
2015年6月15日-17日,Spark Summit 2015于美国旧金山举行,近2000位技术专家见证和参与了这次盛会。历时三天的会议里,来自Databricks、UC Berkeley AMPLab、Baidu、Alibaba、Yahoo!、Intel、Amazon、Red Hat、Microsoft等数十个机构共分享了近100个精彩纷呈的报告,其中Keynotes演讲主要集中在前两日的上午,下午则分为开发者、数据科学、应用和用户案例分会场,整个会议的第三天是由培训构成。与往年一样,Keynotes的分享主要采取特性分享加Demo演示,唯一区别就是本次峰会的Demo演示时间稍微显长。
2015 Spark Summit 之我见——Day 1

图1:Databricks的CTO Matei Zaharia
在此次峰会里感受最深的就是中国的Spark发展太快了,Spark发起人Databricks的CTO Matei Zaharia在Keynotes重点指出:Spark最大的集群来自腾讯——8000个节点,单个Job最大分别是阿里巴巴和Databricks——1PB,震撼人心!同时,截止2015年6月,Spark的Contributor比2014年涨了3倍,达到730人;总代码行数也比2014年涨了2倍多,达到40万行。

图2:Spark的大规模应用
此外,以Spark为中心的开源生态系统,从应用、运行环境、数据源等方面都有巨大的发展,基本囊括了与大数据相关的所有系统,具体请看下图:

图3:Spark连接开源大数据生态系统
Matei Zaharia在演讲中表示,当下Spark最重要的核心组件仍然是Spark SQL。而在未来的几次发布中,除了性能上的更加优化外(包括代码生成和快速Join操作),还要提供对SQL语句的扩展和更好地集成。2015年发展的重点将是数据科学和平台API化,除了传统的统计算法外,还包括学习算法,使得SparkR得到了长足的发展,同时也会使Spark的生态系统越来越完善。此外,还有Tungsten项目和DAG可视化、调试工具等同样是持续的重点发展方向。
被Google收购的Timeful公司的数据副总裁华人Gloria Lau在她的演讲“A Tale of a Data-Driven Culture”中重点强调千万我们不要把招过来的数据科学家都最后培养成只会SQL的“猴子”了,而是需要让数据科学家集中在怎么样打造数据产品上来。
另外听了Solr、ElasticSearch与Spark融合的两个主题,一个是 Lucidworks的Timothy Potter,他是Solr的PMC成员,也是《Solr in Action》的作者,他分享的主题是“Integrating Spark and Solr”,发现Solr与Spark的融合更有效一些,特别是SolrRDD可以非常方便地让Spark从Solr里将数据读出计算,由于我问了两个跟Solr、ElasticSearch和Spark的问题,一个是Solr与ElasticSearch的区别,一个是ElasticSearch与Spark融合是否比Solr更好一些,当时他回答的有些简单,所以会后跟Timothy Potter在一个开源组里的日本人Taka Shinagawa主动来跟我解释沟通,如果仅是建索引,建议不需要用Solr或者ElasticSearch;另一个主题是Nube 公司的Sonal Goyal 分享了“Real Time Fuzzy Matching with Spark and Elastic Search”,她只重点说了模糊匹配和Spark的特点,其他分享没有多少干货(第二天的分享)。
Spark 1.4 Overview & Spark Committers Q&A
此外,在会议首日晚,Databricks还举办了Spark 1.4 Overview & Spark Committers Q&A,其中1.4重点更新如下:

