12月22日,北京奥维云网大数据科技股份有限公司(AVC)在其主办的“2015智慧家庭大数据年会暨奥维大数据产品发布会”上展示了其大数据与智慧家庭技术相结合的阶段成果,并解析了其智慧家庭产品线背后的大数据技术架构。
奥维云网认为,智慧家庭产业的核心是物联网和O2O,硬件设备搭载计算机技术、传感技术、触摸技术、人机交互技术等成为物联网中的一体化智能终端。智慧家庭产业化的核心是大数据资源及其挖掘,奥维云网基于Hadoop、Spark、Kafka以及Mesos+Docker的架构来实现大数据的管理、挖掘和应用。
智慧家庭技术路线
奥维云网此次发布的智慧家庭产品涵盖供应链优化、产品指南、价格管理、市场行情等多个维度,奥维云网总裁文建平表示,这些产品的背后是奥维云网积累的大数据资源及数据挖掘、人工智能技术——奥维云网一直从事大量数据的采集、清洗、挖掘和应用输出,目前底层数据库已经覆盖了1100多个字段,可以满足精细的数据画像要求。
奥维云网曾提出基于智慧家庭模式下的用户行为数据采集,并已持续投入资金资源向垂直领域大数据应用服务转型。清华大学数据科学研究院邱东晓认为,大数据更好地描述宏观和微观,提供更个性化的产品和服务,而智慧家庭相关的数据应该是中产阶级家庭生活场景下用的数据。中国科学院计算技术研究所高级工程师程伯群表示,终极的“智造”,是生产制造的每一个环节都不能离开数据,这涉及借助传感器、采集器、网络实现的数据采集、传输、预处理、存储、分析,数据平台的安全、开放。
在《中国智慧家庭大数据产业化实践白皮书》的解读中,奥维云网董事长喻亮星表示,大数据能给智慧家庭带来三个方面的变革:
- 产品功能和应用价值的改变。家庭应用场景下的智能硬件设备已日益成为一个载体,搭载着计算机技术、传感技术、触摸技术、人机交互技术等最新科技,成为了物联网中不可缺少的一体化智能终端;智慧家庭产品广泛应用于在线购物、在线教育、在线游戏、在线音乐、健康助手等不同场景中。
- 管理和盈利模式加快重构。受到互联网企业进军智能电视领域影响,产业管理模式及盈利模式加速变革,由制造业向“制造业+服务业”演进。
- 行业重心从产品创新向生态创新构建过渡。下一代创新模式是打破产业边界、打破组织边界,进入生态创新发展模式,智慧家庭领域包括智能电视厂商,都在释放跨界创新潜力,这样才可能产生核变效应,才能产生全新价值。
他认为,智慧家庭产业的核心是物联网和O2O,同时打破原来产业间的界限,把传统产业、电子信息产业、互联网产业进行有机地融合,通过跨界融合来推进智慧家庭产业的落地。中国智慧家庭大数据应用处于萌芽阶段,在产业化过程中,大数据将是核心资源,各类泛互联网公司,将会发挥数据能力优势,助力价值变现;业务洞察和精准营销将是行业大数据的应用重点,而大数据企业的商业模式也将从2B转向2C。
对于智慧家庭大数据产业化,奥维云网提出了3个建议:
- 解决数据共享难题,促进大数据运营产业发展;
- 深度挖掘数据价值,推动企业决策向数据驱动转变;
- 专注细分领域创新,提供有行业特色的专家级方案。
奥维云网智慧家庭大数据战略愿景如下图所示。本次发布的大数据产品,主要是真正和智慧家庭密切相关的,以智慧家庭为基础的用户数据。这方面奥维云网以智能电视为切入点,实时了解用户的行为习惯,根据用户的行为和习惯推出精准营销模式。
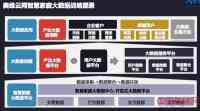
奥维云网智慧家庭大数据平台
奥维云网助理总裁韩昱具体介绍了奥维云网大数据产品。他表示,奥维云网大数据团队的努力包括大数据管理、大数据挖掘和大数据应用三个层面。
大数据挖掘是最核心的价值所在,这种价值体现在基于对业务场景的理解去做建模和算法。在两年多的时间里面,奥维云网大数据团队致力于理解各种业务场景,并构建了一整套的模型算法,吸纳了SVM、KNN、BP、RMF、EM、K-Means、LDA、贝叶斯、随机神经网络、决策树、协同过滤、回归分析等不同的模型算法。

