9月29日20:30-21:30,世纪佳缘算法工程师杨鹏在CSDN人工智能用户群分享了“世纪佳缘推荐和机器学习算法实践”。他主要介绍了基于图算法产生候选集、排序算法的选择,以及建模过程中的一些经验心得。
以下为杨鹏分享实录:
大家好,我叫杨鹏,来自世纪佳缘算法组,主要关注于推荐和机器学习方面。我今天分享一下世纪佳缘在推荐方面的尝试和心得。
世纪佳缘推荐场景
先说一下我们的推荐场景。我们使用推荐的场景跟电影、商品推荐有很大的不同,商品的推荐可能只考虑到转化就可以了,我们要考虑推荐链的更长一些。
我们的情况:用户登录网站,算法推荐出用户可能感兴趣的人,用户发信,收信用户看信。最大的不同点在于,我们的item也是人,设计算法时也要考虑item的感受。
拿亚马逊来类比,亚马逊可能只需要考虑把一本书推荐给某个人,我们还要考虑这本书是不是想被推荐给这个人。举一个极端的例子,如果我们只是想提高男性用户发信,我们只需要给所有人推荐美女,这样发信量一定会暴涨。但是这样做会引发很多问题:1)美女一天不可能读上千封信;2)美女对于一些条件不好的男性根本没兴趣;3)非美女收不到信。
所以无论是在产生候选,还是在排序的时候,我们都要同时考虑user和item。
以上是我们在推荐场景上比较特殊的地方。
基于图算法产生候选集
下面我主要说两个主题,先说我们如何产生推荐。今天主要说一下基于图的算法,我们的图算法是在Spark上实现的,使用用户历史发信数据,计算得到用户的推荐列表。(世纪佳缘对Spark的理解,可以参考这个文档:世纪佳缘吴金龙:Spark介绍——编辑注)
我们的数据很稀疏,在图算法中,对于数据比较多的用户使用一跳节点,对于数据少的用户使用二跳甚至三跳节点的数据,这样可以避开CF中计算相似度的问题,对数据少的用户也能产生足够多的推荐。
当时遇到的主要问题是数据:一是数据太大,二是数据质量不高。
对那些出度(发信)和入度(收信)很多的点都要想办法进行抽样,否则会在计算时会耗尽内存。抽样时也尽量提高数据质量。
对于收信很多的用户,抽样方法很简单,留下用户看了的信,去掉没看过的。对于发信的抽样,当然也可以只留下被看过的信,但是种方法有一点讲不通,因为看不看信是站在item的角度考虑的,对发信抽样,应该站在user的角度。
我们尝试了直接扔掉发信过多的用户,随机抽样,保留最近数据几种方法。但是这样的方法都是很盲目的。对于发信而言,最主要的度量应该是:发信那一刻,用户是不是认真的。如果用户发信是很随意的,没有经过筛选,那这个数据其实没有多大意义。
解决这个问题当然也可以做个模型,但是太复杂了,我们使用了一种简单的方法:根据用户的发信间隔判断,比如这封信与上一封信时间间隔10s以上,我们就认为用户在用心的发信,保留这个数据,否则扔掉。方法很简单,但是最终线上的效果却很好。
我取了一个发信很随意的用户数据,统计了收信人在某个维度的分布,如下图所示。
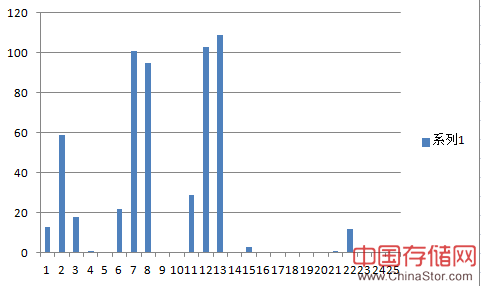
以下则是一个认真发信的用户,判断标准就是刚才说的时间间隔。
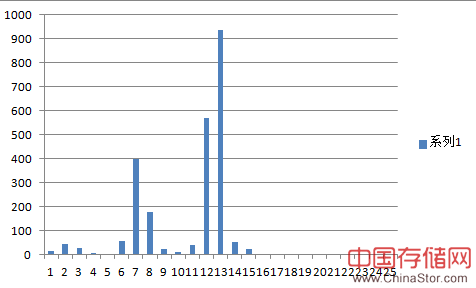
可以明显看出来,认真发信的用户,只给符合自己要求的人发信,所以分布会更集中一些。但是不认真的用户,分布就很散了。
排序算法的实现
第二个主题,说一下排序。主要是对上边产生的候选集排序后把最终结果展示给用户。用到的算法也是CTR预测中常用到的LR、FM、GBDT等。
前边说过,我们除了要考虑user发信,还要考虑item会不会看信,甚至item会不会回信。
因此一次排序通常会组合好几个模型:点击模型预测user从展示里点item的概率,发信模型预测发信概率,读信模型预测item读信概率。然后对这几种概率做个组合后得到最终的权重值。
用到的工具,数据怎么处理,都跟大家一样,没什么要说的,这里重点提一个我们用到的评估方法。
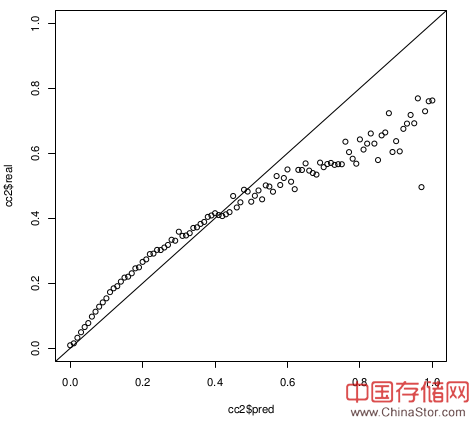
大致就是上图这条曲线,横座标是预测概率的一个区间,纵座标是在这个区间内真实值的平均。比如图中(0.45, 0.46)的点,计算方法是:
