MLPerf Storage 模拟各种真实的 AI/ML 工作负载。结果为评估 AI 存储架构的组织提供了相关数据参考。
结果摘要
在测试中,使用模拟的 H100 GPU 运行了 3D U-Net 基准测试。
注意:以前提交的和替代基准配置可以在 ML-Perf for Storage Benchmark Results 技术简报中找到。
3D U-Net 模拟医学图像分割工作负载。它是 MLPerf 存储基准测试中带宽密集型的,突出了并行 I/O 吞吐量以及内存和 CPU 效率。测试了三种配置,分别有 1 个、3 个和 5 个 Tier 0 节点。下表和图表总结了结果。
|
第 0 层节点数量 |
支持 H100 GPU |
总吞吐量 |
平均GPU利用率 |
变异系数 |
|
1 |
28 |
85.6 GB /秒 |
94.7% |
0.14% |
|
3 |
84 |
253.1 GB /秒 |
95.0% |
0.13% |
|
5 |
140 |
420.8 GB /秒 |
96.4% |
0.08% |
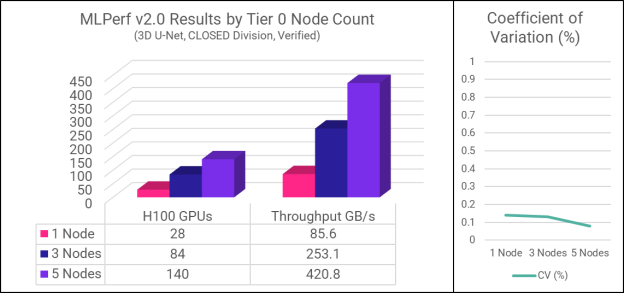
请注意,支持的 GPU 数量和吞吐量都会随着第 0 层节点数量的增加而线性扩展。这演示了主数据集可以 100% 驻留在主机上的最佳情况下的全部功能。随着集群规模的增长,峰值性能将取决于系统的配置和本地驻留数据的百分比,但聚合性能将继续扩展。这是我们性能测试团队需要进一步探索的领域。
平均 GPU 利用率表示 GPU 保持忙碌与等待的时间百分比。要“通过”MLPerf 存储基准测试,所有 GPU 必须保持在 90% 或更高的利用率。越高越好,因为目标是最大限度地减少 GPU 空闲时间。
变异系数 (CV) 是衡量同一测试的多次运行之间结果差异的度量。MLPerf Storage 基准测试要求每个测试运行多次,并且结果在很小的范围内。这确保了结果真正可重复。Hammerspace结果显示的极低CV表明系统性能非常稳定且可预测。
竞争比较 – 简单性和效率是关键
为确保有意义和公平的比较,以下讨论仅包括使用本地共享文件配置执行 3D U-Net H100 测试的供应商。此图显示了每个供应商在支持的 GPU 数量方面提交的最佳结果:

如您所见,Hammerspace Tier 0 取得了出色的成绩,在本次测试中击败了大多数家喻户晓的品牌。但还有另一种方法来看待这些数据,它具有令人难以置信的启发性和相关性——通过效率的视角。
世界各地的数据中心都缺乏电力、冷却,而且通常还缺乏机架空间。人工智能及其耗电的 GPU 服务器放大了这个问题。专用于存储基础设施的每一瓦都是 GPU 所不具备的。简而言之,效率很重要。
MLPerf Storage 提交的实际功耗信息不可用,但我们可以使用 rack U 作为代理,假设解决方案需要的 rack U 越多,它使用的功率就越多。

当您查看每个额外的存储基础设施机架 U 支持的 GPU 数量时,Hammerspace Tier 0 遥遥领先于其他系统,其结果是下一个最高效系统的 3.7 倍。
在现实情况下,GPU 服务器(此处由基准测试客户端表示)运行 AI 工作负载。“存储基础设施的额外机架 U”是指存储解决方案在计算服务器/基准测试客户端之外占用的额外空间。
由于第 0 层聚合集群中 GPU 服务器的本地 NVMe 存储,因此我们的基准测试运行所需的唯一额外硬件是单个 1U 元数据服务器,在 Hammerspace 中称为 Anvil。在生产安装中,通常运行两个 Anvil 以实现高可用性,但即便如此,Hammerspace 的效率也会比下一个最佳入口高 85%。
查看最大 GB/s 带宽揭示了类似的情况:Hammerspace Tier 0 的效率是下一个最近的入口的 3.7 倍。

