前言
社交网络事业群拥有众多海量规模的业务,在海量的运营压力下,服务器设备的数量也突破了10w大关,并有序的分布在全国不同的IDC中实现异地容灾的高可用架构。
但正因为社交业务的多IDC管理的复杂性,使运维小伙伴们经常会遇见一些难搞定的场景,如运营商网络出口异常流量骤降、网络延时突增、IDC断电断网、光纤被挖断等突发事件,假设没有第一时间发现和处理好这些事件,就会有较大的机率影响腾讯社交产品的服务质量,甚至会造成用户大范围的登录与访问中断。
如何在种种不可控的突发情况来临时,业务能在用户“零感知”的情况下第一时间恢复服务质量呢?这就需要我们的业务要有健壮的异地容灾架构与快速的全网调度能力。
本文介绍的是手机QQ与Qzone两个服务于海量用户的平台级业务,在无损用户服务质量的基准原则下,通过亿量级人次的限时调度实战演习来验证我们的异地容灾架构与快速调度能力。
- 三地三活的容灾能力
- 风驰电掣的调度能力
- 3亿人次的实战演习
一、三地三活的容灾能力
海量服务之道就是要给亿级用户持续提供高质量与分级可控的服务,所有的研发与运维行为都应该围绕保障与提升用户服务质量展开,面对种种不可控的突发情况时,恢复业务的服务质量为最高优先级要务。
让我们把时间拨回一年前,2015年8.13日天津爆炸事件,相信很多的互联网从业人员都印象颇深,腾讯天津数据中心距离起爆点直线距离仅一公里,可能会受到波及,华北7000多万QQ用户将面临着登陆和访问中断的可能,那天晚上我们通过多次调度与柔性控制,在用户“零感知”的情况下,顺利的将天津全量用户调回深圳。
容灾能力是服务于业务,随着业务的持续发展。现在我们的整体容灾架构是三地分布,三地三活,在各业务分布上实现set化部署,链路均衡分布,完善容量架构,从而减少风险。
QQ与Qzone的容灾能力演进主路线也是单地—>双地—>三地,三地分布也提升了服务质量,方便用户更加的就近接入。
- QQ与Qzone用户数据三地均匀分布1:1:1;
- 单地常态负载不高于66%两地容一地,可在用户“零感知”的情况下,将用户调往三地之一;
为了行文方便,后续出现“双平台”字眼时,如无特殊说明均指“QQ+Qzone”的统一体。
二、风驰电掣的调度能力
