之前,我们展示了在Spark1.4.0中 新推出的可视化功能 (《Spark 1.4:SparkR发布,钨丝计划锋芒初露》[中文版]),用以更好的了解Spark应用程序的行为。接着这个主题,这篇博文将重点介绍为理解Spark Streaming应用程序而引入的新的可视化功能。我们已经更新了Spark UI中的Streaming标签页来显示以下信息:
- 时间轴视图和事件率统计,调度延迟统计以及以往的批处理时间统计
- 每个批次中所有JOB的详细信息
此外,为了理解在Streaming操作上下文中job的执行情况,有向无环执行图的可视化( execution DAG visualization )增加了Streaming的信息。
让我们通过一个从头到尾分析Streaming应用程序的例子详细看一下上面这些新的功能。
处理趋势的时间轴和直方图
当我们调试一个Spark Streaming应用程序的时候,我们更希望看到数据正在以什么样的速率被接收以及每个批次的处理时间是多少。Streaming标签页中新的UI能够让你很容易的看到目前的值和之前1000个批次的趋势情况。当你在运行一个Streaming应用程序的时候,如果你去访问Spark UI中的Streaming标签页,你将会看到类似下面图一的一些东西(红色的字母,例如[A],是我们的注释,并不是UI的一部分)。

图1:Spark UI中的Streaming标签页
第一行(标记为 [A])展示了Streaming应用程序当前的状态;在这个例子中,应用已经以1秒的批处理间隔运行了将近40分钟;在它下面是输入速率(Input rate)的时间轴(标记为 [B]),显示了Streaming应用从它所有的源头以大约49 events每秒的速度接收数据。在这个例子中,时间轴显示了在中间位置(标记为[C])平均速率有明显的下降,在时间轴快结束的地方应用又恢复了。如果你想得到更多详细的信息,你可以点击 Input Rate旁边(靠近[B])的下拉列表来显示每个源头各自的时间轴,正如下面图2所示:

图2
图2显示了这个应用有两个来源,(SocketReceiver-0和 SocketReceiver-1),其中的一个导致了整个接收速率的下降,因为它在接收数据的过程中停止了一段时间。
这一页再向下(在图1中标记为 [D] ),处理时间(Processing Time)的时间轴显示,这些批次大约在平均20毫秒内被处理完成,和批处理间隔(在本例中是1s)相比花费的处理时间更少,意味着调度延迟(被定义为:一个批次等待之前批次处理完成的时间,被标记为 [E])几乎是零,因为这些批次在创建的时候就已经被处理了。调度延迟是你的Streaming引用程序是否稳定的关键所在,UI的新功能使得对它的监控更加容易。
批次细节
再次参照图1,你可能很好奇,为什么向右的一些批次花费更长的时间才能完成(注意图1中的[F])。你可以通过UI轻松的分析原因。首先,你可以点击时间轴视图中批处理时间比较长的点,这将会在页面下方产生一个关于完成批次的详细信息列表。

图3
它将显示这个批次的所有主要信息(在上图3中以绿色高亮显示)。正如你所看到的,这个批次较之其他批次有更长的处理时间。另一个很明显的问题是:到底是哪个spark job引起了这个批次的处理时间过长。你可以通过点击Batch Time(第一列中的蓝色链接),这将带你看到对应批次的详细信息,向你展示输出操作和它们的spark job,正如图4所示。

图4
图4显示有一个输出操作,它产生了3个spark job。你可以点击job ID链接继续深入到stages和tasks做更深入的分析。
Streaming RDDs的有向无环执行图
一旦你开始分析批处理job产生的stages和tasks,更加深入的理解执行图将非常有用。正如之前的博文所说,Spark1.4.0加入了有向无环执行图(execution DAG )的可视化(DAG即有向无环图),它显示了RDD的依赖关系链以及如何处理RDD和一系列相关的stages。如果在一个Streaming应用程序中,这些RDD是通过DStreams产生的,那么可视化将展示额外的Streaming语义。让我们从一个简单的Streaming字数统计(word count)程序开始,我们将统计每个批次接收的字数。程序示例 NetworkWordCount 。它使用DStream操作flatMap, map和 reduceByKey 来计算字数。任一个批次中一个Spark job的有向无环执行图将会是如下图5所示。

图5
可视化展示中的黑点代表着在批处理时16:06:50由DStream产生的RDD。蓝色阴影的正方形是指用来转换RDD的DStream操作,粉色的方框代表这些转换操作执行的阶段。总之图5显示了如下信息:
- 数据是在批处理时间16:06:50通过一个socket文本流( socket text stream )接收的。
- Job用了两个stage和flatMap , map , reduceByKey 转换操作来计算数据中的字数
尽管这是一个简单的图表,它可以通过增加更多的输入流和类似window操作和updateStateByKey操作等高级的DStream转换而变得更加复杂。例如,如果我们通过一个含三个批次的移动窗口来计算字数(即使用reduceByKeyAndWindow),它的数据来自两个socket文本流,那么,一个批处理job的有向无环执行图将会像如下图6所示。

图6
图6显示了于一个跨3个批次统计字数的Spark job的许多相关信息:
- 前三个stage实际上是各自统计窗口中3个批次的字数。这有点像上面例子 NetworkWordCount 的第一个stage,使用的是map和flatmap操作。不过要注意以下不同点:
- 这里有两个输入RDD,分别来自两个socket文本流,这两个RDD通过union结合成一个RDD,然后进一步转换,产生每个批次的中间统计结果。
- 其中的两个stage都变灰了,因为两个较旧批次的中间结果已经缓存在内存中,因此不需要再次计算,只有最近的批次需要从头开始计算。
- 最后一个右边的stage使用reduceByKeyAndWindow 来联合每个批次的统计字数最终形成一个“窗口”的字数。
这些可视化使得开发人员不仅能够监控Streaming应用程序的状态和趋势,而且能够理解它们与底层spark job和执行计划的关系。
未来方向
Spark1.5.0中备受期待的一个重要提升是关于每个批次( JIRA , PR )中输入数据的更多信息。例如:如果你正在使用Kafka,批处理详细信息页面将会显示这个批次处理的topics, partitions和offsets,预览如下图:
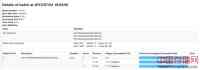
图7
备注:本文中的所有图片均是大图(有的超过3000PX),还请点击下面的原文链接获取高清大图。
英文原文: New Visualizations for Understanding Spark Streaming Applications(译者/付军 审校/朱正贵 责编/仲浩)
关于译者: 付军,平安科技资深开发工程师,主要做数据处理及报表展示方面工作,关注Hive、Spark SQL等大数据处理技术。
【预告】
首届中国人工智能大会(CCAI 2015)将于7月26-27日在北京友谊宾馆召开。机器学习与模式识别、大数据的机遇与挑战、人工智能与认知科学、智能机器人四个主题专家云集。人工智能产品库将同步上线,预约咨询:QQ:1192936057。欢迎关注。