基准配置
下面是测试配置的示意图:
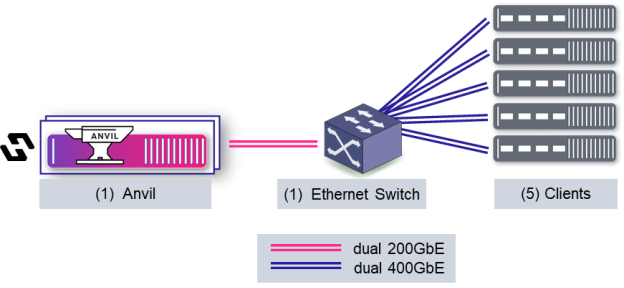
客户端运行基准测试代码。对于第 0 层,它们还容纳 NVMe 驱动器——在本例中,每个客户端 10 个 ScaleFlux CSD5000 驱动器。Anvil 负责元数据作和集群协调任务——没有数据流过它。客户端通过并行 NFS (pNFS) v4.2 挂载共享文件系统,在收到来自 Anvil 的布局后直接访问存储。
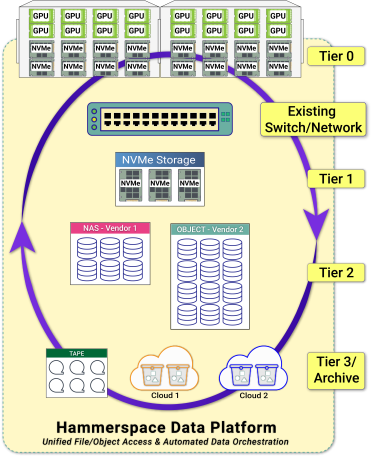
基准配置在其有限的范围内有点人为。通常,第 0 层只是更全面的 Hammerspace 基础设施中共享持久存储的众多层之一,该基础设施可能包括跨多个站点和云的网络附加第 1 层 NVMe、对象存储等。
为什么第 0 层对企业 AI
很重要 随着企业考虑 AI 计划,初始成本迫在眉睫。必须获取计算和存储资源,并且必须识别、清理和组织来自整个组织的大量数据。任何可以简化入门的东西都是有价值的。这就是为什么 MLPerf v2.0 Hammerspace 专注于我们的第 0 层实施。
Hammerspace Tier 0 激活 GPU 服务器集群中已经存在的 NVMe 存储,将其带入共享的全局命名空间。使用 Hammerspace 广泛的数据编排功能自动放置和保护数据。当租用比购买更有意义时,第 0 层甚至可以在云中工作。
对于数据整理的关键初始阶段,Hammerspace 的同化功能无需在优化之前将大量数据复制到全新的存储库中。同化通过扫描现有 NAS 卷的元数据将其带入 Hammerspace。数据本身保持原位。一旦识别并准备了相关数据,就可以将其动态编排到高性能存储(如第 0 层)上进行处理,最终将结果存档到成本较低的层。

Tier 0 for Enterprise AI
的优势 Hammerspace Tier 0 for Enterprise AI 的优势包括:
单纯:
- 开始使用已到位的存储和网络基础架构
- 无需安装代理软件
- 没有特殊的网络,只有以太网
性能:
- 第 0 层存储比网络存储快 10 倍
- 第 0 层提高了本地和云中的性能
- 提高 GPU 利用率、更快的检查点、减少推理时间
效率:
- 需要更少的外部共享存储
- 与外部共享存储相比,功耗、机架空间和网络更少
- 更快实现价值 – 在数小时内激活第 0 层,而不是数天或数周