对于调度用户,一般都是从流量入口即接入层分流用户,双平台也沿用与此思路。
1.手机QQ接入层
前端支撑手Q2.59亿同时在线用户,后端连接几百个业务模块,接入层上千台机器主要分布在三大城市的数十个IDC,每分钟处理20多亿个业务包,7*24小时不间断为亿万用户提供着稳定的接入服务……这就是手Q接入层SSO。
手Q终端与SSO之间并不是直连的,两者之间还加入了TGW,TGW全称是TencentGateway,它是公司内部自主研发的一套多网统一接入,支持负载均衡的系统;它具有可靠性高、扩展性强、性能好、抗攻击能力强等特点。加入TGW后终端与SSO、后台之间的关系如下图所示:
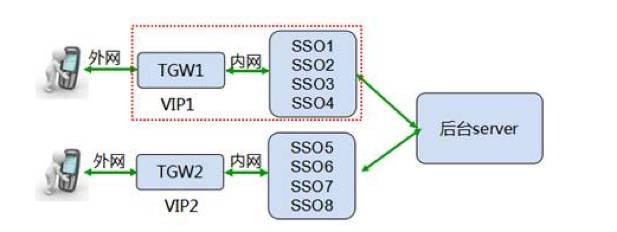
QQ用户登录概要流程如下图所示:
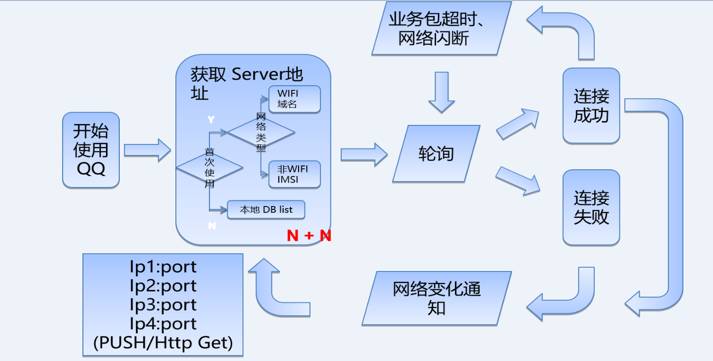
Qzone的主要流量入口来自手Q,因此双平台用户可以联动调度。
2. 调度能力介绍
调度动作概要来说就是干预用户的接入点,下图是一个非常概要的流程:
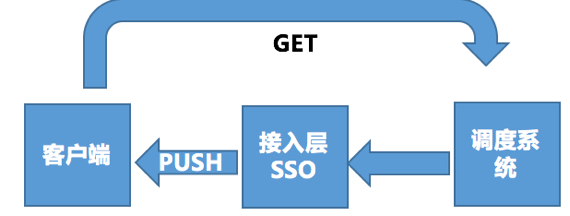
根据业务发展的推动与场景的细化,双平台的调度能力主要为两个方向。
测速调度:
- 全网网络质量的最优路径测算;
- 实时干预能力即将用户调度到最优路径上;
- 更细力度调度 如按网关ip调度;
重定向调度:
- 禁用VIP新建客户端链接;
- 将原VIP已登录用户重定向到新VIP;
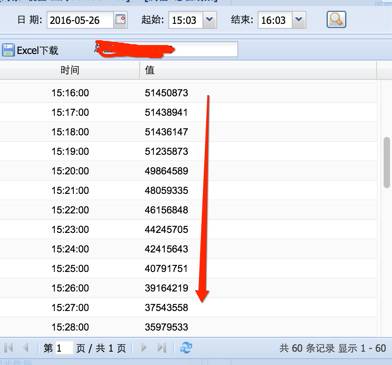
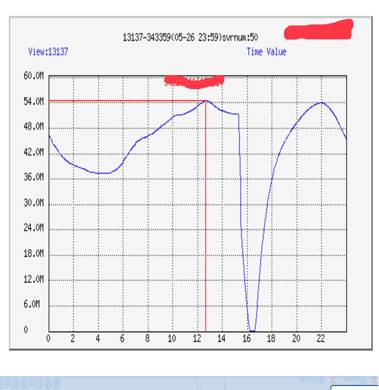
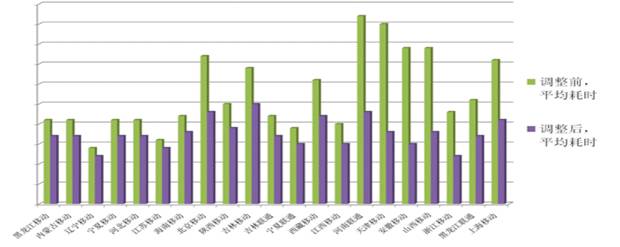
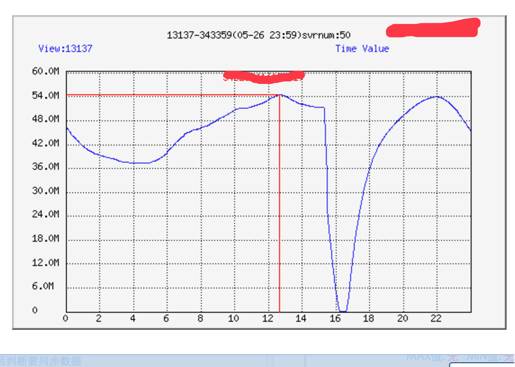
在对后台无冲击压力的情况下,我们可以完成千万在线用户10分钟之内调度完毕,并且在调度期间用户无感知 ,上图就是我们在单次调度时清空一地在线用户数的下降速率。
调度场景:
- 三地用户常态分布比例选用全网质量测速调度;
- 紧急事件时选用快速的重定向调度方式;
