回头看看表1,现在的驱动器技术和存储协议以及总线将存储划分成了多个领域,这样就形成了多种具有不同成本和速度的存储解决方案。
分别根据性能和成本来决定使用的驱动器类型,结果就得到一个分级存储架构(许多厂商都采用了这种方法,如图1所示)。

图1:分级存储架构
在最理想的情况下,我们会把所有的数据都储存在速度最快的存储媒体上(斯坦福大学提出的RAMClouds架构就是这方面的最佳例子)。 但是由于成本也是个不容忽视的因素,必须将它考虑进来。 因此,一个容量为1MB的文件储存在固态硬盘中的成本要大大高于它储存在消费者SATA硬盘中的成本。 其次我们还要考虑数据被访问的频率。 如果我们需要频繁使用并要求快速存取某个文件,那么最好还是将那个文件储存在固态硬盘上。 如果某个文件只是我们很少会用到的旧数据,那么将它储存在成本相对较低的SATA硬盘上则是最好的做法。
我们的目的是将频繁使用的数据储存在固态硬盘上,将很少使用的数据储存在廉价的存储设备上,从而优化数据的总成本。 为了实现那个目标,我们首先必须搞清数据的使用情况。
自动化数据迁移
与许多复杂的技术一样,实现自动化数据迁移也有很多不同的方式。 最常用的一种方案是存储虚拟化,这种方案将用户对存储设备和磁盘上的实际存储映射抽象化了。
在一个存储系统内部自动迁移数据的能力与这种映射有很大关系,有了它,数据才能被重建。 数据重建方案包括在元数据中,元数据详细规定数据如何在各种存储子系统中分布。
除了各种实现形式(我们将在后面详细探讨这个问题)之外,数据迁移时的数据粒度问题也有很多需要权衡考虑的地方(见图2)。 每一种数据粒度方案都有各自的利弊。 例如,有些厂商采用LUN级的迁移,从概念上来说这很简单,但是那同时也意味着一个LUN中的所有内容都将按照同样的方式来对待和处理。
也有一些厂商采用了低于LUN级的数据迁移,可以以不同大小的数据块的形式进行。 低于LUN级的数据迁移有一定的优势,比如可以将使用频率高的数据迁移到速度相对较快的存储级,而将LUN中的其他数据迁移到相对廉价的存储级。
低于LUN级的数据迁移也有一定的成本,因为元数据必须控制数量众多的单个数据块(数据块越小,效率就越低)。 另外,如果被迁移的数据块大于一个分区,那么可以通过预读的形式实现性能提升(例如,假如数据块中的各个分区都是逻辑相关的)。
数据迁移解决方案的一个重要特征是效率。 解决方案应该将任何对存储性能的影响都降低到最低水平。 其他需要权衡考虑的因素还包括数据被分类的方法、数据迁移解决方案的执行频率、数据的初始布局等等。
例如,有些数据迁移解决方案是在后台 执行的(夜间进行),而有些数据迁移解决方案是实时执行的。 虽然可能会导致滞后现象,但是实时数据迁移解决方案可以根据用户使用数据的情况动态灵活地作出反应。
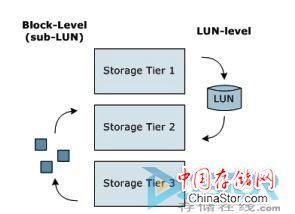
图 2:数据迁移的程度
执行类型
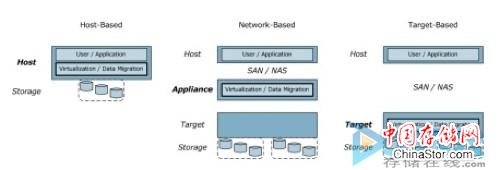
数据迁移可以通过多种方式执行,但主要被分为三种基本类型:主机、网络 和目标。 让我们先简单介绍一下这三种类型,然后再谈谈每种类型的具体执行情况和例子。 图3以图形的方式形象地展示了这三种类型。
基于 主机的执行方式将分级和迁移都集成到了主机服务器中。 虽然从单用户存储的角度来说这样做会有一定限制,但是虚拟化技术可以解决这个问题,而且还使这种执行方式能够支持多用户(多虚拟机)结构。
例 如,操作系统可以将这种功能整合到它们的逻辑卷管理程序(比如Linux的LVM)之中,管理程序可以并入存储栈中。 VMware就在Storage vMotion中采用了这种解决方案,Storage vMotion可以让活跃虚拟机磁盘在不同的存储媒体间进行迁移。 它先是利用变化分区跟踪在后台高效迁移虚拟机磁盘,最后再暂时中止虚拟机,将剩余分区移动到目的存储媒体。
基于网络的执行方式在网络中的 存储用户和物理存储之间加入了一个中介物。 这样不但分担了主机的功能,而且还可以支持不同厂商的存储后台。 基于网络的执行方式的例子包括IBM的SAN Volume Controller(SVC)、惠普的SAN Virtualization Storage Platform(SVSP)和FalconStor的Network Storage Server(NSS)。
最后,基于目标的执行方式是将数据迁移的执行放在存储阵列中进行。 与基于网络的执行方式一样,虚拟化数据可以减轻主机的负载,在目标位置建立一个抽象物。 这个抽象物建好之后,就可以实现其他的高级功能了,比如数据精简等。 现实中有很多基于目标的执行方式,比如EMC的FAST、Compellent的Data Progression、3PAR的Dynamic Optimization和其他厂商的其他方案等。