双机热备技术是高可用性解决方案的一种,其基本概念和原理之前已经说了很多了,双机热备份方案中,根据两台服务器的工作方式可以有三种不同的工作模式,即:双机热备模式、双机互备模式和双机双工模式(更多双机原理:双机热备基本概念、原理及应用场景介绍)。(IBM HACMP双机 - HP MCSG双机 - 微软 MSCS双机软件)
那么在实际应用中,如何选择适合自己服务器环境的双机热备软件?(双机热备/集群及高可用性软件产品的选择技巧)目前相关产品都有哪些?双机热备软件排名情况如何?
一、IBM HACMP双机系统(用于 AIX系统上的 IBM 高可用性解决方案)IBM AIX 6.1上安装hacmp7.1的详细指南
为什么需要高可用性?
什么是HACMP?(什么是双机热备)HACMP(High Availability Cluster Multi Processing)
High Availability:
• 系统可用性或运行时间最大化
• 系统宕机时间最小化
Multi Processing:
• 一个cluster里的各个节点上可以运行多个应用
• 共享数据或并发访问数据.
HACMP的目的
• 消除单点故障(SPOF),实现高可用
1、HACMP简介
HACMP(High Availability Cluster Multi Processing)双机备份软件包括两个组件:
- 高可用性:通过使用重复和/或共享资源来确保应用程序可供使用的过程。
- 集群多处理:运行在相同节点上并具有共享或并发数据访问的多个应用程序。
基于 HACMP 的高可用性解决方案提供了自动化的故障检测、诊断、应用程序恢复和节点重新集成。使用适当的应用程序,HACMP 还可以为并行处理应用程序提供并发数据访问,从而提供卓越的水平可伸缩性。
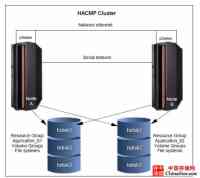
图一、典型的HACMP集群
2、HACMP 基本概念
HACMP 的基本概念可按如下方式进行分类:
- 集群拓扑
包含基本集群成员节点、网络、通信接口、通信设备和通信适配器。
- 集群资源
将要使其高度可用的实体(例如,文件系统、原始设备、服务 IP 标签和应用程序)。资源在资源组(resource group,RG)中分组在一起,HACMP 将资源组作为单个实体来保持其高度可用。
资源组可从单个节点使用,或在并发应用程序的情况下,可以同时从多个节点使用。
- 故障转移
表示资源组响应活动节点上的故障而从该活动节点转移到另一个节点(备份节点)。
- 退回
表示资源组在先前的节点变得可用时从备份节点转移到先前的节点。此转移通常是为了响应先前发生故障的节点的重新集成。
3、HACMP 术语
要理解 HACMP 的正确功能和用途,必须知道一些重要的术语:
- 集群 (Cluster)
独立系统(节点)或 LPAR 的松散耦合的集合,组织到一个网络中以便共享资源和彼此通信。
HACMP 定义了操作系统之间的关系,其中当某个集群节点无法提供服务时,对等的集群节点将提供该节点所提供的服务。
在任何集群组件发生故障的情况下,这些单独的节点共同维持一个或多个应用程序的功能。
- 节点 (Node)
运行 AIX 和 HACMP 的 IBM Eserver pSeries 计算机(或 LPAR),被定义为集群的一部分。每个节点都有一个资源集合(磁盘、
文件系统、IP 地址和应用程序),在节点发生故障的情况下,可以将该资源集合转移到集群中的另一个节点。
- 资源 (Resource)
资源是集群配置的逻辑组件,可从一个节点移动到另一个节点。提供高度可用的应用程序或服务所必需的所有逻辑资源在资源组 (RG) 中分组在一起。
在节点发生故障的情况下,资源组中的组件一起从一个节点移动到另一个节点。集群可能具有多个资源组,从而允许高效地使用集群节点(从而实现 HACMP 中的“多处理”)。
