雅虎存储用户所提交的照片,视频,电子邮件和博客文章的数据量达半个EB,对象存储超过2500亿,并且对象存储每年以20%-25%的速度增长,增长原因主要有移动,图像,视频,用户量的增长这几方面。对此,雅虎选择了软件定义存储,在保证耐用性和延迟的基础上发挥存储成本效益。
雅虎的对象存储需求
什么是对象存储?图像、照片、视频、文档、表格、演示文档、以及邮件附件都是典型的对象。这种数据的典型特点就是“一次写入多次读取”。通常,雅虎用一些存储设备来做对象存储。然而,雅虎是许多人数字信息生活的引导者,它对于对象存储的需求与日俱增。此外,由于应用程序对于数据访问方式,数据可靠性,数据访问延迟以及数据存储成本的要求不尽相同。雅虎需要在考虑成本效益的同时,还要考虑满足不同应用程序的需求,雅虎在对象存储需求需要多方权衡考虑。需要软件定义存储的灵活性来做权衡。
为什么是软件定义存储?
软件定义存储的三大优势:
- 成本/性能权衡:允许应用程序在不同的硬件上进行成本和性能的权衡,使用相同的软件堆栈进行耐用性配置。
- 灵活的接口:能够选择行业标准的API接口,应用程序内嵌客户端库,必要时甚至还可以使用私有的API。行业标准的API允许应用程序无缝从公有云迁移到雅虎私有云。
- 跨存储类型:通过软件进行跨对象存储,块存储和文件存储三种存储类型,从而降低研发和运营成本。
Cloud Object Store (COS)是雅虎基于商用硬件的软件定义存储解决方案。在与Flicker的合作下雅虎已经对该方案进行了多PB的初始部署。并且计划在2015年把COS作为多租户的托管服务,继续通过支持Flicker、雅虎邮件和Tumblr来把COS的部数量提升十倍。未来COS将存储数百PB的数据!
COS用的是Ceph
COS的部署中应用到了Ceph存储技术。我们评估了开源的解决方案Swift和Ceph,以及一些商业化的解决方案后,最终选择了Ceph,因为它可以通过一个固有的架构把对象存储、块存储和文件存储整合到了一个存储层。同时因为它是开源的,所以它提供的灵活性很好地满足了雅虎的需求。
部署架构
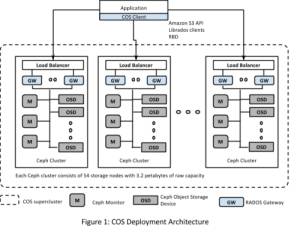
COS部署由模块化的Ceph集群组成,每个Ceph集群被视为一个POD。多个这样的Ceph集群同时部署就形成了一个如下图所示的COS“超团(supercluster)”。对象在超团里所有集群中均匀分布,我们使用专有的散列机制来分配对象。散列算法是通过嵌入应用程序中的客户端库来实现的。。
经过多次软件的调整和试运行之后,现在每个Ceph集群的部署大约能达到3PB的原始数据,并且无论在进行通常操作还是在做故障恢复的时候都能提供可预测的延迟。由于每个集群有数十个商业服务器和上百块磁盘,所以很有可能会出现故障。故障恢复时由于需要把对象再平衡,所以磁盘和网络活动比较频繁,最终增加了延迟时间。通过限制每个集群的规模,方便我们控制数据恢复时候要消耗资源,从而确保了SLA。
雅虎用户自然希望他们的图片,视频和邮件附件能永久存储下来,并且能在全世界任意地点快速访问。这首先就需要数据高的“耐久性”保证,耐久性在存储系统通常是通过冗余或编码来实现的。冗余可以通过数据复制额外拷贝来实现。另一方面,可以在编码中通过简单的奇偶校验,或更复杂的机制比如擦除编码来实现。擦除编码这种方法把对象分解为碎片,并将它们存储在多个磁盘上,通过一些冗余的碎片来容忍错误。
每个集群的可用容量取决于所使用的“耐久性”技术。我们当前采用的“擦除编码”技术把每个对象分解为八个数据和三个编码片段。这种机制被称为8/3擦除编码,可以同时承载最多三台服务器和/或磁盘故障修复,因为它只消耗约30%的开销。这比复制时候200%的开销要低得多。
这两个耐久性技术提供不同的价位和延迟特性。复制的延迟较低但是成本较高,擦除编码技术虽然可以降低成本(有时候高达50%),但是延迟又较高。我们可以通过使用不同的存储媒介,比如固态盘、磁盘和SMR设备来提供不同层级的服务来满足不同应用程序的需求。
从技术上讲,可以通过丰富存储需求来增加子集群的容量最终实现COS超团(supercluster)的扩展。然而,这将导致子群集间数据的重新平衡,也就意味着磁盘和网络长时间的频繁活动,从而影响到SLA。为了扩展COS,我们更倾向于把增加COS“超团”做成像增加存储农场一样。这一做法与我们目前基于设备的存储解决方案一致。
延迟优化
COS为雅虎的许多应用提供服务,所以必须得保证SLA的延迟,提供一致的、高品质用户体验。雅虎在Ceph上已经实施了40项优化,延迟表现平均提升了50%,其中延迟表现为99.99%的部分提升了70%。图2展示了Ceph读延迟优化前后的表现。

优化主要集中在以下这几个方面:
- 冗余并行读取与擦除编码:部署8/3擦除编码方案提升耐用性。把Ceph默认8个并行读的数据块增加到11个,在第一次对8个数据块进行检索时就对对象进行重构,从而显著改善读延迟。这样一来大约降低了40%的平均延迟。
- 数据恢复时的阀门:当磁盘和节点发生故障是,Ceph自动启动恢复,从而保证了高耐久性。但是在恢复过程中,存储节点处于忙碌状态导致较高的读/写延迟。为此,这里我们设置了可调的阀门来减轻这一影响,以减轻这种影响。这样可把数据恢复过程中的平均延迟降低60%。
- Bucket共享:亚马逊S3 API规范要求把存储的对象bucket化。 Ceph实现的bucket相当于一个托管在单个存储节点上的对象。在这里,承载bucket的存储节点成为热点,我们通过共享的bucket来缓解,共享的bucket可以跨越多个节点之间进行传播。
未来的开发
以上提到的和现在用到的都是COS在雅虎Flickr上的使用,雅虎其它用例中对于对象存储有不同的工作负载模型和不同的权衡。为把COS在雅虎更广泛的使用,我们将在未来做这些方面的开发。
- 规模上:我们已经初始部署了一个多PB级解决方案。在2015年,我们计划将其增长10倍以上,把它用到邮件,视频,Tumblr等,实现像在Flickr那样的增长。
- 地理复制实现业务连续性:目前,地理复制仅限于应用层。 Ceph支持也地理复制,但是,我们还没有测试Ceph在雅虎这种规模和延迟需求下的表现。我们计划在COS里部署地理复制。
- 优化小型对象的延迟:许多用例中都涉及到数量众多的缩略图,在图像搜索中需要对许多小的对象进行排序。我们需要调整COS来适应这种用例。
- 生命周期管理:软件定义存储的好处在于,可以通过对硬件和软件的选择来权衡性能和成本。对象存储在热、温和冷之间切换分层充分利用了它的灵活性来提供差异化的服务。