上周(7月2日),我们有在CSDN Spark高端微信群通过圆桌的方式讨论了 Spark集群资源管理所面临的挑战,四位嘉宾带来了非常精彩的分享。而昨天(7月9日),为了更加深入集群的资源调度与管理,我们邀请了数人科技创始人王璞与数人科技云平台负责人周伟涛为大家就Mesos等主题进行了深入的分享,下面我们就一起回顾分享的内容与超过40分钟的QA讨论。
王璞,数人科技创始人。美国George Mason大学计算机Phd,擅长分布式计算、大规模机器学习、海量数据处理。曾担任 Google 广告部门数据平台构架师,参与分布式操作系统运维工具的开发。
周伟涛,数人科技云平台负责人。曾在Red Hat工作。Pythoner,对NLP,CI,Mesos和docker有丰富的实践经验。
周伟涛:基于Mesos的集群调度与管理(实录)
大家好,这里首先跟大家聊一些分布式系统的知识,然后说些我们搭建的Spark平台。分布式系统的原则: 可伸缩性, 没有单点失效, 高可靠性,数据本地性。 这是很常见的分布式系统的基本原则。这个大家可以参考王总以前的一篇 CSDN文章。
我们公司内部搭建了一套基于Spark、Mesos、Hue、HDFS 等开源技术的多租户,高可用的集群环境。大致的架构是这样的, 用户可以一键将Docker化的Zeppelin利用Marathon发布到Mesos集群,发布成功后,Zeppelin将自动注册成为Mesos集群的Scheduler,自由地使用Mesos集群的资源;然后用户就可以使用zeppelin 页面使用 spark进行数据计算。另外,数据是存储在HDFS中的,Mesos上的Spark与HDFS进行了绑定,Spark会无缝使用HDFS中的数据。同时我们在HDFS层对多租户的数据进行了权限设置,保证用户之间的数据是不可见的。这个功能是对Hue进行hack实现的。在新用户创建时强制改变HDFS的umask。简单介绍几个工具:
1.
Zeppelin是Apache正在孵化的一个Spark Notebook,在数据可视化方面方面做了很多工作。它对spark-SQL,R,Scala等语言都有支持,代码高亮等。
有与Mesos通信的接口。另外,我们team内部对Zeppelin做了些定制来使用它的ssl功能,并保证在我们集群对公网的服务发现。
2. Marathon,是Mesos的一个比较通用的scheduler,支持实例的横向扩展、rolling update、failover等,这样就保证了Zeppelin的高可用,同时它自身也可以通过zookeeper保证高可用。
3. Hue,是很常见的Hadoop工具大杂烩,这里就不多介绍了。
4. Mesos,其最大的好处是能够对分布式集群做细粒度资源分配,这里我会多介绍一些。贴一些王总总结的内容。
Mesos最大的好处是能够对分布式集群做细粒度资源分配。如下图所示,左边是粗粒的资源分配,右边是细粒的资源分配。

左边有三个集群,每个集群3台服务器,分别装3种分布式计算平台,比如上面装3台Hadoop,中间3台是Spark,下面3台是Storm,3个不同的框架分别进行管理。右边是Mesos集群统一管理9台服务器,所有来自Spark、Hadoop或Storm的任务都在9台服务器上混合运行。Mesos首先提高了资源冗余率。粗粒资源管理肯定带来一定的浪费,细粒的资源提高资源管理能力。
Hadoop机器很清闲,Spark没有安装,但Mesos可以只要任何一个调度马上响应。最后一个还有数据稳定性,因为所有9台都被Mesos统一管理,假如说装的Hadoop,Mesos会集群调度。这个计算资源都不共享,存储之间也不好共享。如果这上面跑了Spark做网络数据迁移,显然很影响速度。然后资源分配的方法就是resource
offers,是在窗口的可调度的资源自己去选,Mesos是Spark或者是Hadoop等等。
这种方法,Mesos的分配逻辑就很简单,只要不停地报告哪些是可用资源就可以了。Mesos资源分配方法也有一个潜在的缺点,就是无中心化的分配方式,所以有可能不会带来全局最优的方式。但这个数据资源缺点对目前来讲并不是很严重。现在一个计算中心资源贡献率很难达到50%,绝大部分计算中心都是很闲的状态。下面具体举例说明怎么用Mesos资源分配。
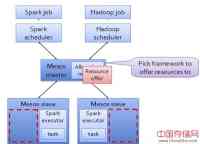
