AWS Disaster Recovery Whitepaper
最近在做一个容灾方案,了解到AWS有一个容灾的白皮书。
于是,今天粗略把 AWS 的容灾白皮书 读了一遍[1],白皮书中介绍了基于 AWS 的几种容灾方案。这些方案不仅仅适用于基于 AWS 的系统,也适用于通用系统。现将其关键点摘要下来,感兴趣的同学可以读一遍原文。
容灾两个术语
白皮书中提到了两个关于容灾的术语( industry terms)[2]
- Recovery Time Objective[3]
- Recovery Point Objective[4]
恕我孤陋寡闻,之前也参与过容灾的设计,但是关于这两个术语还是第一次知道。这两个术语在维基百科有定义,不确定是 AWS 开发者添加的词条还是很早就存在。话说我司每个产品也都有容灾方案,但是还没有人能总结出这么精准的 industry terms。所以说亚马逊作为这个领域的leader还是有道理的。
1. RTO 恢复耗时
主站点故障后,备站点恢复到达到OLA(operational level agreement )所耗费的时间。
用另外一句话就是主站点故障后,备站点恢复到正常提供服务状态所需要的时间。
站在用户视角,RTO是系统服务中断时间。
举个例子,如果主站点在12:00 故障了,系统容灾的RTO时8小时,那么系统必须在20:00前恢复并正常提供服务。
2. RPO 恢复时间点
主站点故障后,备站点能够恢复到过去哪个时间点的数据。
换句话说,备站点恢复后,与主站点相比,有多少数据丢失。
站在用户视角,RPO时数据丢失的量。
举个例子,如果主站点在12:00故障了,系统容灾的RPO是1小时,那么系统恢复后,其数据必须是到11:00的。也就是说允许丢失12:00~11:00 之间的数据。
所以以后在评判或设计一个容灾方案时候,先问这两个问题:
- RTO 值是多少
- RPO 值是多少
如果回答不上来,那么这个方案肯定是没想明白的。
容灾方案
白皮书中将容灾方案按照RTO以及成本排序,称为容灾方案图谱。
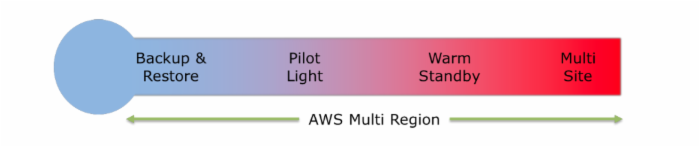
Backup and Restore
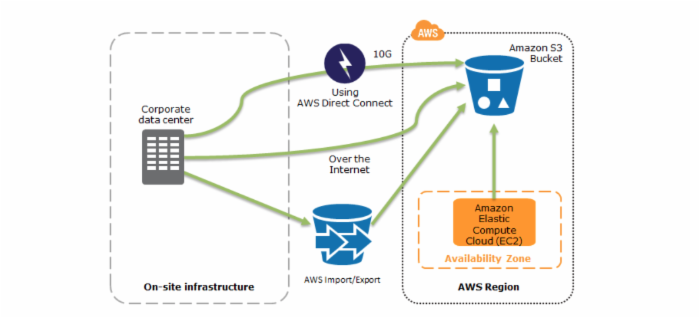
备份恢复是最常见的一种容灾手段,将主站点数据备份到与主站点隔离的存储设备。当生产环境故障后,能够在备站点将数据恢复。
AWS提供了一系列的高可靠存储服务:
- Amazon S3,简单对象存储,11个9可靠性
- Amazon Glacier,如果觉得S3太贵的话
- Amazon VTS,虚拟磁带存储,如果要保存巨大且时间长的数据的话
使用Amazon的这些存储服务,加上备份恢复工具,就可以实现一个容灾系统。
备份示意图
恢复示意图
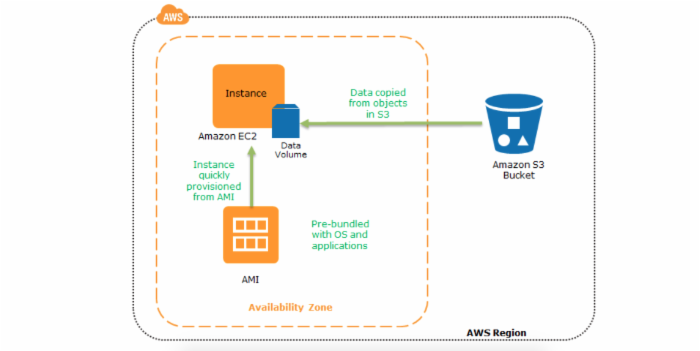
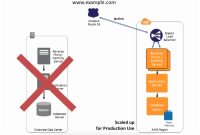
Pilot Light
Pilot Light 是一个装置,这个是一个类似点火器的装置,如煤气灶的点火器,通过点火器可以把煤气灶点燃,然后就可以做饭了:)
Pilot Light用到容灾系统中,要表达的意思是,在备站点部署一个服务,通过这个服务可以将整个系统运行起来。
准备
- 备站点安装数据库服务,并建立与主站点之间的数据复制关系
- 主站点的操作系统或文件做成 AMI ,在备站点恢复时候直接加载为EC2
- 定期测试备站点的恢复[5]
恢复
- 使用 AMI 创建 EC2
- 根据情况加大数据服务器的配置
- 增加额外的数据服务器(如果有需要)
- 配置系统(一些配置不是通过 AMI 导入就可以生效的)
- 将 DNS 映射为备站点IP地址[6]
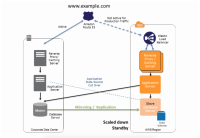
Warm Standby
Warm Standby 是在备站点复制了主站点,但是它们还是有差别的:
- 备站点服务运行但是不对外提供服务
- 备站点的服务器配置是最小配置(These servers can be running on a minimum-sized fleet of Amazon EC2 instances on the smallest sizes possible) ( fleet of Amazon EC2 好霸气~~)
准备
- 备站点安装数据库服务并同步数据
- 备站点申请最小配置的EC2安装并app
- 定时执行app的升级和补丁,保持与主站点一致
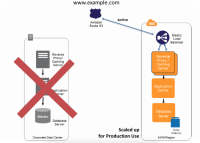
恢复
- 增加EC2数量(横向扩展)(扩成与主站点一致)
- 增加EC2配置(纵向扩展)(扩成与主站点一致)
- 增加数据库实例数(扩成与主站点一致)
- 切换 DNS 映射到备站点
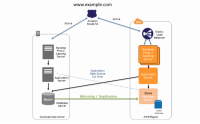
Multi Site
Multi Site 指的是 active-active 的容灾方案。主备站点同时对外提供服务,由DNS根据负载决定将请求转发到哪个站点。
准备
- 将主站点系统复制到备站点,服务器和配置都相同
- 在DNS上配置路由策略
恢复
- 手动切换(DNS上切换)
- 或者配置DNS failover
Fail Back
当主站点故障修复后,我们还需要将服务切换到主站点,这个过程称为 fail back 。
不同的容灾方案,fail back的方法不一样。
Backup and Restore
- 冻结备站点的修改操作
- 备份数据
- 恢复到主站点
- 切换DNS指向主站点
- 解冻
Pilot light, warm standby, and multi-site
- 冻结备站点的修改操作
- 将数据复制方向改为从主向备
- 切换DNS指向主站点
- 解冻