开源的最大魅力,是能够满足人们的探索欲和求知欲,让我们可以很深入地了解一个系统,如果我们发现它的设计或者实现中有任何不合理的或者错误的地方,我们可以提出自己的想法并且实现它,亲手来完善一个大家都在关注的事物,让无数人受益其中。今天我们就来聊一聊一个开源对象存储系统——OpenStack Swift。
1.Swift概述
Swift是一个提供RESTful HTTP接口的对象存储系统,最初起源于Rackspace的Cloud Files,目的是为了提供一个和AWS S3竞争的服务。
Swift于2010年开源,是OpenStack最初的两个项目之一。然而,在国内OpenStack圈里,不太能够听到关于Swift的声音,究其原因正如本系列的第一篇《文件系统vs对象存储——选型和趋势》中所说的,RESTful HTTP接口的对象存储,主要为互联网应用服务,而OpenStack厂商最关心的传统行业的用户目前能够应用这种存储模式的还不多。
但实际上,Swift在一些本土互联网公司确实是有一些成功的应用,包括新浪、美团、爱奇艺、凤凰网等。国外的应用更为广泛,早在2010年,Swift就迎来了第一个Rackspace之外的商用案例——韩国电信,大家很熟悉的维基百科、ebay等也是Swift的用户。相信随着互联网技术的应用架构逐渐被传统行业接受,对象存储和Swift将受到越来越广泛的关注。
从OpenStack Kilo版本的数据来看,Swift社区呈现出多元化的特点而且正在健康的发展。
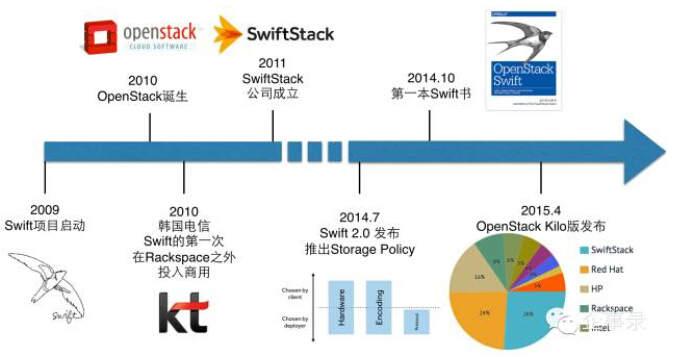
本文和本系列接下来的两篇,将介绍Swift的架构并给出规模部署的例子,从硬件配置开始一步步搭建一个Swift集群,总结Swift的特点并提出Swift面临的挑战和发展趋势。
2.Swift的数据组织结构
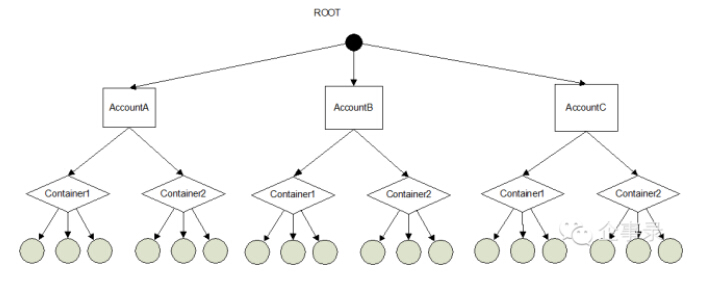
Swift将整个存储分为三个层次:Account、Container 和 Object。
这里的Account本身只是一个存储区域,并不代表认证系统里的“账号”,但是通常会让每个Account对应一个租户。这就是为什么我们作为一个OpenStack用户在使用Swift时,只能看到Container和Object,而看不到Account的原因,如果这个用户切换到另一个租户下,他将看到属于另一个租户也是是另一个Account下的Container和Object。
3Swift集群的架构
相对于OpenStack中的其他项目来说,Swift比较独立,用户可以选择将其单独部署,当然也可以与OpenSatck其他项目集成,甚至与Cloudfoundry和Docker集成。一般来说,Swift集群由两类节点组成:Proxy节点和Storage节点。一个简单的Swift集群如下图所示:

Proxy节点上主要运行Proxy Server服务进程,负责接收和响应用户的HTTP请求,Proxy Server是一个无状态的服务,可以很容易地进行横向扩展。由于Swift自身的认证服务只是一个测试用的TempAuth,所以通常需要使用一个外部的认证服务,或者在Proxy节点上安装额外的认证服务。如果我们有一个OpenStack环境,我们可以直接使用该环境中的Keystone,如果不需要和OpenStack的其他部分集成,也可以在Proxy节点上安装一个独立的Keystone来提供认证服务。
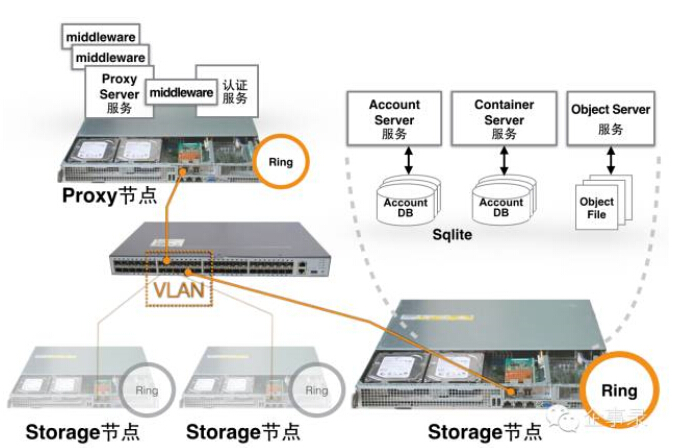
Storage节点上主要运行三类存储服务进程:Account Server、Container Server 和 Object Server,分别负责Account、Container、Object数据的存储,所以,在一些文献中又把存储节点称作ACO节点。