- 非极端情况下不会选用跨运营商调度,例如将电信用户调往联通;
调度操作:
- 分钟级完成调度配置,并实时计算下发;
- 全自动化估算三地容量变化;
三、3亿人次的实战演习
我们先来看两个场景,相信这两个场景运维小伙伴或多或少都可能经历过。
故事场景1:
某个电闪雷鸣、风雨交加的夜晚,运维小哥正舒服的窝在床上看着电影,突然手机一波告警袭来,N个服务延时集体飙高,经排查是运营商网络出口异常,运营商也暂时未能反馈修复时间,经评估后快速根本的解决方法就是将故障城市的xxx万用户调度到B城市,运维小哥正准备使出洪荒之力乾坤大挪移的将用户移走,但杯具的是调度系统掉链子了,调度任务计算与下发异常,极速吼上相关同学排查调度系统问题,同时开启后台柔性撑过故障期。
故事场景2:
活动开始,用户量逐步攀升,并且有地域聚集现象,A城市的整体负载已经偏高了,需要迁移XXX万用户调度到B城市,以便减少A的整体负载,在调度过程中发现B因某条业务链路的短板,所能承载的增量用户要小于前期建设评估的整体用户量,增量压过去,会把B压垮。
上面两个场景,直接折射出问题是什么?
只有通过实际场景检验的能力,才是我们运维手里真正可用的武器,而不是在军械库里放着,只是在盘点的时候“具备”的能力。
1. 为什么要现网演习?

容灾能力与容量架构把控是海量运维必修内功,能力的锻炼就是要通过不断的实战演习得来,要让我们所“具备”的能力变为关键时刻的武器。
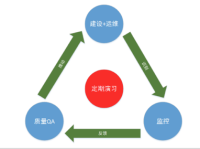
如上图所示,通过一个完整的闭环流程,来不断的精耕细作以便提升我们的能力,通过实战将问题暴露出来,避免紧急事件时的被动。
2. 如何规划演习?
QQ是一个体量非常之大的业务(DAU:8.3亿),业务功能树复杂,一个叶子节点的异常就有可能导致大范围用户的有损体验与投诉。假设演习期间某个环节有问题,将有可能导致一个大范围的事故。
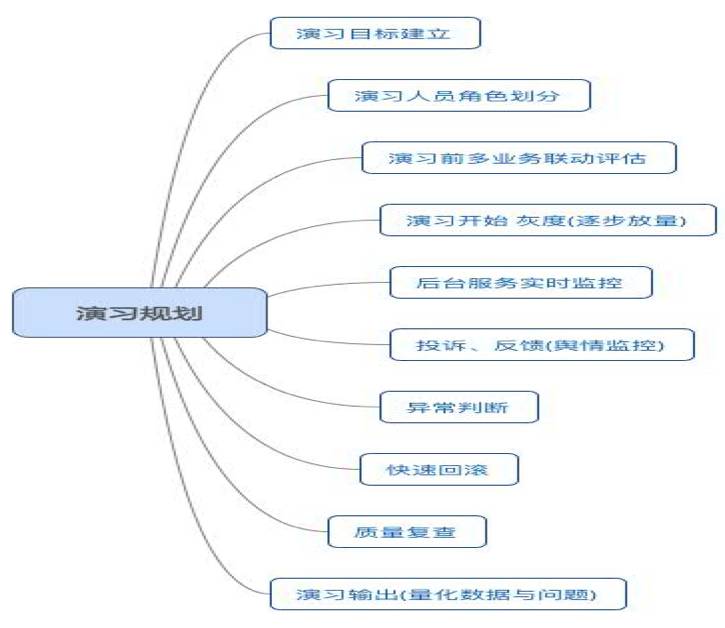
我们在思考如何安全落地演习的时候,也主要基于以上纬度的考虑。话说不打无准备的仗,事前评估越完善,相应的就能提升我们整体演习的成功率,下图就是我们最终落地的一个可执行的详细演习流程图。