基于这些算法和收集的数据,奥维云网提供产品智能、价控卫士、评价管家、市场罗盘等智慧家庭企业智能决策支持功能。例如,借助对价格的实时监控及预警机制,可以监管电商渠道的乱价行为;采集、分析用户评论、利用自然语义词库与行业专业词库,通过NLP技术精准识别差评,实时追踪差评处理情况,为企业提高电商销量、考核客服提供数据依据。
奥维云网大数据技术架构
奥维云网首席技术执行官巫新宇解析了实现其大数据管理、挖掘和应用的技术架构。奥维云网采用当前热门的Hadoop、Spark数据平台技术,以及流行的大数据管理工具,对奥维的大数据平台相关的数据进行管理和处理。
他从数据采集、流式处理、数据存储、离线数据计算、数据挖掘和服务聚合等六个方面对奥维云网针对大数据场景中的问题所使用的技术进行讲解。
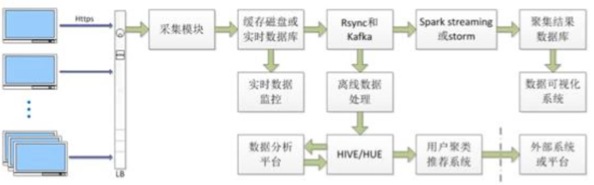
数据采集:奥维云网数据是来自于互联网(社交平台+电商平台)的流式数据和关系型数据,数据采集平台大概有三百个节点,是基于云端VPS的分布式采集系统,用Python来实现。由于电商平台对各种采集系统的封锁非常厉害,奥维云网自己搭建了代理池,协助采集程序突破封锁,抓取到电商平台上不太好抓取的信息,这是近一段时间主要做的工作。
流式处理:数据采集到以后,对数据实时进行处理。价格监控以及下面所有采集终端的数据,都会通过这套流程处理系统,对这种数据进行聚合。目前基于Kafka队列,使用Spark Streaming进行秒级的数据计算,把相应的计算结果存储在流行的HBase列式数据库中。对家庭采集终端,使用多数据中心多级汇聚技术,进行分布式处理,然后统一地向数据中心节点进行汇聚,以保证采集数据的时效性以及准确性。
数据存储:数据经过流程处理汇聚到数据中心之后的数据存储,涉及分布式存储、列式存储、关系存储、缓存存储,原始文件存储在HDFS分布式存储系统上,聚合数据存储在HBase,传统关系型数据存储于MySQL,中间结果、日志、视图则存储在Redis缓存上。现在智能终端每天都有很多数据上来,需要用缓存保证所有处理后的数据可以查询和使用。
离线数据计算:奥维云网用Spark进行离线数据计算,目前已经升级到1.5版本,并使用Dataframe API重写相关Job,目前已经运行稳定。奥维云网还整理了自己的用户定义函数AVC-UDFs,以便在处理公共逻辑的时候可以重复用。
数据挖掘:数据处理完以后,要通过数据挖掘产生价值,数据挖掘人员主要是用R语言在本地对算法进行验证,然后通过Spark ML将R实现的算法转换成模型,形成挖掘系统,供决策使用。R语言的开发人员,都有很多年的行业经验,能够快速将抽样数据转成模型。
服务聚合:数据挖掘结果的发布,奥维云网把所有的业务都进行了封装,基于Docker和Restful的微服务架构,使用OAuth统一验证登录系统支撑奥维云网所有对外的访问、控制。目前研发团队还正在数据中心推进基于Mesos的服务动态资源调度,目前设想是部署在大约20台裸机上。
快速交付:因为开发和迭代的速度非常快,需要使用快速交付的工具,奥维云网使用了基于Jenkins的服务自动发布,基于Hue的大数据可视化,以及基于NodeJS的前端自动化技术,以保障服务的快速交付。
技术栈的选择,核心是看应用场景的需求。巫新宇认为Storm比Spark Sreaming更快,但选择Spark及Spark Sreaming技术栈,是因为Scala,之前已经使用Play Framework实现非阻塞、大并发。而从Spark 1.3升级到Spark 1.5,他最看重的是SparkSQL,这让团队可以重拾之前的SQL技能,很方便地与现有的Hive、MySQL、HDFS数据对接,基于MapReduce的开发更加困难,尽管Impala可以满足基本的快速查询的需求。当然Spark需要注意的是内存的使用,因为抽象程度更高,比MapReduce更加不容易控制,如果程序写不好,可能一个迭代之下内存就挂了。
微服务架构、CI的采用,让大屏、手机不同的终端有一个统一的发布后台,但需要搞定Restful,目前逐渐成熟,这些设计思想来自于巫新宇加入奥维云网之前的工作经验以及社区的交流。调度之所以选择Mesos而不是Kubernetes,是因为认为Mesos的开源更加彻底。