Proxy Server通过一种叫做Ring数据结构来确定数据存放在哪个存储节点上,Ring是一种经过改进的一致性哈希实现,可以将一份数据映射到多个设备,具体映射到几个设备上,取决于创建Ring时设定的副本数量。Swift 2.0版发布以后,用户可以利用存储策略(Storage Policy)功能给各个Container指定不同的副本数量,或者使用纠删码(Erasure Code),关于Swift中的存储策略请参考《OpenStack Swift 存储策略》( http://www.ibm.com/developerworks/cn/cloud/library/1411_limy_openstackswift/ )
在Swift中,每个Account和每个Container的信息分别存储在一个个独立的sqlite数据库里,也就是说,虽然在逻辑上来说,整个存储空间是分为Account、Container和Object三个层次,但是实际上每个Account、Container和每个Object一样,都对应到Storage节点上的一个文件。所以,Swift的整个存储空间是一个Flat Namespace,可以看做是一个K/V存储。
这也就不难理解为什么说Swift是全对等架构,因为这里面没有管理职能的元数据服务器,Account和Container的存储方式和Object并无本质区别,每个存储服务在集群里的地位都是等同的。Proxy Server根据REST请求中的URI的结构来确定用户请求的是一个Account、一个Container还是一个Object。

在一些文献中或者有些人在交流的时候,会把Account和Container信息称作Swift中的“元数据”,我不赞同这种说法,我也没有在Swift官方文档中的任何地方看到将这两类信息称为“元数据”的说法,它们和文件系统的元数据有本质的区别。事实上,在Swift中,元数据(metadata)指的是对象的属性(attribute),它是对象的描述信息,Swift借助xfs等底层机制的特性和将对象的属性/元数据和对象的数据放在一起存储。
如果我们希望扩展Swift的功能,比如在用户上传对象的时候进行查毒、数据压缩或者黄色图片等非法信息扫描,可以通过在Proxy Server上增加Middleware来实现,这里的Middleware(中间件)是Python WSGI框架中的一个概念,每个HTTP请求,都通过一层层中间件处理后传递给最核心的Proxy Server;Proxy Server产生的响应,也通过一层层中间件的处理最后返回给用户。事实上,Swift对Keystone的调用正是通过middleware来实现的。
4一个中等规模Swift部署实例
Swift集群的架构让我们可以很容易地扩展Proxy节点和存储节点的数量。一个中等规模Swift部署的例子如图所示:
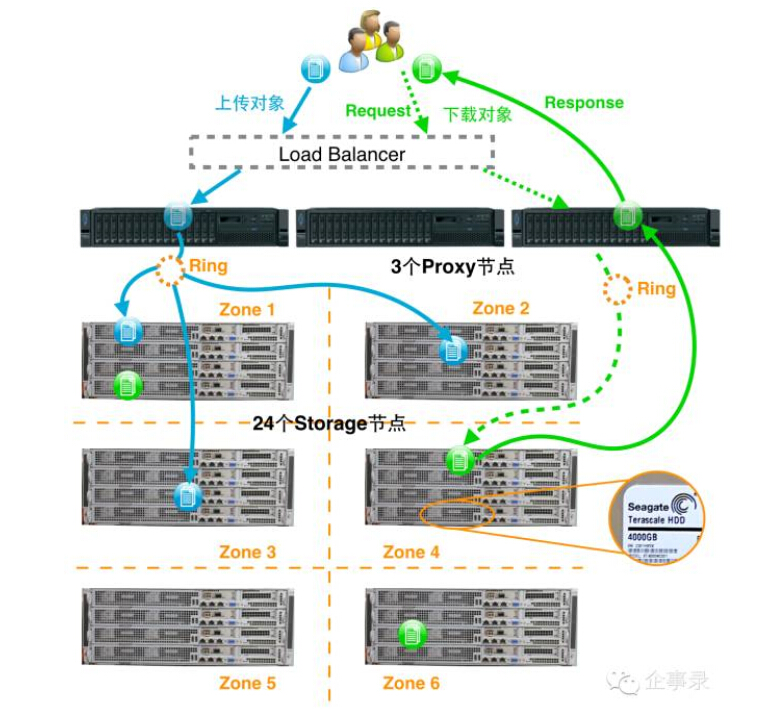
该案例中,Proxy节点使用Lenovo System X 3650服务器,计算能力较强,能够应对较高的并发访问,并方便以后在Swift上部署新的middleware以扩展其功能。
Storage节点使用存储密度较高的超云R6440-G9服务器(该服务器的具体情况和技术剖析请参考文章《旁观高密存储服务器(1):不择手段混合型》)6个满配的4U笼子共24个Storage节点,每节点12块希捷的3.5寸4T硬盘,能够提供约1.2 PB的物理存储空间,采用三副本策略,共提供384TB的存储容量。
Swift将存储节点分为多个zone,将副本保存到不同的zone中,一般来说,zone的数量应当大于或等于副本数量。
zone的划分原则为物理故障隔离,例如,我们可以按机柜来划分zone,也可以像图中那样把一个四节点笼子里的四台服务器划分到同一个zone里,分属不同笼子的节点划分到不同的zone。如果节点数量较少,也可以将每台服务器划分为一个zone。实验、开发、测试环境中也可以按照磁盘来划分zone,比如将一个服务器中的12块盘分到不同的zone中。