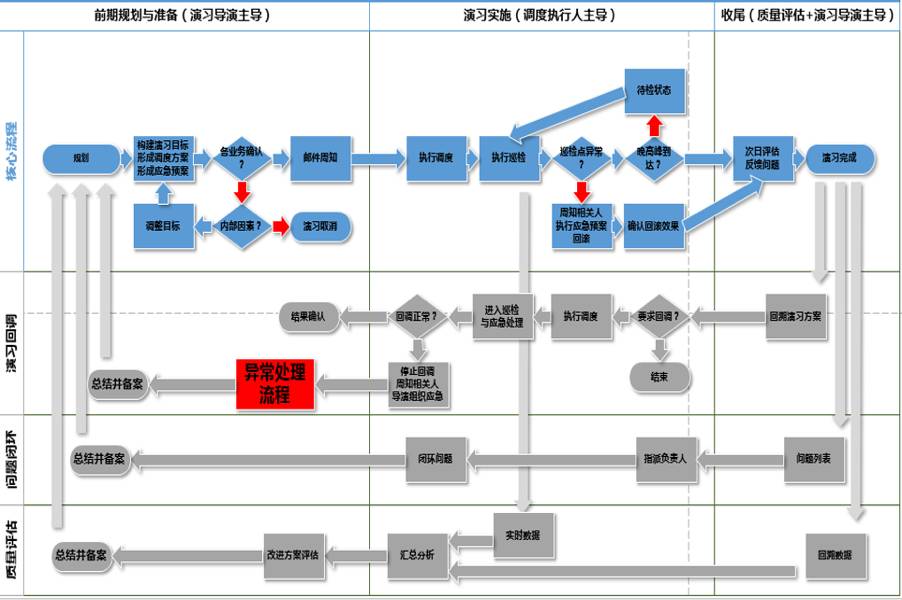
如上图所示 演习也是一个节点较多的闭环流程,生命周期主要分为以下三部分
- 演习前期规划与准备;
- 演习实施,过程监控;
- 演习结束,整体质量评估与问题跟踪;
3. 演习的目标
要通过演习生产出我们所需的数据与检验我们的业务质量,双平台是服务于海量用户,全网业务链路复杂,我们期望能从下面三个维度检验我们的能力。
验证业务质量与容量:
- 通过实战演习验证三地条带化容量建设是否符合预期?
- 每增加千万用户时整体与关键业务链路负载是否可控?
- 短时间内因千万用户集中登录与关联行为所产生的压力后台是否能抗的住?
- 柔性控制是否符合预期?
量化调度能力:
- 异地调度时每分钟能迁移走多少用户?
- 异地调度1000W用户需要多少时间?
- 清空一个城市的用户需要多少时间?
- 调度速率是否均衡稳定?
运营平台:
- 现有的平台能力(实时容量、地区容量、调度平台、业务质量监控)是否能较好的支撑到演习与实际场景调度;
- 发现平台能力的短板,以容量指标来及时度量调度的效果;
4. 演习效果
我们坚持月度/季度的实际演习调度,并在业务峰值实施调度演习。整个演习期间用户“零感知”,业务质量无损,无一例用户投诉。如此量级的演习在双平台的历史上也属于首次。演习也是灰度逐步递进的节奏,下面图例展示了,我们对一个城市持续三次的调度演习,用户量级也是逐步增多 2000W?4000W?清空一个城市。
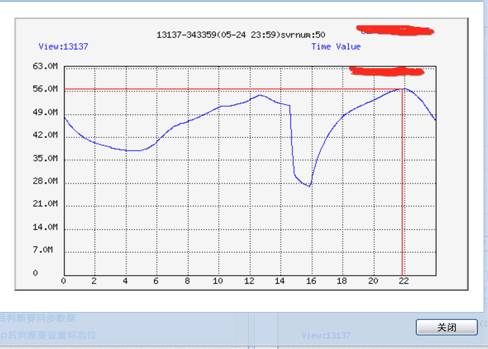
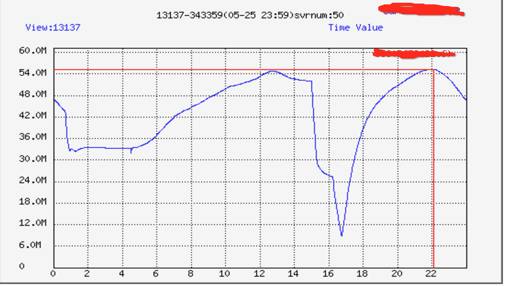
如上图所示 演习也是一个节点较多的闭环流程,生命周期主要分为以下三部分
- 演习前期规划与准备;
- 演习实施,过程监控;
- 演习结束,整体质量评估与问题跟踪;
3. 演习的目标
要通过演习生产出我们所需的数据与检验我们的业务质量,双平台是服务于海量用户,全网业务链路复杂,我们期望能从下面三个维度检验我们的能力。
验证业务质量与容量:
- 通过实战演习验证三地条带化容量建设是否符合预期?