- 接管 (Takeover)
接管是指在集群内的节点之间转移资源的操作。
如果一个节点由于硬件问题或 AIX 崩溃而发生故障,其资源应用程序将移动到另一个节点。
- 客户端 (Client)
客户端是能够通过局域网访问运行在集群节点上的应用程序的系统。客户端运行客户端应用程序,连接到运行应用程序的服务器(节点)。
4、常见HACMP架构(两节点、多节点)
两节点HACMP拓扑结构示意图,如下:
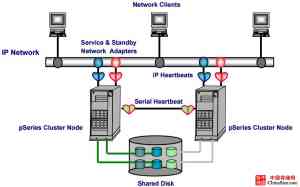
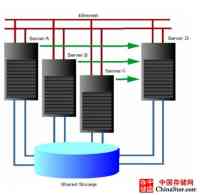
多节点HACMP(N+1)拓扑结构示意图,如下:
#p#HP MCSG双机软件#e#二、HP MCSG双机软件
1、MCSG简介
HP MC/ServiceGuard服务器应用软件可以帮助你使用800系列的HP9000服务器建立一个高可靠性的集群服务器系统。一个高可靠的系统是指即使计算机系统出现硬件和软件的故障,运行在该系统上的服务仍然可以继续使用,在一个环节(可能是一个系统处理单元、硬盘、LAN,软件系统等等)出了问题的时候,系统中的臃余部件可以接管错误部位的运行任务。 MC/ServiceGuard和其他高可靠部件一起实现并且协调这种发生错误时候的转换。
一个MC/ServiceGuard集群系统就是利用网络把一些800系列的HP9000服务器(称为节点)连接起来并且在系统中有足够的臃余硬件和软件来保证任何一个单独的错误并不显著的影响整个系统所提供的服务。
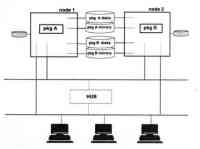
一个典型的集群系统的配置图,图中pkg A和pkg B分别是两个服务服务器,通过臃余网络连接。
2、HP MC/ServiceGuard运行的硬件环境
1) 集群系统组件的臃余:
为了保证系统的高可靠性,典型的集群系统组件通常情况下都应该有所臃余,比方说多个系统处理单元(SPU),两个或者两个以上的独立磁盘阵列;这样的方案能够避免单一的系统错误。通常情况下,系统的臃余度越高,在发生错误的时候能够保证你的程序、数据和支撑服务能够安全能力越高。除了硬件的臃余外,还必须要有一套支撑软件来实现在系统出错的时候控制服务(程序、数据)从一个SPU到另外一个SPU的转移。MC/ServiceGuard通过以下几个方面提供这种保证:
A. 在LAN出问题的时候MC/ServiceGuard能够切换到备用的LAN上去或者把相关的应用转移到备用的节点上;
B. 如果一个SPU出了问题,MC/ServiceGuard能够保证在最短的时间内将应用从出问题的SPU上转移到没有出问题的SPU上去;
C. 当应用程序出问题的时候,MC/ServiceGuard保证能够在该节点上从新启动应用程序或者转移到其他节点上去启动程序。
当然,MC/ServiceGuard也能够在你需要维护或者升级一个SPU的时候让你方便的将这个SPU上的应用程序转移到其他的SPU上去运行。目前为止,MC/ServiceGuard集群系统支持的最大节点数为8,可以在共享总线上同时4个节点上连接SCSI的硬盘或者磁盘阵列,如果是光钎总线的或,磁盘阵列可以同时连接8个节点。
2) 网络组件的臃余:
在网络连接中IP地址对应着网络接口(网卡等),分配有IP的接口叫做主接口,没有分配IP地址的接口叫做备用接口。当MC/ServiceGuard侦测到主接口发生错误的时候,它会将IP地址和绑定在这个IP地址上的服务全部转移到备用接口上去。
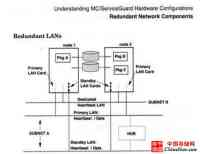
上图说明了网络冗余,对于每个Pkg,Pkg A和Pkg B来讲,都有一个主接口网卡(Primary LAN Card)和一个备用接口网卡(Standby LAN Cards),并且有SUBNET A和SUBNET B两个网络连接。