图4: Databricks的Spark Committers回答用户问
1. Spark为应用提供了REST API来获取各种信息,包括jobs、stages、tasks、storage info等。
2. Spark Streaming 增加了UI,可以方便用户查看各种状态,另外与Kafka的融合也更加深度,也加强了对Kinesis的支持。
3. Spark SQL(DataFrame)添加ORCFile类型支持,另外还支持所有的Hive metastore。
4. Spark ML/MLlib的ML pipelines愈加成熟,提供了更多的算法和工具。
5. Tungsten项目的持续优化,特别是内存管理、代码生成、垃圾回收等方面都有很多改进。
6. SparkR发布,更友好的R语法支持。
最后,阿里明风的“Dynamic Community Detection for Large-scale e-Commerce data with Spark Streaming and GraphX”,还有Intel黄洁的“Towards Benchmarking Modern Distributed Streaming Systems”同样非常精彩,建议大家去搜索学习。
2015 Spark Summit 之我见——Day 2
在第2日Databricks联合创始人Reynold Xin(辛湜)的Keynotes中指出,Tungsten项目以大幅度提升Spark应用程序的内存和CPU利用率为目标,旨在最大程度上压榨新时代硬件性能。重点包括如下三方面:
1. 代码生成(Code generation):使用代码生成来利用新型编译器和CPU。
2. Binary Processing:利用应用的语义(Application Semantics)来更明确地管理内存,同时消除JVM对象模型和垃圾回收开销。
3. Cache-aware computation:使用算法和数据结构来实现内存分级结构(Memory Hierarchy)。
基于AdMaster当下也在重点发力移动端,因此我还重点听了InMobi公司的LBS实践(Building a Location Based Social Graph in Spark at InMobi),基本原理是用SSID作为点,把连接频率做边,通过使用连通图算法来实现。
第二天下午,Intel的伊里奇分享了“Taming GC Pauses for Humongous Java Heaps in Spark Graph Computing”:随着Spark的发展,JVM对大内存的管理也显得越来越重要,特别是垃圾回收,所以他重点介绍了GC的G1回收策略特点,同时还指出G1在1.8版本要比1.7版本性能要高出20%以上。
从本次峰会来看,业界对Spark已经有了一定的认可,Spark也被许多企业尤其是互联网企业广泛应用到商业项目中。同时,国内玩家在Spark上的影响力同样值得肯定,甚至有参会人员说到感觉这是一场中国人的技术峰会!
2015 Spark Summit 之我见——在Databricks聊实战
鉴于第三天的会议内容是实战培训,因此与AdMaster 创始人洪倍走进了Spark护航公司Databricks公司,就Spark应用和合作场景与Databricks的创始人Reynold Xin进行交流,其中有几点值得一提:
1. Spark与Flink的区别。提到Flink,其最大的特点是与Hadoop 有着非常好的兼容,如可以支持原生的HBase的TableMapper和TableReducer,唯一不足是现在只支持老版本的MapRed方法,新版本的MapReduce方法无法得到支持。
2.Cascading的发展方向以及Spark怎么样兼容Cascading。Cascading是一个架构在Hadoop上的API,用来创建复杂和容错数据处理工作流。它抽象了集群拓扑结构和配置,旨在快速开发复杂的分布式应用,而不用考虑背后的MapReduce原理。
3.就AdMaster用户行为的增量统计算法如何通过Spark快速实现并提高效率进行了深入探讨, 算法举例:
在 2013.1.1-2013.11.30 这一时间段,有 U1、U2、U3、U4 这四个用户,他们每天对广告的浏览情况如下图所示,数字代表当天的访问次数。
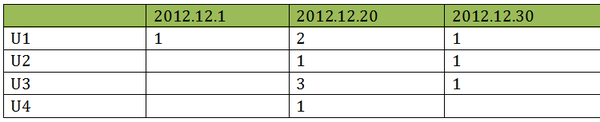
由上表可知,在这个时间段内,U1 浏览广告共 4 次,次数为 4;U2 浏览广告 2 次,次数为 2;U3 浏览广告共 4 次,次数为 4;U4 浏览广告 1 次,次数为 1。整理后,整个项目的次数分布情况如下图所示:

这里算法最大的复杂度就在于每天需要把以前的全部数据和当天的数据做联合查询,而查询条件又分很多维度。
Reynold最后建议我们等7月底推出对join操作进行的版本,届时测试后再进行更加详细沟通。

卢亿雷
AdMaster技术副总裁,资深大数据技术专家。关注高可靠、高可用、高扩展、高性能系统服务,关注Hadoop/HBase/Storm/Spark/ElasticSearch等离线、流式及实时分布式计算技术。