- 每增加千万用户时整体与关键业务链路负载是否可控?
- 短时间内因千万用户集中登录与关联行为所产生的压力后台是否能抗的住?
- 柔性控制是否符合预期?
量化调度能力:
- 异地调度时每分钟能迁移走多少用户?
- 异地调度1000W用户需要多少时间?
- 清空一个城市的用户需要多少时间?
- 调度速率是否均衡稳定?
运营平台:
- 现有的平台能力(实时容量、地区容量、调度平台、业务质量监控)是否能较好的支撑到演习与实际场景调度;
- 发现平台能力的短板,以容量指标来及时度量调度的效果;
4. 演习效果
我们坚持月度/季度的实际演习调度,并在业务峰值实施调度演习。整个演习期间用户“零感知”,业务质量无损,无一例用户投诉。如此量级的演习在双平台的历史上也属于首次。演习也是灰度逐步递进的节奏,下面图例展示了,我们对一个城市持续三次的调度演习,用户量级也是逐步增多 2000W?4000W?清空一个城市。

- 调度质量
- 调度效率是否符合预期:例如计划10分钟迁移多少用户量;
- 调度速率是否可控:调度的用户量细化到分钟粒度应该是基本均等,不能忽快忽慢;
- 调度量级是否符合预期:整体迁移用户量级稳定可控;
- 业务质量
- 调度期间是否有用户共性投诉反馈;
- 后台服务质量是否可控;
- 监控系统是否有批量告警;
- 业务负载增长是否符合预期;
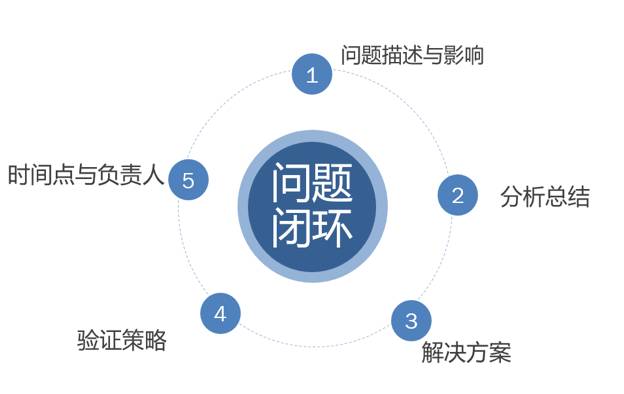
6. 演习流程的闭环跟踪
演习的目的就是在于发现问题而不是秀肌肉,暴露的问题越多越好,每个问题都要完全闭环,帮助业务架构和运维能力持续优化与完善。
总结
在海量用户场景与复杂的互联网环境下,全网调度要做到 调度用户量精准与快速调度用户,其实也是一个蛮复杂坑也蛮多的的事情,通过这9次的实战演习,我们的调度平台、业务架构、调度速率均还有继续优化深挖的空间。这里并不是说单独有一个很强大的调度平台就可以了,而是一个环环相扣的闭环。
作者介绍:
李光
现就职于腾讯SNG社交网络运营部,负责SNG移动类产品的业务运维,同时也负责运营平台规划与运维产品运营推广工作