- 取所有预测值在[0.445, 0.455)的真实值,记为X;
- avg(X)为纵座标值;
这条曲线最完美的情况应该是只有(0, 0),(1, 1)点有值,当然算法不可能做到这样。次好的情况,画出来的线应该与 y=x 重合。
之前说过,我们的排序是把多个算法出来的概率值作组合,所以对每个算法的效果除了要求排序正确,还希望预测的概率值也尽量接近真实值。
ROC、NDCG可以很好的度量排序,但是没法度量真实值与预测值的偏差,这就是为什么我们特别关注这条线。
经验心得
最后说一下我们几次算法尝试时遇到的问题。
1.测试Facebook论文中提到的用GBDT提取特征的方法。
当时为了方便,我们直接把给LR的特征作为GBDT的特征,然后把得到的叶子节点作为特征,与原来的特征组合到一起再扔给LR。(可以参考这篇博客:CTR预估中GBDT与LR融合方案——编辑注)
线下效果和线上效果都有提升,我们推广了这个方法,但是发现其中一个模型没有任何效果。
排查问题的时候发现,这个模型对所有特征作了离散化,出来的特征值全部非0即1。GBDT本来就是个树模型,能很好的处理非线性特征,使用离散化后的特征反而没什么效果。而且对于这种只有0、1值的情况,GBDT出现了不收敛的现象。
2.不同的场景,使用不同的算法。
LR是我们最常使用的,所以在做点击模型时,自然也是先上了LR,但是线上效果并不好。后来上FM,效果却好的出奇。
如果登录过我们的网站,很容易发现原因:展示的场景,只能看到头像、地区、年龄等几个属性,LR使用了大量用户看不到的特征,这些特征对于模型来说是没有意义的。
That's all,我今天分享就到这里了。
Q&A
问:能否再详细介绍一下推荐系统所采用的工具?
答:R的话,我们主要用Liblinear;FM主要用SVDFeature;数据主要放Hive;Redis、Memcache和MongoDB都会用到;实时计算,会对接Kafka。
问:不实时计算可以吗?哪些方面是需要实时计算?
答:最主要的计算,还是离线算好的。比如实时的排序,因为推荐列表动态生成,排序只能做成实时的。
问:请问主要的算法用得什么语言开发的?
答:线上Java,线下的代码就很随意了,Python/Java/Shell/Hive,什么方便用什么。
问:做算法时,你觉的最大的障碍是啥?如何解决这些障碍?可以谈谈具体实现上遇到的一些困难。
答:很多时候,一个模型效果不好,但是却不知道从哪里着手改进。不知道加什么样的特征会有效,换模型也没有效果,试过了能想到的所有方法。
问:对数学要求高吗?
答:我自己主要做开发工作,数学有要求,但是不是那么高,能看懂论文就好。
问:杨老师,你们对用户的习惯有研究吗?如何做的?
答:用户习惯,我们主要会统计一些数据,比如用户经常给多少岁的人发信,然后把这个统计作为特征放到模型里。
问:请问下,在使用算法的过程中,对于对应算法的具体推演过程你们需要全部理解透么。感觉有时候一个算法对数学的要求好高啊,想理清缘由难度蛮大的。
答:不需要全部理解透,至少我看了很多遍EM的推导,现在推,我还是不会。但是我知道EM推导大概怎么回事。
问:一般你们怎么样从为解决某个问题,而选择需要利用哪些维度,然后出发去构建模型的?
答:这个主要还是个人经验,做的多了,很容易就能找到最有效的特征。
问:模型是基于已有的一些文章的还是在实验过程中改进的,有专门的算法部?
答:模型主要还是基于已有的,除非很不符合我们的需要,否则很少去改。
问:一些常用算法的推导,特性,用法都的知道吗?
答:常用算法肯定是要知道的。
问:杨老师,你刚刚学习的时候,从哪个简单示例或者文档入手的?
答:《集体智慧编程》。
问:能否介绍佳缘的推荐目前的实际效果,下一步的改进方向?
答:分算法和场景,整体上看,如果原来什么算法都没有,可能会有50%左右的提升。下一步的方向,主要是具体细分用户,或者从其它维度细分算法。之前的只关注了按场景细分,以后细分的维度会拓宽些。
问:请问您认为应届生应该怎样往机器学习方向发展呢?
答:环境是最重要的,如果真想做,找个真正做这个的公司。我一直想做游戏,到现在都没做成[Smile]。