如图所示,中间是Mesos Master,下面是Mesos Slave,上面是Spark和Hadoop运行在Mesos之上。Mesos Master把可用资源报告给Spark或Hadoop。假定Hadoop有一个任务想运行,Hadoop从Mesos Master上报的可用资源中选择某个Mesos Slave节点,然后这个任务就会在这个Mesos Slave节点上执行,这是任务完成一次资源分配,接下来Mesos Master继续进行资源分配。我们在搭建这个平台时面临的挑战有很多,这里挑几个主要的跟大家分享下:
1. 为了保证多租户的feature,需要打通Hue,HDFS,Mesos集群之间的账号。我们首先开发了一个提供oauth验证的账号中心,同时为Mesos集群搭建了LDAP,账号中心的账号与LDAP中的账户一一map,而Hue的账户是需要使用账号中心的oauth认证的,同时使用过Hue的同学应该清楚,Hue新用户登录时会自动创建HDFS目录,这样,HDFS,Mesos间的账号打通了。同时marathon支持按不同的用户部署实例,这样,不同的用户部署自己的zeppelin,启动自己的spark
driver,访问自己的HDFS数据,全线贯通。
2. 其实我们前期是选择使用spark-notebook(scala play + highchart)来作为我们的spark web IDE的,但是,spark-notebook的一些状况与我们的需求不符,原因是notebook代码混乱,社区不活跃,spark-notebook是用scala play框架开发的,自己编译调试也挺费劲,同时spark-notebook是多租户,但是其多租户安全性不够,只能够满足团队内部的多租户,不符合我们的需求;而且,spark-notebook 的账号集成很难打通。而zeppelin是apache在孵化的项目,代码架构优雅(java+angularjs),单用户,我们为不同的用户启用不同的zeppelin,UI perfect。
3. Mesos集群资源混用的问题。我们的Mesos集群不仅运行spark这种无状态任务,也在运行着很多web服务等,但是Mesos不支持抢占,无法设置任务优先级,而spark默认是贪婪模式,这样就会出现spark运行时无法发布其他web任务到mesos集群上的情况。当前的解决方案是将Mesos集群静态划分,限制spark的运行范围。
4. 数据传输的网络资源问题。当前生产环境上的HDFS是架设在Mesos集群外的,但是spark与HDFS的数据传输量非常大,这就导致了Mesos集群的网络压力不可控。网络资源紧张。目前也没有太好的solution。team正在评估将HDFS集成到Mesos集群(非常困难)。
5. spark运行时的文件碎片。spark shuffle会在slave机器上产生大量的文件碎片,如果slave配置不够,就会直接导致机器inode 100%。为了提高文件系统性能,你需要修改你的spark config,将spark.shuffle.consolidateFiles设置为true。
6. spark在mesos上的资源占用有两种模式fine(细粒度)和coarse(粗粒度)。其中fine是default模式,按官方给出的文档,fine模式会提高资源利用率,但是在实际使用中我们发现,fine模式下,mesos集群有资源,spark仍然报资源不足,运行失败。而这时候改为coarse模式,问题就会消失。很古怪。
7. HDFS横向扩展问题。HDFS数据量上来之后,一个不可回避的问题就是加数据节点。由于我们崇尚小机器,多节点。HDFS节点配置都是2核2G,甚至一些是1核的,这在增加节点后的数据balance时就出现了HDFS name node被击垮的问题,内存不足。目前我们的解决方法是临时增加namenode的资源,在balance之后再把资源降下来。
8. 还有一个教训就是HDFS的datanode数据盘还是大一点比较好,好像HDFS对异构的datanode进行balance时,效果很差,数据根本没有推平。不知道别人有没有遇到这个问题。
QA——选集(篇幅做不到所有)
Q:Mesos在国内的生产环境部署情况如何,只局限于Spark。
王璞:Mesos在国内的企业用户还不少,爱奇艺、IBM、Intel等等都在用,其中爱奇艺的Mesos集群规模不小,他们最大的一个Mesos集群有400个节点左右,主要用于视频转码。
Q:Mesos设计的最大好处是可以提高资源利用率,业务扩展所容很高效,那能否兼容目前已有的服务呢?比如nginx、mysql、tomcat等?