3)储存磁盘的臃余:在集群系统中每个节点都有自己的跟磁盘,并且每个节点都与多个在集群中的磁盘物理连接,从而使得不止一个节点可以访问与其应用程序相关的数据。这种访问能力由逻辑卷管理器(LVM)来管理。在同一时间内一个磁盘卷组并不能被超过一个的节点所控制,但是当应用程序转移的时候,这个磁盘卷组就可以被备用节点访问。 MC/ServiceGuard支持Single-ended和Fast/Wide类型的SCSI硬盘,同时支持HP FiberLink和FibreChannel。(注意:并不是所有的SCSI硬盘都支持,可以查阅HP 9000服务器的配置手册)
为了保护重要数据,需要使用以下两种方法中的一种来保护:一是使用镜相磁盘,一是使用了RAID或者PV Links的磁盘阵列。下图是使用磁盘阵列的集群系统。

三、微软 MCCS双机软件(Windows server 2008 + mscs 双机配置超详细图文完整手册)
随着 Microsoft 的群集服务在 Windows NT? 4 中引入以及在 Windows Server 2003 系列中正式提供,开发人员可使用一些简单工具在群集环境中部署应用程序。这些工具能够将群集中的应用程序登记为一般应用程序,并且能够通过编写 Windows 脚本的方式来控制应用程序的配置。
群集将两个或多个服务器连接在一起,使其对客户端呈现为单个计算机。在一个群集中连接服务器可以分担工作负载、实现单点操作/管理,并为满足增长的需求进行相应的调整提供了一种途径。因此,通过群集可以产生具有高可用性的应用程序。
Microsoft 服务器提供了三种支持群集的技术: 网络负载平衡 (NLB)、组件负载平衡 (CLB) 和 Microsoft 群集服务 (MSCS)。
通过 Microsoft 群集服务实现故障转移
MSCS 故障转移功能是通过群集中连接的多个计算机中的冗余实现的,每台计算机都具有独立的故障状态。为了实现冗余,需要在群集中的多个服务器上安装应用程序。但在任一时刻,应用程序只在一个节点上处于联机状态。当该应用程序出现故障或该服务器停机时,此应用程序将在另一个节点上重新启动。 Windows Server 2003 数据中心版支持在一个群集中最多包含 8 个节点。
每个节点都具有自己的内存、系统磁盘、操作系统和群集资源的子集。如果某一节点出现故障,另一个节点将接管故障节点的资源(此过程称为“故障转移”)。然后,Microsoft 群集服务将在新节点上注册资源的网络地址,以便将客户端流量路由至当前拥有该资源的可用系统。当故障资源恢复联机状态时,MSCS 可配置为适当地重新分配资源和客户端请求(此过程称为“故障恢复”)。要使应用程序恢复到发生故障转移时的那一点,节点必须能够访问保持应用程序状态的共享存储区。
请注意,Microsoft 群集服务旨在提供高可用性,而不是真正的容错功能。“容错”一词通常用于描述提供更高级别恢复功能的技术。容错服务器通常使用结合了特定软件的高级硬件或数据冗余,提供从单个硬件或软件故障近乎瞬时的恢复。这类解决方案的成本远远高于群集解决方案,因为您必须购买冗余硬件,而冗余硬件只不过闲置在那里用于故障恢复。Microsoft 群集服务使用价格适宜的标准硬件提供出色的高可用性解决方案,同时最大程度地利用计算资源。
Microsoft 群集服务基于无共享的群集模型。无共享模型规定,虽然群集中有多个节点可以访问设备或资源,但该资源在一个时刻只能由一个系统占有和管理。(在 MSCS 群集中,资源是指任何可以联机或脱机、可在群集中进行管理、一个时刻只能以一个节点作为宿主并可以在节点之间移动的物理组件或逻辑组件。)
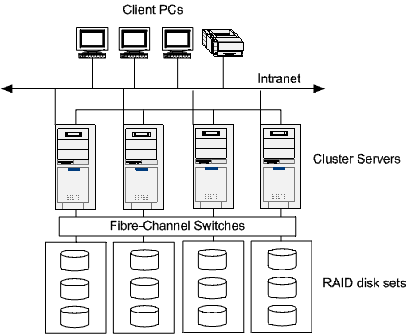
图 2. Microsoft 群集服务