中存储网消息,近日,数据科学平台cnvrg.io简化了模型管理并将MLOps引入行业,它宣布与NetApp公司.建立合作关系,这是第一个利用cnvrg.io数据集缓存工具的工具,该工具集可立即从缓存中提取数据集的功能对于任何ML工作。

Cnvrg Netapp合作伙伴
该公司提供的是第一个使用数据集缓存进行端到端ML开发的ML平台。
缓存使数据集可以在几秒钟内即可使用,而无需花费数小时,并且缓存的数据集可以由连接到缓存数据的同一计算集群中的多个团队授权和使用。公司的客户已在生产级别使用数据集缓存。
拥有数百个数据集提供模型的情况并不少见。
但是,这些数据集可能远离训练模型的计算,例如在公共云或数据湖中。
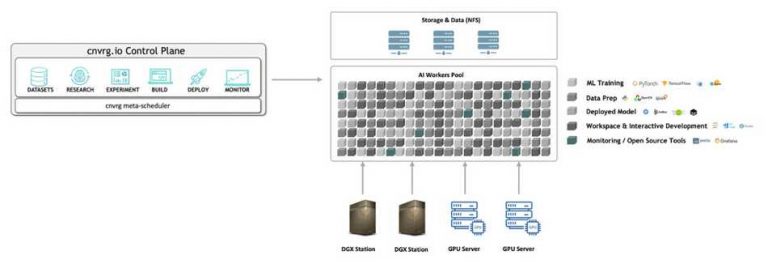
Cnvrg.io和Netapp的方案
借助NetApp和公司的数据集缓存功能,用户可以缓存所需的数据集(和/或它们的版本),并确保它们位于附加在进行训练的GPU计算群集或CPU群集的ONTAP AI存储中。缓存所需的数据集后,不同的团队成员可以多次使用它们。
该公司的数据集缓存功能可由ONTAP AI存储服务器的任何cnvrg.io用户使用。连接到组织后,数据科学家可以将其数据集的提交缓存在该网络文件系统(NFS)上。缓存提交后,用户可以将其附加到作业中以立即获得对数据的高吞吐量访问,并且该作业将不需要在启动时克隆数据集。
数据集缓存功能具有以下业务优势:
提高生产力 –可以立即使用数据集,而无需花费数小时。
改进的共享和协作 –缓存的数据集可以由连接到缓存数据的同一计算集群中的多个团队授权和使用。
降低成本 –模型正在从缓存中提取数据集,从而减少了每次下载的费用。
运营混合云 –数据集缓存提供了本地高性能镜像存储。
多云数据集移动性 –使用本地缓存作为数据的控制点。
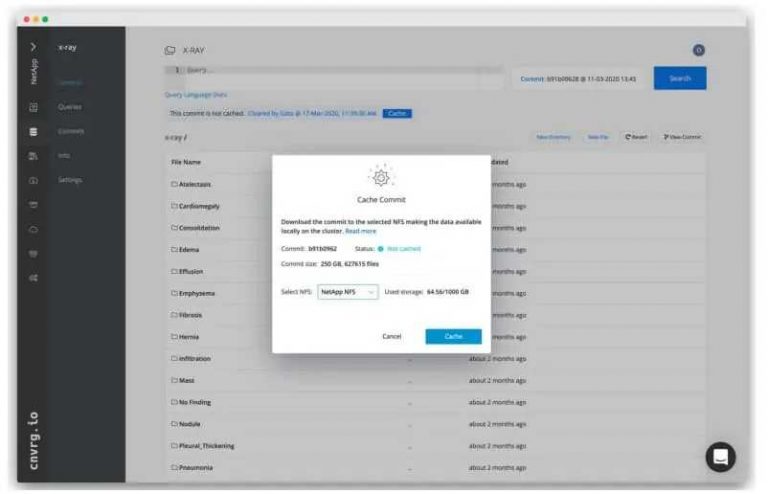
Cnvrg.io和Netapp
NetApp AI和数据工程高级技术总监Santosh Rao说:“ 深度学习工作负载是独特的,因为它们需要访问可能来自不同数据源和分散位置的大型数据集中的随机数据样本。” “ 此外,深度学习需要接近GPU计算集群的高性能数据,这需要结合高性能闪存存储系统,边缘,核心和云的连接器以实现分散的数据位置访问,并支持NFS广泛使用的数据源格式或统一数据平台上的其他文件系统。NetApp与cnvrg.io建立了首个同类合作伙伴关系,旨在通过深度学习来改变其业务,从而将这些功能带给全球客户。“
cnvrg.io首席执行官兼联合创始人Yochay Ettun说:“ 我们与NetApp的合作关系提高了数据团队的生产力和效率。“ 我们很高兴推出用于ML的数据集缓存,以便为NetApp用户和cnvrg.io用户提供更快,更简化的访问权限,并提供高级数据管理和数据版本控制功能的工具,使数据团队可以专注于数据科学技术复杂性。“
关于cnvrg.io:
这是一个AI操作系统,将企业管理,扩展和加速AI和数据科学开发的方式从研究转化为生产。代码优先平台是由数据科学家为数据科学家构建的,并提供了在本地或云上运行的灵活性。