周伟涛:无状态的比较好集成, nginx,tomcat。
Q:Mesos中部署无状态的服务,是使用Docker作为容器运行的吧?那是否只要Docker内可以解决的问题,都可以部署在Mesos中?
王璞:Mesos上运行nginx、tomcat这类web service应用没问题,我们一般把nginx或tomcat放到Docker里,然后由mesos调度运行。但是mysql这类有状态的存储类应用,目前mesos还支持得不好,Twitter刚开源了Mysos项目,把mysql跑在mesos上。
周伟涛:可以不用docker,mesos自身也有容器,cgroup隔离,都可以。
Q:目前mesos主要的应用场景有哪些?除了Jenkins。
周伟涛:Spark + Mesos; docker + mesos;saas or cass on mesos。
Q:zeppelin的使用有没有遇到扩展性的问题,我记得它是共享同一个sparkcontext?
周伟涛:有,我们是一个用户一个zeppelin。不是共享,这也是我们放弃spark-notebook的原因之一。
Q:YARN和Mesos有没有比较好的文章介绍它们之间的优劣的?
周伟涛:Mesos vs. YARN
- Mesos只负责offer资源给framework,而Yarn自己来分配资源。
- Yarn局限在Hadoop上了,没法作为别的机器管理。
- Mesos管理CPU,Memory,Disk;而Yarn只管理Memory和CPU。
- Mesos用lxc隔离,Yarn用进程(性能可能更好)。
Q:最近准备搭建分布式计算集群,请问自己搭建spark集群和直接使用数人的产品之间需要克服的困难有哪些呢?
周伟涛:自己搭建你需要读很多文档进行配置,然后,生产环境调优经验是关键。勤快人完全可以自己来。
王璞:用Mesos的好处是,部署Mesos以后,再跑Spark或Hadoop MapReduce的时候,就不需要部署Spark和Hadoop了,直接在Mesos上运行Spark或Hadoop任务。
Q:请问mesos和hdfs结合的难点在什么地方?
周伟涛:1. mesos不支持数据持久化;2. 网络隔离;3. 账户集成。
Q:方便说下hue集成ldap的详细么?我们也在考虑,rbac的调度。
周伟涛:hue的账户使用oauth验证,开发一个账号中心,账号中心同步LDAP账户。在详细的架构实现还真一言难尽啦。
Q:请问Yarn和mesos主要差别在哪里,为什么用mesos的很多,而用yarn的不多呢?
王璞:从功能上讲YARN和Mesos相似,只是Mesos更通用,可以支持在线和离线任务。一般YARN用于调度离线任务。
Q:关于spark-notebook与zeppelin,哪个更为看好?
周伟涛:我们前期跟了下spark-notebook社区,感觉只有andy一个人在搞,代码真心乱,版本控制有点儿差。zeppelin目前比较新,功能少,但是是apache孵化。
Q:是否有比较过有比较过ipython notebook和其他两个?
周伟涛:我比较过,前期也是受ipython notebook启发,才用spark notebook的,ipython notebook 配Pandas在数据可视化上也是不错的选择。
王璞:Zepplin和Spark notebook比起来,可能Zepplin更有希望吧,毕竟是Apache孵化的项目。
Q:mesos中的任务不存在抢占,没有优先级,如何实现服务自动扩容缩容呢?或者服务降级?
王璞:Twitter的Aurora支持任务优先级、任务抢占。
Q:服务所需使用的资源配置会受制于slave节点的配置吗?因为都是尽量使用低配的主机,如2核4G的,那如果服务需要更多资源,就需要人工评估资源使用率,从而决定启动多少个task吗?
王璞:肯定是。
直播&提问方式
1.扫码加入Spark微信讨论组2。(注:直接扫码加入已满,后续需要邀请加入。请大家先扫这个)

2. 加入CSDN Spark技术交流QQ群,群号:213683328。
3. CSDN Spark高端专家微信群,采取受邀加入方式,不惧高门槛的请加微信号“zhongyineng”或扫描下方二维码,PS:带上你的BIO。
