6月11日(美国时间),Spark 1.4版本正式发布,在Spark Core、Spark Streaming、Spark SQL(DataFrame)、Spark ML/MLlib等升级之外,新版本更加入了数据科学家们望眼欲穿的SparkR组件。长话短说,下面一起看Databricks Blog上关于SparkR的介绍,以及七牛技术总监陈超在ChinaScala微信号上对组件升级的总结。
SparkR简介(Announcing SparkR: R on Spark via Databircks Blog by Shivaram Venkataraman)
项目历史
SparkR源于AMPLab,是将R易用性和Spark扩展性整合的一个探索。在这个前提之下,SparkR开发者预览版最早在2014年1月开源。随后的一年,SparkR在AMPLab得到了飞速发展,而在许多贡献者的努力下,SparkR在性能和可用性上得到了显著提升。最近,SparkR被合并到Spark项目,并在1.4版本中作为alpha组件发布。
SparkR DataFrames
在Spark 1.4中,SparkR 的核心组件是SparkR DataFrames——在Spark上实现的一个分布式data frame。data frame 是R中处理数据的基本数据结构,而当下这个概念已经通过函数库(比如Pandas)扩展到其它所有语言。而像dplyr这样的项目更去除了基于data frames数据操作任务中存在的大量复杂性。在SparkR DataFrames中,一个类似dplyr和原生R data frame的API被发布,同时它还可以依托Spark,对大型数据集进行分布式计算。
下面例子将展示SparkR DataFrames API的一些特性。(你可以在这里看到完整示例)
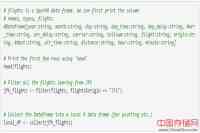
更全面的 DataFrames介绍参见SparkR编程指南。
SparkR整合的好处
在更易用的API之外,SparkR从Spark的紧密整合中继承了诸多好处。这些包括:
- Data Sources API:通过Spark SQL的数据源API,API SparkR可以从包括Hive tables、JSON files、Parquet files等各种来源中读取数据。
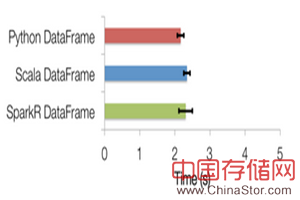
- Data Frame优化:SparkR DataFrames还继承了计算引擎中的大量优化,比如代码生成和内存管理。例如,下面图表是单机R、Python和Scala在1000万整数对上的group-by聚合操作运行时性能对比(使用了相同的数据集,参考这里)。如图所示,在计算引擎中优化可以使SparkR的性能表现类似于Scala和Python。
- 可便捷地扩展到多核和多主机:在SparkR DataFrames 上执行的操作会被自动分配到Spark群集中所有可用的内核和机器上。因此,在配备了数千主机后,SparkR DataFrames 可以被用于TB数据的处理。
在未来的版本中,许多功能已经被计划添加到SparkR:其中包括高级别的机器学习算法支持,并将SparkR DataFrames 打造成Spark密不可分的组件。
Spark Core、Spark Streaming、Spark SQL、Spark ML/MLlib在Spark 1.4中的提升(Spark 1.4 新特性概述 by 陈超)
Spark Core
现在大家最关心什么?无疑就是性能和运维!什么最影响性能?shuffle首当其冲!什么又是运维第一要务?必须是监控呀(就先不扯alert了)!1.4在这两点都做足了功夫。 1.4中,Spark为应用提供了REST API来获取各种信息(jobs / stages / tasks / storage info),使用这个API搭建个自己的监控简直是分分钟的事情,不止于此,DAG现在也能可视化了,不清楚Spark的DAGScheduler怎么运作的同学,现在也能非常轻易地知道DAG细节了。再来说说shuffle,大家都知道,从1.2开始sort-based shuffle已经成为默认的shuffe策略了,基于sort的shuffle不需要同时打开很多文件,并且也能减少中间文件的生成,但是带来的问题是在JVM的heap中留了大量的java对象,1.4开始,shuffle的map阶段的输出会被序列化,这会带来两个好处:1、spill到磁盘上的文件变小了 2、GC效率大增,有人又会说,序列化反序列化会产生额外的cpu开销啊,事实上,shuffle过程往往都是IO密集型的操作,带来的这点cpu开销,是可以接受。
大家期待的钨丝计划(Project Tungsten)也在1.4初露锋芒,引入了新的shuffle manager “UnsafeShuffleManager”,用以提供缓存友好的排序算法,及其它一些改进,目的是降低shuffle过程中的内存使用量,并且加速排序过程。钨丝计划必定会成为接下来两个版本(1.5,1.6)重点关注的地方。
Spark Streaming
Streaming在这个版本中增加了新的UI,简直是Streaming用户的福音,各种详细信息尽收眼底。话说Spark中国峰会上,TD当时坐我旁边review这部分的code,悄悄对说我”this is awesome”。对了,这部分主要是由朱诗雄做的,虽然诗雄在峰会上放了我鸽子,但必须感谢他给我们带来了这么好的特性!另外此版本也支持了0.8.2.x的Kafka版本。
Spark SQL(DataFrame)
支持老牌的ORCFile了,虽然比Parquet年轻,但是人家bug少啊 : ) 1.4提供了类似于Hive中的window function,还是比较实用的。本次对于join的优化还是比较给力的,特别是针对那种比较大的join,大家可以体会下。JDBC Server的用户肯定非常开心了,因为终于有UI可以看了呀。
Spark ML/MLlib
ML pipelines从alpha毕业了,大家对于ML pipelines的热情还真的蛮高的啊。我对Personalized PageRank with GraphX倒是蛮感兴趣的,与之相关的是recommendAll in matrix factorization model。事实上大多数公司还是会在Spark上实现自己的算法。
先写到这,后续会写一写钨丝计划及SparkR的相关文章。对了,求靠谱前端工程师一枚,要求看我置顶微博(@CrazyJvm),同时也招收若干优秀实习生。