MySQL的字符集转换过程如下图:
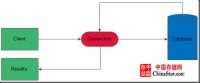
这个过程至少存在3个字符集的设置,客户端字符集、连接器字符集、服务器端字符集。其中连接器起到至关重要的作用,具体流程为,客户端向服务器端存数据时,客户端将自身字符集编码的数据发送到连接器,连接器选择一种字符集进行转换,然后再将转换好的字符集转换为服务端字符集,再发送给服务器端存储。当客户端向服务器端取数据时,以上过程相逆。
下图为一种场景:
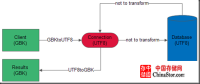
客户端为GBK编码,连接器为UTF8编码,服务器端也为UTF8编码。当客户端将GBK编码的数据发送到连接器时,连接器将GBK编码的数据转换为UTF8编码,暂存在连接器,之后连接器再将暂存的数据不进行任何转换发送到服务端存入数据库。客户端取数据时,将上述过程相逆。
这样场景可能存在一定的问题,如果数据库中本来就存储了只有UTF8编码下才有而GBK编码下没有的字符,在客户端取数据时,由连接器UTF8编码的字符再转换为GBK时就可能丢失字节。(如果场景只针对中国,可能不会存在什么问题。)
下图是另一种场景
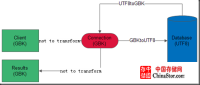
客户端还是GBK编码,连接器也是GBK编码,服务端还是UTF8编码。当客户端将GBK编码的数据发送到连接器是,连接器不进行转换,暂存在连接器,连接器再将暂存的GBK编码的数据转为UTF8编码发送到服务器。取数据时与上述过程相逆。这个场景也会出现丢失字节的现象。
根据以上场景分析,若想在MySQL不出现乱码,需要指定客户端的编码,让连接器不理解错误,这样就不会存入错误的数据,取数据的时候,要告诉连接器,返回结果的字符集,所以要设置3个字符集分别是:客户端字符集、返回结果字符集、连接器字符集。
看以下场景
#设置客户端字符集为GBKset character_set_client=gbk;
#设置连接器字符集为GBK
set character_set_connection=latin1;
#设置返回结果字符集为GBK
set character_set_results=gbk;
当客户端为GBK,连接器为latin1时,客户端字符集的容量比连接器的字符集的容量大,比如客户端包含中文汉字编码,但连接器却没有,当客户端有汉字数据发送到连接器时,连接器转为latin1时将丢失字节,就会产生乱码,而且这种乱码是不可修复的字节码丢失(上一篇 乱码的第2种情况)。
总结上面,Server字符集 >= Connection字符集 >= Client字符集。
set character_set_client=gbk;set character_set_connection=gbk;
set character_set_results=gbk;
#以上三条都设置为gbk,可以简写为以下形式
set namesgbk; ;